【深度学习-图像识别】基于GhostNet进行ImageNet上1000类别的图像识别
GhostNet: MoreFeaturesfromCheapOperations
- (一)论文地址:
- (二)核心思想:
- (三)特征冗余:
- (四)传统卷积的问题:
- (五)Ghost Module for More Features
- (六)Ghost bottleneck:
- (七)实验结果:
- 联系我们:
(一)论文地址:
https://arxiv.org/abs/1911.11907
检测效果:
运行demo.py

(需要代码和模型权重的请私戳我哦,联系方式见文章末)
(二)核心思想:
作者为了进一步压缩 CNN 网络结构,提出了一个 Ghost module,其核心是通过简单的线性变换,在内在特征图的基础上,生成更多可以完全揭示内在特征信息的幽灵特征图(ghost feature map),从而以较小的计算代价生成更多特征;
作者提出的 Ghost module 可以看作一个即插即用组件,用于升级现有的卷积神经网络,其核心是在输出通道数不变的情况下,减小卷积层的通道数并采用一个线性变换来升维,以此减小参数;
同时作者也提出了一个 Ghost Bottleneck 模块用来堆叠 Ghost module,并以此构建了一个新的网络 GhostNet,实现了 75.7% top-1 准确率,在比 MobileNetV3 准确率还高的基础上,进一步压缩了模型;
(三)特征冗余:
在训练好的深度神经网络的特征图中,丰富甚至冗余的信息常常保证了对输入数据的全面理解;
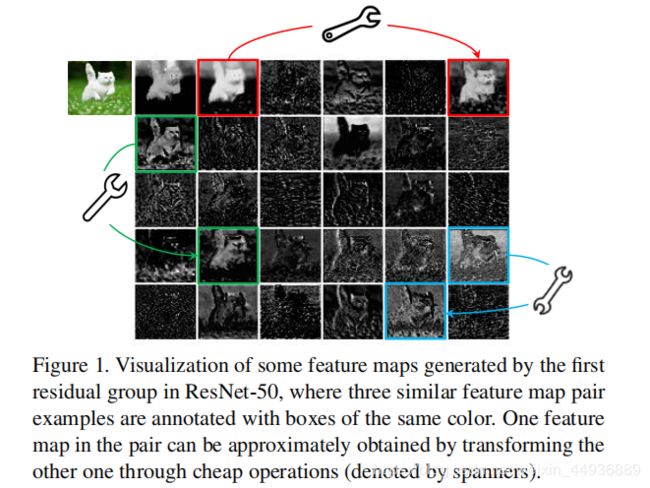
例如 ResNet-50,如果把特征图可视化,可以看到有许多相似甚至相同的特征图,就像彼此的幽灵一样;
作者认为这些相似的特征图并非冗余的,而是对检测和识别非常重要的,因此作者并没有去想办法去除这种冗余,而是采取了一种更为节省计算消耗的方式去生成这些幽灵特征图,由此搭建的网络就称之为——GhostNet;
