本周AI热点回顾:动森首届「AI 顶会」即将召开、《我的世界》里搭建神经网络、一位中国博士把整个CNN都给可视化了...

01
重要通知:动物森友会首届「AI 顶会」ACAI 2020即将召开
众所周知,因为疫情的原因,ICML、ICLR、CVPR 等人工智能顶级会议都已经改为了线上举办。
自从 AAAI 2020 之后,今年内大概率不会再有线下举办的 AI 会议了。比如这几天正在举办的 ICLR 2020,原本打算远赴非洲参会的人们,现在只能是网络一线牵。

正在线上举行的 AI 顶会 ICLR 2020 有一个口袋妖怪风格的虚拟环境「ICLR Town」,参会者在这个环境中的形象与视频会议几乎同步。
网络虚拟环境成为了人们持续交流的最重要途径。继网友在《我的世界》里盖学校、举办毕业典礼之后,AI 学术会议也挪到了游戏里。这次,他们看中的是 Switch 的「动物森友会」。这是个没有固定剧情的开放游戏,非常注重沟通,玩家可以在里面独自生活,不受默认的剧情、任务限制。
目前,动物森友会中的首届「AI 顶会」ACAI 2020 已经开始筹备,这一新生会议将在三个月后正式举行。
ACAI,顾名思义,就是 Animal Crossing Artificial Intelligence 的意思,虽然是在虚拟空间举办,但这场活动从规格、程序和人气上来看,和真正的学术会议相比也并不逊色。
这场 workshop 是由佛罗里达国际大学博士 Josh Eisenberg 组织举办的,他现在主要从事自然语言理解方面的研究,是手机游戏平台 Artie 的首席科学家。举办这场线上活动的目的是,让更多喜欢动物森友会的 AI 研究者聚集起来,在疫情期间保持顺畅的学术交流。
会议将在动物森友会里的小岛上举行,面朝大海,春暖花开。而实时音频、PPT 和虚拟会议空间将通过 Zoom 传递给每一个参会者。因为动森对于上岛人数的限制,并不是所有的参会者都聚集在一个小岛上。用于 Presentation 的主岛上会有 4 到 5 名观众,讲完一场后这些人会移到不同的「茶歇小岛」上去休息,然后下一场 Presentation 的人开始上岛准备。
大会官网:http://acaiworkshop.com/index.html
信息来源:机器之心
02
在《我的世界》里搭建神经网络,运行过程清晰可见
前有《我的世界》举办毕业典礼,后有《动物森友会》举办AI会议。最近《我的世界》又被大神带来了硬核玩法:
你如果是一个熟悉神经网络的人,想必已经猜出来了。
图片里这位玩家做的正是MNIST手写数字分类网络。
只需用剑在墙壁上画出数字,神经网络就能知道你写的是几。不仅仅如此,神经网络在推理过程中,哪些神经元被激活,都可以在这里看得一清二楚。
这个脑洞大开的玩家是一位来自印度的小哥Ashutosh Sathe,游戏项目叫做Scarpet-nn。
Sathe不仅放出了试玩视频,还开源了代码,如果你是《我的世界》玩家+神经网络炼丹师,那么你也可以把自己的网络放在游戏里。
Scarpet-nn支持卷积层和完全连接层,允许在单个世界中运行多个神经网络。而且可以展示中间张量的逐块激活,甚至还能一次运行多个神经网络。
我的世界里那一个个像素色块简直就是显示3维数组的神器。如果一个长方体的每个小块都用不同颜色来展示数值,那么一个长方体就可以表示一个张量。
BNN是一种高度简化的神经网络,权重和激活都只能取两个值:+1或-1。但是计算机中二进制的位表示是不同的。因此在BNN中,我们将+1存储为1为,将-1存储为0。在BNN中乘法运算就变成了逻辑门中的同或运算,而逻辑门在《我的世界》中可以用红石电路造出。至此,用《我的世界》搭建神经网络的理论基础已经完成。
Litematica下载地址:
http://minecraft.curseforge.com/projects/litematica
源代码:
https://github.com/ashutoshbsathe/scarpet-nn
信息来源:量子位
03
23个系列分类网络,10万分类预训练模型,这是飞桨PaddleClas百宝箱
图像分类是指根据图像信息把不同类别的图像自动区分开来,并能指出图像类别信息。此外图像分类技术在计算机视觉各类任务中堪称「基石」,这和人类的视觉方面的技能树点亮顺序很像。图像的辨识困难点主要有以下几点:
occlusion:识别目标被遮挡
scale:识别目标的尺度变化
deformation:识别目标变形
clutter:识别目标所处的背景嘈杂
illumination:识别目标所处环境的光照变化
viewpoint:拍摄识别目标的视角变化
object pose:识别目标的姿态变化
图像分类困难点(来源于:KristenGrauman,BastianLeibe,Visual Object Recognition)
为了解决上述这些困难,研究人员从数据增广、骨干网络设计、损失定义、优化器设计、模型压缩裁剪量化、模型可解释性、特征迁移学习等不同的角度对图像分类问题进行深入探索。飞桨图像分类套件 PaddleClas 是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas 具备以下 4 大特色,丰富的模型库、高阶优化支持、特色拓展应用、以及工业级部署工具。下面将为大家详细分解。

