支撑百万级并发,Netty如何实现高性能内存管理

Netty作为一款高性能网络应用程序框架,实现了一套高性能内存管理机制
通过学习其中的实现原理、算法、并发设计,有利于我们写出更优雅、更高性能的代码;当使用Netty时碰到内存方面的问题时,也可以更高效定位排查出来
本文基于Netty4.1.43.Final介绍其中的内存管理机制
ByteBuf分类
Netty使用ByteBuf对象作为数据容器,进行I/O读写操作,Netty的内存管理也是围绕着ByteBuf对象高效地分配和释放
当讨论ByteBuf对象管理,主要从以下方面进行分类:
- Pooled 和 Unpooled
Unpooled,非池化内存每次分配时直接调用系统 API 向操作系统申请ByteBuf需要的同样大小内存,用完后通过系统调用进行释放
Pooled,池化内存分配时基于预分配的一整块大内存,取其中的部分封装成ByteBuf提供使用,用完后回收到内存池中
tips: Netty4默认使用Pooled的方式,可通过参数-Dio.netty.allocator.type=unpooled或pooled进行设置
- Heap 和 Direct
Heap,指ByteBuf关联的内存JVM堆内分配,分配的内存受GC 管理
Direct,指ByteBuf关联的内存在JVM堆外分配,分配的内存不受GC管理,需要通过系统调用实现申请和释放,底层基于Java NIO的DirectByteBuffer对象
note: 使用堆外内存的优势在于,Java进行I/O操作时,需要传入数据所在缓冲区起始地址和长度,由于GC的存在,对象在堆中的位置往往会发生移动,导致对象地址变化,系统调用出错。为避免这种情况,当基于堆内存进行I/O系统调用时,需要将内存拷贝到堆外,而直接基于堆外内存进行I/O操作的话,可以节省该拷贝成本
池化(Pooled)对象管理
非池化对象(Unpooled),使用和释放对象仅需要调用底层接口实现,池化对象实现则复杂得多,可以带着以下问题进行研究:
- 内存池管理算法是如何实现高效内存分配释放,减少内存碎片
- 高负载下内存池不断申请/释放,如何实现弹性伸缩
- 内存池作为全局数据,在多线程环境下如何减少锁竞争
1 算法设计
1.1 整体原理
Netty先向系统申请一整块连续内存,称为chunk,默认大小chunkSize = 16Mb,通过PoolChunk对象包装。为了更细粒度的管理,Netty将chunk进一步拆分为page,默认每个chunk包含2048个page(pageSize = 8Kb)
不同大小池化内存对象的分配策略不同,下面首先介绍申请内存大小在 (pageSize/2, chunkSize] 区间范围内的池化对象的分配原理,其他大对象和小对象的分配原理后面再介绍。在同一个chunk中,Netty将page按照不同粒度进行多层分组管理:

- 第1层,分组大小size = 1*pageSize,一共有2048个组
- 第2层,分组大小size = 2*pageSize,一共有1024个组
- 第3层,分组大小size = 4*pageSize,一共有512个组
…
当请求分配内存时,将请求分配的内存数向上取值到最接近的分组大小,在该分组大小的相应层级中从左至右寻找空闲分组
例如请求分配内存对象为1.5 *pageSize,向上取值到分组大小2 *pageSize,在该层分组中找到完全空闲的一组内存进行分配,如下图:

当分组大小2 * pageSize的内存分配出去后,为了方便下次内存分配,分组被标记为全部已使用(图中红色标记),向上更粗粒度的内存分组被标记为部分已使用(图中黄色标记)
1.2 算法结构
Netty基于平衡树实现上面提到的不同粒度的多层分组管理
当需要创建一个给定大小的ByteBuf,算法需要在PoolChunk中大小为chunkSize的内存中,找到第一个能够容纳申请分配内存的位置
为了方便快速查找chunk中能容纳请求内存的位置,算法构建一个基于byte数组(memoryMap)存储的完全平衡树,该平衡树的多个层级深度,就是前面介绍的按照不同粒度对chunk进行多层分组:
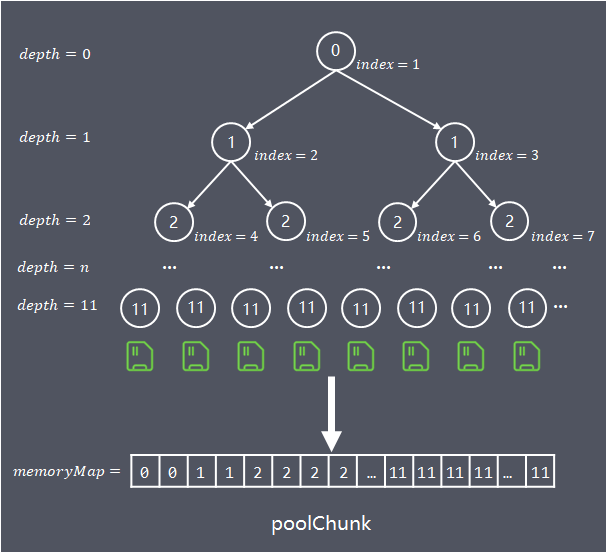
树的深度depth从0开始计算,各层节点数,每个节点对应的内存大小如下:
depth = 0, 1 node,nodeSize = chunkSize
depth = 1, 2 nodes,nodeSize = chunkSize/2
...
depth = d, 2^d nodes, nodeSize = chunkSize/(2^d)
...
depth = maxOrder, 2^maxOrder nodes, nodeSize = chunkSize/2^{maxOrder} = pageSize
树的最大深度为maxOrder(最大阶,默认值11),通过这棵树,算法在chunk中的查找就可以转换为:
当申请分配大小为chunkSize/2^k的内存,在平衡树高度为k的层级中,从左到右搜索第一个空闲节点
数组的使用域从index = 1开始,将平衡树按照层次顺序依次存储在数组中,depth = n的第1个节点保存在memoryMap[2^n] 中,第2个节点保存在memoryMap[2^n+1]中,以此类推(下图代表已分配chunkSize/2)

可以根据memoryMap[id]的值得出节点的使用情况,memoryMap[id]值越大,剩余的可用内存越少
- memoryMap[id] = depth_of_id:id节点空闲, 初始状态,depth_of_id的值代表id节点在树中的深度
- memoryMap[id] = maxOrder + 1:id节点全部已使用,节点内存已完全分配,没有一个子节点空闲
- depth_of_id < memoryMap[id] < maxOrder + 1:id节点部分已使用,memoryMap[id] 的值 x,代表id的子节点中,第一个空闲节点位于深度x,在深度[depth_of_id, x)的范围内没有任何空闲节点
1.3 申请/释放内存
当申请分配内存,会首先将请求分配的内存大小归一化(向上取值),通过PoolArena#normalizeCapacity()方法,取最近的2的幂的值,例如8000byte归一化为8192byte( chunkSize/2^11 ),8193byte归一化为16384byte(chunkSize/2^10)
处理内存申请的算法在PoolChunk#allocateRun方法中,当分配已归一化处理后大小为chunkSize/2^d的内存,即需要在depth = d的层级中找到第一块空闲内存,算法从根节点开始遍历 (根节点depth = 0, id = 1),具体步骤如下:
- 步骤1 判断是否当前节点值memoryMap[id] > d
如果是,则无法从该chunk分配内存,查找结束
- 步骤2 判断是否节点值memoryMap[id] == d,且depth_of_id == h
如果是,当前节点是depth = d的空闲内存,查找结束,更新当前节点值为memoryMap[id] = max_order + 1,代表节点已使用,并遍历当前节点的所有祖先节点,更新节点值为各自的左右子节点值的最小值;如果否,执行步骤3
- 步骤3 判断是否当前节点值memoryMap[id] <= d,且depth_of_id < h