(四)传统卷积的问题:
现在通用的一个减小卷积层参数的方法是 MobileNet 提出的深度分离卷积:
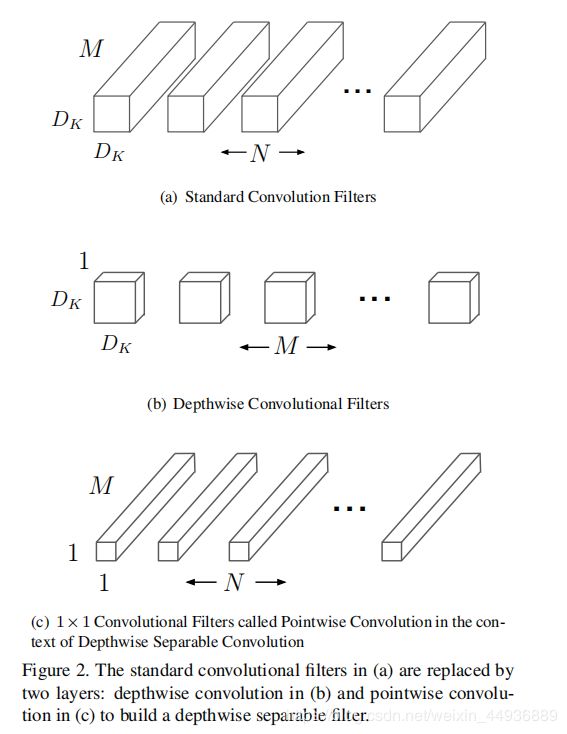
虽然深度分离卷积大大减小了参数量,但是随后用来升维或者降维并融合特征的 1×1 卷积仍然占用了客观的计算消耗和内存,生成的幽灵特征图也证明它有很大的改进空间;
针对这个问题,作者提出了可以减小卷积层使用的卷积核数目:
假设输入为 X ∈ R c × h × w X\in R^{c×h×w} X∈Rc×h×w,其中 c c c 为通道数, h , w h,w h,w 分别为特征图的高度和宽度;
那么任意卷积层生成 n n n 个 feature map 的操作就可以表示为:
Y = X ∗ f + b Y=X*f+b Y=X∗f+b
其中 ∗ * ∗ 是卷积操作, b b b 是偏置, Y ∈ R h ′ × w ′ × n Y\in R^{h^{'}×w^{'}×n} Y∈Rh′×w′×n 是输出的特征层, f ∈ R c × k × k × n f\in R^{c×k×k×n} f∈Rc×k×k×n 是卷积核,那么计算消耗 FLOPs 就是:
n × h ′ ⋅ w ′ ⋅ × c × k × k n × h^{'}· w^{'}·× c × k × k n×h′⋅w′⋅×c×k×k
然而对于通常情况下 n , c = 256 , 512 n,c=256,512 n,c=256,512,计算消耗会非常大;
作者提出,可以通过控制卷积核中 n n n 的大小来减小计算量,并通过一个简单的线性变换起到升维的作用;
(五)Ghost Module for More Features
这里作者简介了 Ghost Module,可以将其作为替换卷积层的模块;
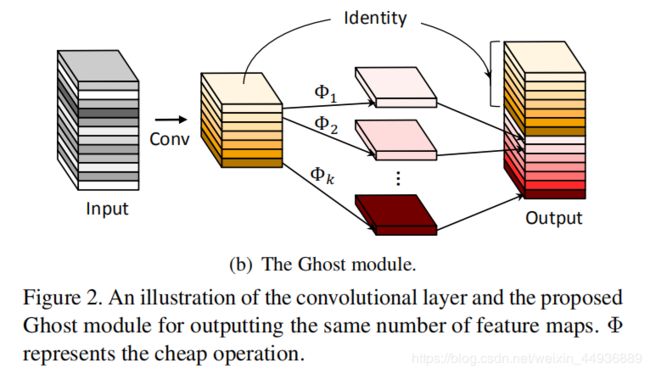