丰富的模型库
由于学习率、学习率下降策略、batch_size、权重衰减、标签平滑、数据增广等超参选择和设定对分类效果影响很大,复现对齐一种分类网络结构往往非常具有挑战性。基于 ImageNet1k 分类数据集,PaddleClas 提供 ResNet、ResNet_vd、Res2Net、HRNet、MobileNetV3 等 23 个系列的分类网络结构的简单介绍、论文指标复现配置以及在复现过程中积累的训练技巧。同时,PaddleClas 还提供了与 23 个系列网络结构相对应的 117 个预训练模型,以及推理效果和性能评估。
高阶优化支持之SSLD 知识蒸馏方案
知识蒸馏是指使用教师模型 (teacher model) 去指导学生模型 (student model) 学习特定任务,保证小模型在参数量不变的情况下,得到比较大的效果提升,甚至获得与大模型相似的精度指标。此外该方案的最大的特点是可以帮助用户利用没有标注的数据对模型进行训练,提升模型效果。PaddleClas 提供了一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation)。使用该方案模型效果普遍提升 3% 以上。
详细的 SSLD 知识蒸馏方案介绍、核心关键点、实验细节以及方案使用请参考教程中高阶使用的知识蒸馏章节:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/distillation/index.html
高阶优化支持之八种数据增广方法
在图像分类任务中,图像数据的增广是一种常用的正则化方法,可以有效提升图像分类的效果,尤其对于数据量不足或者模型网络较大的场景。常用的数据增广可以分为 3 类,图像变换类、图像裁剪类和图像混叠类:
图像变换类是指对全图进行一些变换,包括 AutoAugment、RandAugment。
图像裁剪类是指对图像以一定的方式遮挡部分区域的变换,包括 CutOut、RandErasing、HideAndSeek、GridMask。
图像混叠类是指多张图进行混叠一张新图的变换,包括 Mixup、Cutmix。
PaddleClas 提供了上述 8 种数据增广算法的复现,以及在统一实验环境下的效果评估,如图 7 所示。该图展示了不同数据增广方式在 ResNet50 上的表现, 与标准变换相比,采用数据增广的识别准确率最高可以提升 1%。不要小看这 1%,如果应用到实际业务中,这可能就是多识别出几千几万张图片呢!
每种数据增广方法的详细介绍、对比的实验环境以及使用请参考教程中高阶使用图像增广章节:
https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/index.html
工业级部署工具
飞桨提供了一系列实用工具,便于工业应用部署 PaddleClas,包括 TensorRT 部署推理、移动端部署推理、模型服务化部署等等。而这些工具大都以图像分类为例,提供示例教程和进行优化。
教程中的实用工具章节请参见:
https://paddleclas.readthedocs.io/zh_CN/latest/extension/index.html
信息来源:飞桨PaddlePaddle
04
一位中国博士把整个CNN都给可视化了,可交互有细节都清清楚楚
一个名叫CNN解释器在线交互可视化工具,把CNN拆开了揉碎了,告诉小白们CNN究竟是怎么一回事,为什么可以辨识物品。
它加载了一个10层的预训练模型,相当于在你的浏览器上跑一个CNN模型,只需要打开电脑,就能了解CNN究竟是怎么回事。
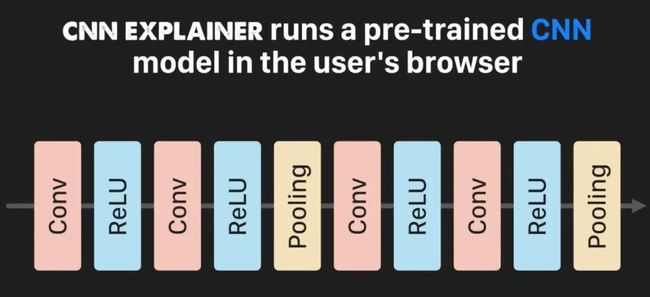
而且,这个网页工具还可以实现交互,只要点击其中任何一个格子——就是CNN中的“神经元”,就能显示它的输入是哪些、经过了怎样细微的变化。
甚至,连每一次卷积运算都能看得清。这个CNN解释器的使用方式也非常简单:鼠标戳戳戳就好了。
单击神经元,进入弹性解释视图,就可以看到卷积核滑动的过程的动画模拟:
点击一个正在卷积的过程图,就可以看到更具体的过程:
可以看到底层的卷积运算过程,3×3的卷积核是如何经过运算被变成1个数字的。
点击一个ReLU层的神经元,可以看具体过程,ReLU函数是这样工作的:

点击一个池化神经元,也可以看具体最大池化层是怎样工作的:

点击最右侧的输出神经元,进入弹性解释视图:
可以查看Softmax函数的详情:
最后,这个CNN解释器的作者是一位中国小哥,佐治亚理工的Zijie Wang,去年刚开始读机器学习博士,本科毕业于威斯康星大学麦迪逊分校,是一位GPA 3.95/4.00的大学霸。
信息来源:量子位
05
本周论文推荐
【ACL 2020 | PLATO】:百度发布首个大规模隐变量对话模型
PLATO: Pre-trained Dialogue GenerationModel with Discrete Latent Variable
作者:Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
论文介绍:

研发开放领域(Open-Domain)的对话机器人,使得它能用自然语言与人自由地交流,一直是自然语言处理领域的终极目标之一。
对话系统的挑战非常多,其中有两点非常重要,一是大规模开放域多轮对话数据匮乏;二是对话中涉及常识、领域知识和上下文,一个对话的上文(Context),往往可以对应多个不同回复(Response)的方向。PLATO 首次提出将离散的隐变量结合Transformer结构,应用到通用对话领域。通过引入离散隐变量,可以对上文与回复之间的“一对多”关系进行有效建模。
同时,通过利用大规模的与人人对话类似的语料,包括 Reddit 和 Twitter,进行了生成模型的预训练,后续在有限的人人对话语料上进行微调,即可以取得高质量的生成效果。PLATO 可以灵活支持多种对话,包括闲聊、知识聊天、对话问答等等。而文章最终公布的在三个公开对话数据集上的评测,PLATO 都取得了新的最优效果。
尽管越来越多的工作证明了随着预训练和大规模语料的引入,自然语言处理领域开启了预训练然后微调的范式。在对话模型上,大规模预训练还处于初级阶段,需要继续深入探索。PLATO 提出的隐变量空间预训练模型,可能成为端到端对话系统迈上一个新台阶的关键点之一。
论文地址:
https://arxiv.org/abs/1910.07931
预训练模型及代码:
https://github.com/PaddlePaddle/Research/tree/master/NLP/Dialogue-PLATO
END