如果是,则空闲节点在当前节点的子节点中,则先判断左子节点memoryMap[2 * id] <=d(判断左子节点是否可分配),如果成立,则当前节点更新为左子节点,否则更新为右子节点,然后重复步骤2
参考示例如下图,申请分配了chunkSize/2的内存
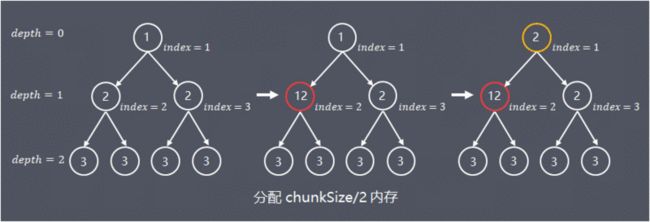
note:图中虽然index = 2的子节点memoryMap[id] = depth_of_id,但实际上节点内存已分配,因为算法是从上往下开始遍历,所以在实际处理中,节点分配内存后仅更新祖先节点的值,并没有更新子节点的值
释放内存时,根据申请内存返回的id,将 memoryMap[id]更新为depth_of_id,同时设置id节点的祖先节点值为各自左右节点的最小值
1.4 巨型对象内存管理
对于申请分配大小超过chunkSize的巨型对象(huge),Netty采用的是非池化管理策略,在每次请求分配内存时单独创建特殊的非池化PoolChunk对象进行管理,内部memoryMap为null,当对象内存释放时整个Chunk内存释放,相应内存申请逻辑在PoolArena#allocateHuge()方法中,释放逻辑在PoolArena#destroyChunk()方法中
1.5 小对象内存管理
当请求对象的大小reqCapacity <= 496,归一化计算后方式是向上取最近的16的倍数,例如15规整为16、40规整为48、490规整为496,规整后的大小(normalizedCapacity)小于pageSize的小对象可分为2类:
微型对象(tiny):规整后为16的整倍数,如16、32、48、…、496,一共31种规格
小型对象(small):规整后为2的幂的,有512、1024、2048、4096,一共4种规格
这些小对象直接分配一个page会造成浪费,在page中进行平衡树的标记又额外消耗更多空间,因此Netty的实现是:先PoolChunk中申请空闲page,同一个page分为相同大小规格的小内存进行存储
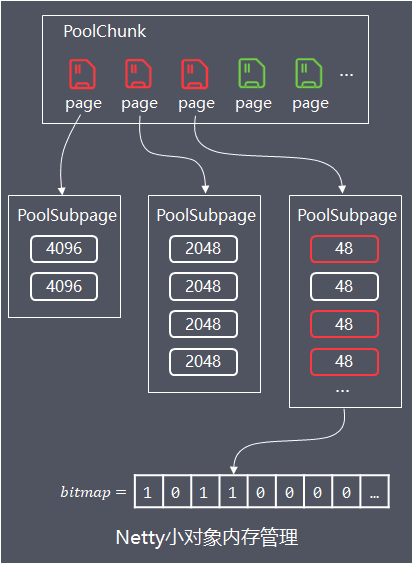
这些page用PoolSubpage对象进行封装,PoolSubpage内部有记录内存规格大小(elemSize)、可用内存数量(numAvail)和各个小内存的使用情况,通过long[]类型的bitmap相应bit值0或1,来记录内存是否已使用
note:应该有读者注意到,Netty申请池化内存进行归一化处理后的值更大了,例如1025byte会归一化为2048byte,8193byte归一化为16384byte,这样是不是造成了一些浪费?可以理解为是一种取舍,通过归一化处理,使池化内存分配大小规格化,大大方便内存申请和内存、内存复用,提高效率
2 弹性伸缩
前面的算法原理部分介绍了Netty如何实现内存块的申请和释放,单个chunk比较容量有限,如何管理多个chunk,构建成能够弹性伸缩内存池?
2.1 PoolChunk管理
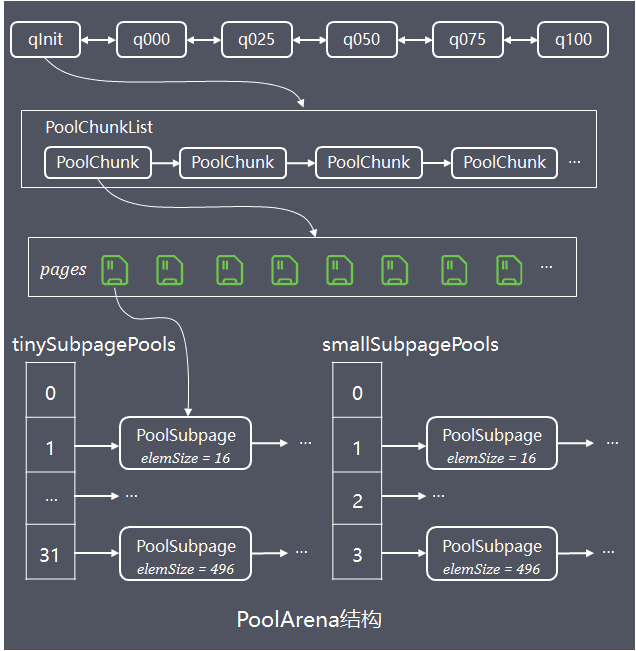
为了解决单个PoolChunk容量有限的问题,Netty将多个PoolChunk组成链表一起管理,然后用PoolChunkList对象持有链表的head
将所有PoolChunk组成一个链表的话,进行遍历查找管理效率较低,因此Netty设计了PoolArena对象(arena中文是舞台、场所),实现对多个PoolChunkList、PoolSubpage的管理,线程安全控制、对外提供内存分配、释放的服务
PoolArena内部持有6个PoolChunkList,各个PoolChunkList持有的PoolChunk的使用率区间不同:
// 容纳使用率 (0,25%) 的PoolChunk
private final PoolChunkList qInit;
// [1%,50%)
private final PoolChunkList q000;
// [25%, 75%)
private final PoolChunkList q025;
// [50%, 100%)
private final PoolChunkList q050;
// [75%, 100%)
private final PoolChunkList q075;
// 100%
private final PoolChunkList q100;
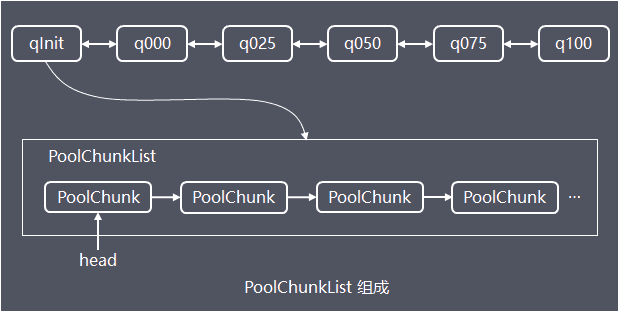
6个PoolChunkList对象组成双向链表,当PoolChunk内存分配、释放,导致使用率变化,需要判断PoolChunk是否超过所在PoolChunkList的限定使用率范围,如果超出了,需要沿着6个PoolChunkList的双向链表找到新的合适PoolChunkList,成为新的head;同样的,当新建PoolChunk并分配完内存,该PoolChunk也需要按照上面逻辑放入合适的PoolChunkList中
分配归一化内存normCapacity(大小范围在[pageSize, chunkSize]) 具体处理如下:
- 按顺序依次访问q050、q025、q000、qInit、q075,遍历PoolChunkList内PoolChunk链表判断是否有PoolChunk能分配内存
- 如果上面5个PoolChunkList有任意一个PoolChunk内存分配成功,PoolChunk使用率发生变更,重新检查并放入合适的PoolChunkList中,结束
- 否则新建一个PoolChunk,分配内存,放入合适的PoolChunkList中(PoolChunkList扩容)
note: 可以看到分配内存依次优先在q050 -> q025 -> q000 -> qInit -> q075的PoolChunkList的内分配,这样做的好处是,使分配后各个区间内存使用率更多处于[75,100)的区间范围内,提高PoolChunk内存使用率的同时也兼顾效率,减少在PoolChunkList中PoolChunk的遍历
当PoolChunk内存释放,同样PoolChunk使用率发生变更,重新检查并放入合适的PoolChunkList中,如果释放后PoolChunk内存使用率为0,则从PoolChunkList中移除,释放掉这部分空间,避免在高峰的时候申请过内存一直缓存在池中(PoolChunkList缩容)

PoolChunkList的额定使用率区间存在交叉,这样设计是因为如果基于一个临界值的话,当PoolChunk内存申请释放后的内存使用率在临界值上下徘徊的话,会导致在PoolChunkList链表前后来回移动
2.2 PoolSubpage管理
PoolArena内部持有2个PoolSubpage数组,分别存储tiny和small规格类型的PoolSubpage:
// 数组长度32,实际使用域从index = 1开始,对应31种tiny规格PoolSubpage
private final PoolSubpage[] tinySubpagePools;
// 数组长度4,对应4种small规格PoolSubpage
private final PoolSubpage[] smallSubpagePools;
相同规格大小(elemSize)的PoolSubpage组成链表,不同规格的PoolSubpage链表的head则分别保存在tinySubpagePools 或者 smallSubpagePools数组中,如下图:
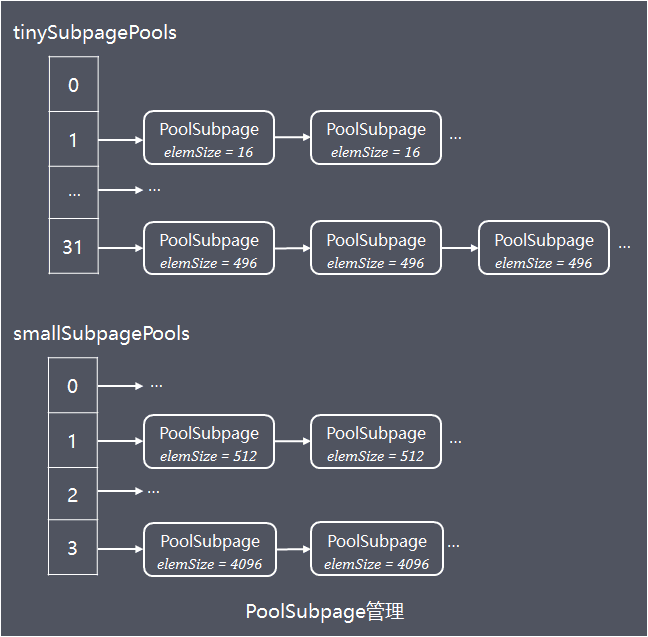
当需要分配小内存对象到PoolSubpage中时,根据归一化后的大小,计算出需要访问的PoolSubpage链表在tinySubpagePools和smallSubpagePools数组的下标,访问链表中的PoolSubpage的申请内存分配,如果访问到的PoolSubpage链表节点数为0,则创建新的PoolSubpage分配内存然后加入链表
PoolSubpage链表存储的PoolSubpage都是已分配部分内存,当内存全部分配完或者内存全部释放完的PoolSubpage会移出链表,减少不必要的链表节点;当PoolSubpage内存全部分配完后再释放部分内存,会重新将加入链表
PoolArean内存池弹性伸缩可用下图总结:
3 并发设计
内存分配释放不可避免地会遇到多线程并发场景,无论是PoolChunk的平衡树标记或者PoolSubpage的bitmap标记都是多线程不安全,如何在线程安全的前提下尽量提升并发性能?
首先,为了减少线程间的竞争,Netty会提前创建多个PoolArena(默认生成数量 = 2 * CPU核心数),当线程首次请求池化内存分配,会找被最少线程持有的PoolArena,并保存线程局部变量PoolThreadCache中,实现线程与PoolArena的关联绑定(PoolThreadLocalCache#initialValue()方法)
note: Java自带的ThreadLocal实现线程局部变量的原理是:基于Thread的ThreadLocalMap类型成员变量,该变量中map的key为ThreadLocal,value-为需要自定义的线程局部变量值。调用ThreadLocal#get()方法时,会通过Thread.currentThread()获取当前线程访问Thread的ThreadLocalMap中的值
Netty设计了ThreadLocal的更高性能替代类:FastThreadLocal,需要配套继承Thread的类FastThreadLocalThread一起使用,基本原理是将原来Thead的基于ThreadLocalMap存储局部变量,扩展为能更快速访问的数组进行存储(Object[] indexedVariables),每个FastThreadLocal内部维护了一个全局原子自增的int类型的数组index
此外,Netty还设计了缓存机制提升并发性能:当请求对象内存释放,PoolArena并没有马上释放,而是先尝试将该内存关联的PoolChunk和chunk中的偏移位置(handler变量)等信息存入PoolThreadLocalCache中的固定大小缓存队列中(如果缓存队列满了则马上释放内存);
当请求内存分配,PoolArena会优先访问PoolThreadLocalCache的缓存队列中是否有缓存内存可用,如果有,则直接分配,提高分配效率
总结
Netty池化内存管理的设计借鉴了Facebook的jemalloc,同时也与Linux内存分配算法Buddy算法和Slab算法也有相似之处,很多分布式系统、框架的设计都可以在操作系统的设计中找到原型,学习底层原理是很有价值的
服务推荐
- 蜻蜓代理
- 代理ip
- 微信域名检测
- 微信域名拦截检测
- 微信域名在线拦截检测工具
- 微信域名在线批量拦截检测工具