此时设置一个中间量 Y ′ ∈ R h ′ × w ′ × m Y^{'}\in R^{h^{'}×w^{'}×m} Y′∈Rh′×w′×m,其中 m < n m
这时: Y ′ = X ∗ f ′ Y^{'}=X*f^{'} Y′=X∗f′
其中偏执 b b b 被去掉,其他的超参数(如步长、卷积核大小)等保持不变;
此时再将 Y ′ Y^{'} Y′中的 m m m 个特征图分离,对每个特征图分别进行一次线性变换,使每个特征图生成 s s s 个幽灵特征图,用公式表示为:
y i , j = Φ i , j ( y i ′ ) , ∀ i = 1 , … , m , j = 1 , … , s y_{i,j}=\Phi_{i,j}(y^{'}_i),\forall i=1,…,m, j=1,…,s yi,j=Φi,j(yi′),∀i=1,…,m,j=1,…,s
其中 y i ′ y^{'}_i yi′ 是 Y ′ Y^{'} Y′ 的第 i i i 个特征图, Φ i , j \Phi_{i,j} Φi,j 是生成第 j j j 个幽灵特征图 y i , j y_{i,j} yi,j 的线性操作;
这样我们就得到了通道数为 n = m ∗ s n=m*s n=m∗s 的特征层 Y Y Y;
(六)Ghost bottleneck:
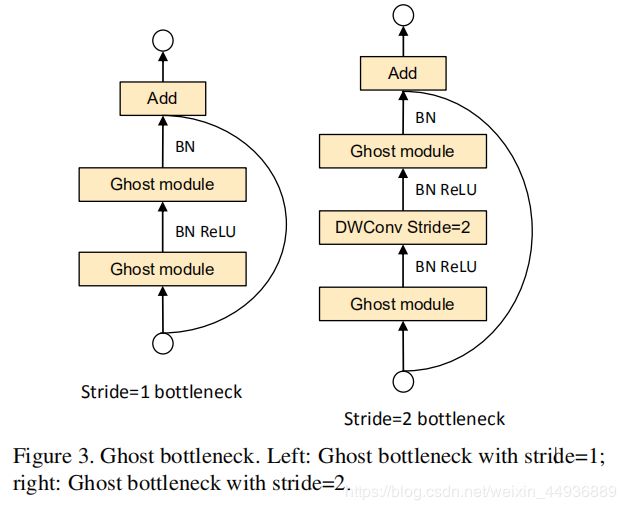
作者提出了两种 Ghost Module 的堆叠结构,主要是用来替换 ResNet 中的残差结构;
网络的整体结构如图:
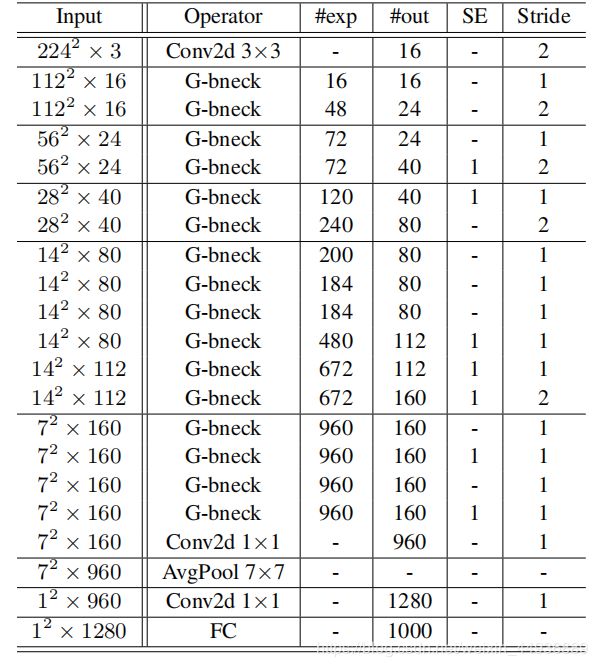
SE 表示是否使用 SE 模块;
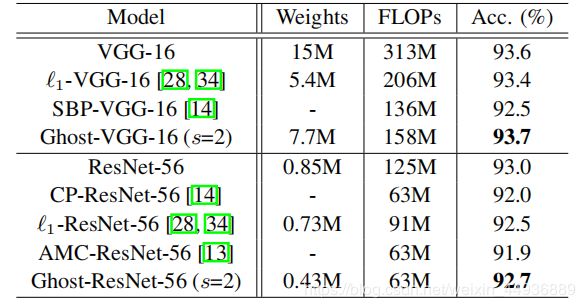
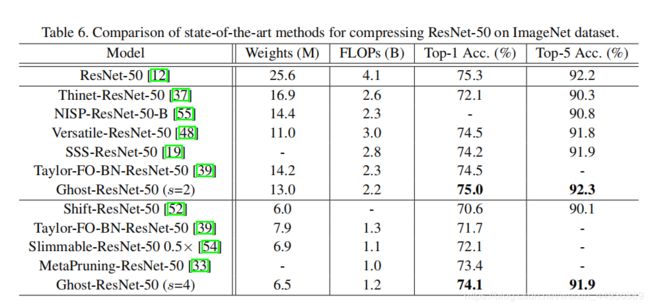
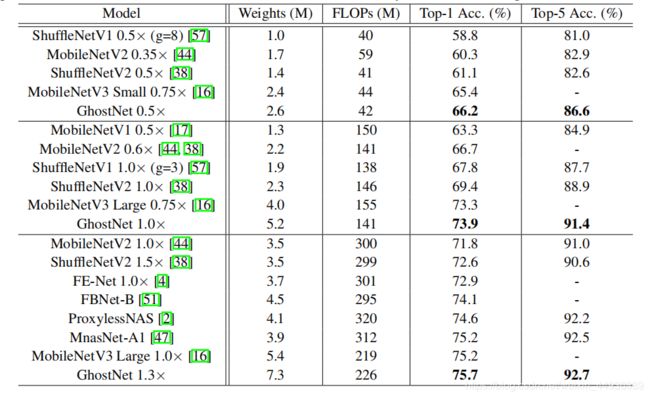
(七)实验结果:
联系我们:
权重文件需要的请私戳作者~
(长期接私活~)
