深度森林(Deep Forest)是周志华教授和冯霁博士在2017年2月28日发表的论文《Deep Forest: Towards An Alternative to Deep Neural Networks》中提出来的一种新的可以与深度神经网络相媲美的基于树的模型,其结构如图所示。
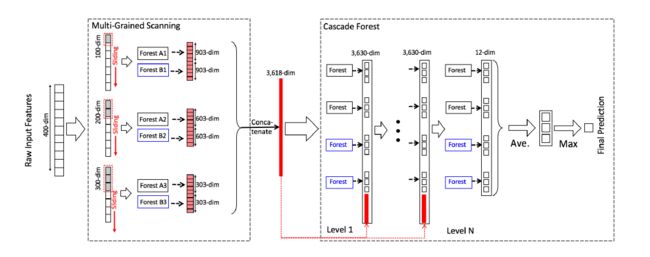
文中提出的多粒度级联森林(Multi-Grained Cascade Forest)是一种决策树集成方法,性能较之深度神经网络有很强的竞争力。相比深度神经网络,gcForest有如下若干有点:
1. 容易训练,计算开销小
2.天然适用于并行的部署,效率高
3. 超参数少,模型对超参数调节不敏感,并且一套超参数可使用到不同数据集
4.可以适应于不同大小的数据集,模型复杂度可自适应伸缩
5. 每个级联的生成使用了交叉验证,避免过拟合
6. 在理论分析方面也比深度神经网络更加容易。
Paper:https://arxiv.org/abs/1702.08835v2
Github:https://github.com/kingfengji/gcForest
Website:http://lamda.nju.edu.cn/code_gcForest.ashx
南京大学机器学习与数据挖掘研究所提供了基于Python 2.7官方实现版本,在本文中,我们使用基于Python3实现的gcForest实现分类任务。
Github:https://github.com/pylablanche/gcForest
gcForest类与sklearn包装的分类器使用方法类似,使用 a .fit() 进行训练,使用a .predict() 进行预测。其中需要我们进行设置的属性为shape_1X和window。shape_1X由数据集决定(所有样本必须具有相同的形状),而window取决于我们自己的选择。
shape_1X 告诉代码我们的样本数据的形状是怎样的,它接受一个列表或数组,其中第一个元素是行数,第二个元素是列数。例如,对于20行和30列的图片,需要给出:shape_1X = [20,30],如果给出长度为40的序列,需要给shape_1X = [1,40]。
window 是数据切片的窗口大小。例如,如果正在使用一个形状[1,40]的序列,并且想要切片的尺寸为20,那么只需设置window = [20]。如果正在使用大小为[20,20]的图片,要进行4x4的切片操作,只需设置“window = [4]”。
分类器构建时需要的参数如下所示:
shape_1X: int or tuple list or np.array (default=None)
训练量样本的大小,格式为[n_lines, n_cols].
n_mgsRFtree: int (default=30)
多粒度扫描时构建随即森林使用的决策树数量.
window: int (default=None)
多粒度扫描时的数据扫描窗口大小.
stride: int (default=1)
数据切片时的步长大小.
cascade_test_size: float or int (default=0.2)
级联训练时的测试集大小.
n_cascadeRF: int (default=2)
每个级联层的随机森林的大小.
n_cascadeRFtree: int (default=101)
每个级联层的随即森林中包含的决策树的数量.
min_samples_mgs: float or int (default=0.1)
多粒度扫描期间,要执行拆分行为时节点中最小样本数.
min_samples_cascade: float or int (default=0.1)
训练级联层时,要执行拆分行为时节点中最小样本数.
cascade_layer: int (default=np.inf)
级联层层数的最大值
tolerance: float (default=0.0)
判断级联层是否增长的准确度公差。如果准确性的提高不如tolerance,那么层数将
停止增长。
n_jobs: int (default=1)
随机森林并行运行的工作数量。如果为-1,则设置为cpu核心数.
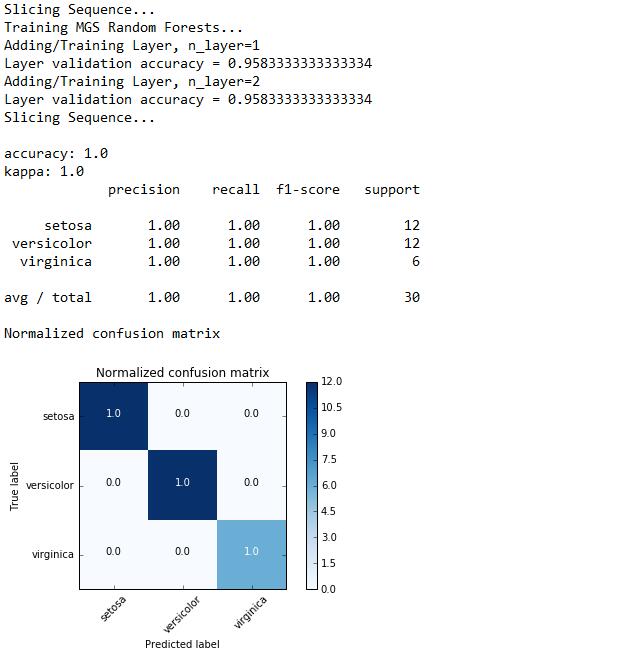
我们使用sklearn带有的Iris数据集进行分类测试,plot_confusion_matrix函数用来绘制混淆矩阵,gcf函数用来进行训练、预测与评估。代码如下所示:
# -*- coding: utf-8 -*-
import itertools
import numpy as np
import matplotlib.pyplot as plt
import sklearn.metrics as metrics
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from GCForest import gcForest
def plot_confusion_matrix(cm, classes, normalize=False,
title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
def gcf(X_train, X_test, y_train, y_test, cnames):
clf = gcForest(shape_1X=(1, 3), window=[2])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print()
print('accuracy:', metrics.accuracy_score(y_test, y_pred))
print('kappa:', metrics.cohen_kappa_score(y_test, y_pred))
print(metrics.classification_report(y_test, y_pred, target_names=cnames))
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
plot_confusion_matrix(cnf_matrix, classes=cnames, normalize=True,
title='Normalized confusion matrix')
if __name__ == '__main__':
data = load_iris()
x = data.data
y = data.target
cnames = list(data.target_names)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
gcf(X_train, X_test, y_train, y_test, cnames)
深度森林的运行与评估结果如下图所示。模型自动选择了深度为2的结构,我们使用accuracy、kappa、f1-score作为分类结果评估指标,并绘制出其结果的混淆矩阵,可以看出深度森林的分类结果非常可观。