python实现Iris数据集的 Fisher线性分类及数据可视化实现
python完成Iris数据集的 Fisher线性分类
目录
- python完成Iris数据集的 Fisher线性分类
- 一、数据可视化
- 1、数据可视化定义
- 2、数据可视化基本概念
- 1)数据空间
- 2)数据开发
- 3)数据分析
- 4)数据可视化
- 3、数据可视化基本步骤
- 1)数据采集
- 2)数据分析
- 3)数据可视化
- 二、鸢尾花(Iris)数据集的 Fisher线性分类
- 1、导入并显示数据
- 2、数据集内鸢尾花含有花瓣和萼片的长宽信息图表
- 3、花萼长度与花萼宽度散点图
- 4、降维并显示属性关系3D图形
一、数据可视化
1、数据可视化定义
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
2、数据可视化基本概念
1)数据空间
数据空间是由n维属性和m个元素组成的数据集所构成的多维信息空间;
2)数据开发
数据开发是指利用一定的算法和工具对数据进行定量的推演和计算;
3)数据分析
数据分析指对多维数据进行切片、块、旋转等动作剖析数据,从而能多角度多侧面观察数据;
4)数据可视化
数据可视化是指将大型数据集中的数据以图形图像形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程。
数据可视化已经提出了许多方法,这些方法根据其可视化的原理不同可以划分为基于几何的技术、面向像素技术、基于图标的技术、基于层次的技术、基于图像的技术和分布式技术等等。
3、数据可视化基本步骤
1)数据采集
数据采集(DAQ或DAS),又称为“数据获取”或“数据收集”,是指对现实世界进行采样,以便产生可供计算机处理的数据的过程。
通常,数据采集过程之中包括为了获得所需信息,对于信号和波形进行采集并对它们加以处理的步骤。数据采集系统的组成元件当中包括用于将测量参数转换成为电信号的传感器,而这些电信号则是由数据采集硬件来负责获取的。
2)数据分析
数据分析是指为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
数据分析的类型包括:
1)探索性数据分析:是指为了形成值得假设的检验而对数据进行分析的一种方法,是对传统统计学假设检验手段的补充。该方法由美国著名统计学家约翰·图基命名。
2)定性数据分析:又称为“定性资料分析”、“定性研究”或者“质性研究资料分析”,是指对诸如词语、照片、观察结果之类的非数值型数据的分析。
3)数据可视化
将数据库中每一个数据项作为单个图元元素表示,大量的数据集构成数据图像,同时将数据的各个属性值以多维数据的形式表示,可以从不同的维度观察数据,从而对数据进行更深入的观察和分析。
二、鸢尾花(Iris)数据集的 Fisher线性分类
1、导入并显示数据
#导入相关库及数据
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
iris = datasets.load_iris()
data1=pd.DataFrame(np.concatenate((iris.data,iris.target.reshape(150,1)),axis=1),columns=np.append(iris.feature_names,'target'))
data1
部分数据集如下:
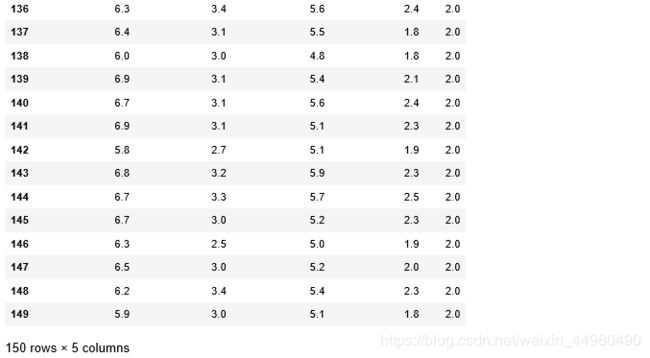
由图片可知,该数据集一共150行,每行5列
2、数据集内鸢尾花含有花瓣和萼片的长宽信息图表
data=pd.DataFrame(np.concatenate((iris.data,np.repeat(iris.target_names,50).reshape(150,1)),axis=1),columns=np.append(iris.feature_names,'target'))
data=data.apply(pd.to_numeric,errors='ignore')
data
sns.pairplot(data.iloc[:,[0,1,4]],hue='target')
sns.pairplot(data.iloc[:,2:5],hue='target')
程序运行结果如下:
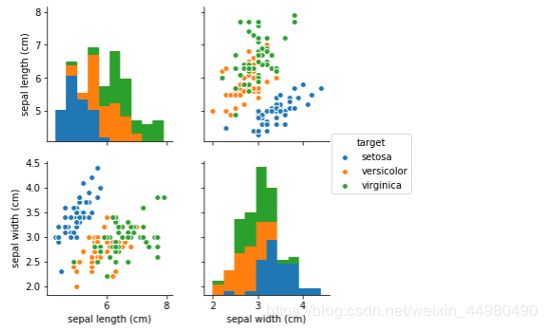
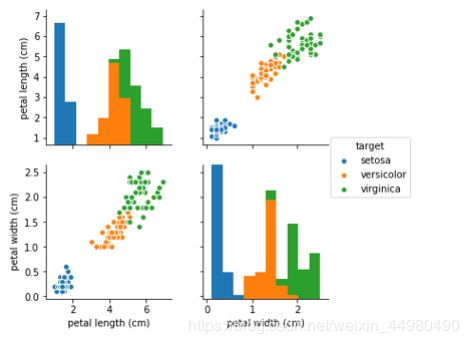
由图片可知,不同品种的鸢尾花,他的花萼长度、花萼宽度、花瓣长度、花瓣宽度都有一个相对固定的波动范围,且单个品种相关数据是聚集的。
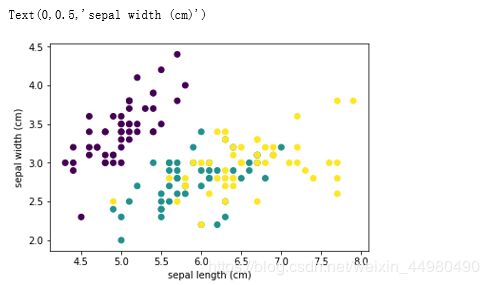
3、花萼长度与花萼宽度散点图
plt.scatter(data1.iloc[:,0],data1.iloc[:,1],c=data1.target)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
散点图显示如下:
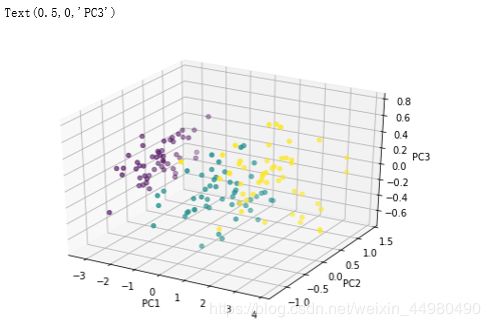
4、降维并显示属性关系3D图形
from sklearn.decomposition import PCA
x_reduced = PCA(n_components=3).fit_transform(data.iloc[:,:4])
x_reduced
fig=plt.figure()
ax=Axes3D(fig)
ax.scatter(x_reduced[:,0],x_reduced[:,1],x_reduced[:,2],c=data1.iloc[:,4])
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
降维显示3D图形如下: