Hadoop (四) (MapReduce 的原理+实现)
文章目录
- MapReduce简介
- 为什么需要mapreduce
- mapreduce的工作原理
- 部署过程
MapReduce简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。 —来源于百度百科
mapreduce是hadoop中一个批量计算的框架,在整个mapreduce作业的过程中,包括从数据的输入,数据的处理,数据的数据输入这些部分,而其中数据的处理部分就要map,reduce,combiner等操作组成。在一个mapreduce的作业中必定会涉及到如下一些组件:
1、客户端,提交mapreduce作业
2、yarn资源管理器,负责集群上计算资源的协调
3、yarn节点管理器,负责启动和监控集群中机器上的计算容器(container)
4、mapreduce的application master,负责协调运行mapreduce的作业
5、hdfs,分布式文件系统,负责与其他实体共享作业文件
为什么需要mapreduce
(1) 海量数据在单机上处理因为硬件资源限制,无法胜任
(2) 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3) 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理

可见在程序由单机版扩成分布式版时,会引入大量的复杂工作。为了提高开发效率,可以将 分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架,它把大量分布式程序都会涉及的到的内容都封装进了,让用户只用专注自己的业务逻辑代码的开发。 它对应以上问题的整体结构如下:

mapreduce的工作原理

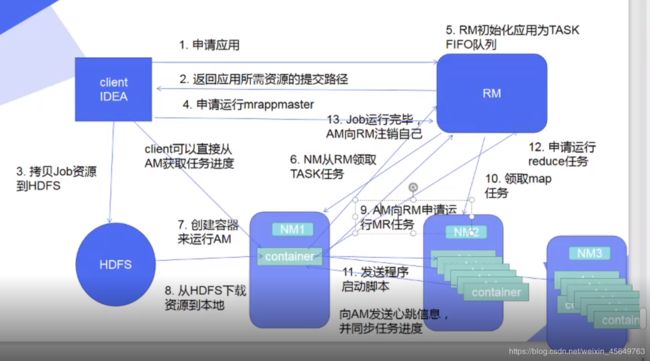 其主要流程有以下几个步骤组成:
其主要流程有以下几个步骤组成:
作业提交
第一步: 客户端通过调用job.waitForCompletion()方法向整个集群提交MapReduces任务;
第二步: 客户端通过getNewApplication方法向ResouceManager申请新应用,成功的话,ResourceManager会返回一个ApplicationId;
第三步:客户端根据ApplicationId在HDFS上创建一个文件夹用于复制作业需要的资源文件,包括jar程序包,配置文件,以及输入split;
第四步:客户端通过submitApplications方法向ResourceManager提交作业;
作业初始化:
第五步:ResourceManager在收到submitApplications请求后,会将该请求发送给scheduler(调度器),调度器会分配一个container,用来运行MRAppMaster应用程序,该应用管理器由所在的nodeManager负责监控;
第六步: MRAppMaster会对作业进行初始化,创建一些bookkeeping对象来监控作业的进度,获得任务进度和完成报告
第七步:MRAppMaster会从HDFS上获取输入split,然后为每个split分配创建一个map任务;
资源分配
第八步: MRAppMaster会根据Map和Reduce任务向ResorceManager申请container资源来运行这些任务;这些请求是通过心跳传输的,请求信息中包含Map和Reduce运行的数据块位置信息(如host和rack),资源调度器收到请求后,会尽量将Map/Reduce任务分配到存储数据块的节点或者分配到存有输入split节点的机架上的其他节点;
任务执行
第九步:MRAppMaster会在资源调度器分配container后,联系对应的NodeManager启动container,运行一个YarnChlid的java应用程序;
第十步:YarnChild应用程序会从HDFS上获取jar文件,作业配置以及相应的资源文件;
第十一步: YarnChild通过.jar程序运行对应的Map或者Reduce任务;
任务执行情况上报:Yarn将任务的执行情况和状态(包括container)上报给MRAppMaster,客户端定时刷新任务状态;
作业完成
作业完成后,会将作业状态进行清理包括MRAppMaster和Container,以及OutputCommiter上的作业清理方法也将会被调用,最后作业的历史信息将会被存储以备查询;
部署过程
在ser3上
1.编写配置文件
[yxx@ser3 hadoop]$ vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
2.定义变量
[yxx@ser3 hadoop]$ vim hadoop-env.sh
[yxx@ser3 hadoop]$ pwd
/home/yxx/hadoop/etc/hadoop
export HADOOP_MAPRED_HOME=/home/yxx/hadoop
3.设置白名单
[yxx@ser3 hadoop]$ vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
启动
[yxx@ser3 hadoop]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
查看ser3 会打开ResourceManager
[yxx@ser3 hadoop]$ jps
15827 NameNode
16631 Jps
16318 ResourceManager
16063 SecondaryNameNode
实际中,做好将ResourceManager和nn分开,因为他俩都是cpu密集型的。
在所有的dn中,会打开一个NodeManager
[yxx@ser4 ~]$ jps
15097 NodeManager
15226 Jps
14943 DataNode
访问ser3的8088端口:
