Core Java(第1-3章)
第一章 概述
1996年,jdk1发布。
Java并不只是一种语言,还是一个完整的平台,有一个庞大的库,其中包含了很多可重用的代码,还提供了一个诸如安全性、跨操作系统的可移植性、垃圾自动收集等服务的执行环境。
简单性、面向对象、分布式、健壮性、安全性、体系结构中立、可移植性、解释型、高性能、多线程、动态
可移植性:java中没有“依赖具体实现”的地方,在java中int永远都是4个字节,而c++中,int可能是2字节,也可能是4字节。在java中,处理文件、线程、网络连接、数据库、日期时间等,完全不用操心底层操作系统。
高性能 :JIT即时编译器,可以对java中的热点代码做即时编译执行(解释器是解释一句执行一句,每次执行都要解释一次,即时编译是直接翻译成机器码)更为复杂的优化是消除函数调用的内联优化。
1.2.6 体系结构中立 / 前端编译器javac
jdk【编译器, JRE【 JVM 【 即时编译器、解释器 】 】】
编译器生成一个体系结构中立的目标文件格式,即字节码。只要有Java运行时系统(JRE,包括了JVM-即java解释器),这些字节码就可以在许多处理器上运行。精心设计的字节码不仅可以很容易地在任何机器上通过JVM解释执行,而且还可以动态地翻译成本地机器代码。
虚拟机有一个选项,可以将执行最频繁的字节码序列翻译成机器码,这被称为即时编译。
跨平台:平台指的是CPU处理器和操作系统构成的体系结构。每种CPU都有自己的指令集,操作系统必需将用户命令转成CPU指令集中的指令。在JAVA语言中,经编译器编译出的字节码则可以在任何安装了JRE的机器上解释执行,这就是跨平台,也就是体系结构中立。在JAVA语言中,JVM虚拟机就相当于操作系统、字节码相当于用户指令、操作系统则相当于CPU。
1.2.8 解释型
java解释器可以在任何移植了java解释器(JVM)的机器上执行java字节码。由于链接是一个增量式且轻量级的过程? ,所以,开发过程也变得更加快捷,更加有探索性。?(什么是链接?类加载后的连接?如何使开发变得更有探索性?)
2.9 即时编译和内联 / 后端编译器 / JIT(Just In Time Compilation)
“Hot Spot Code”(热点代码):当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为“Hot Spot Code”(热点代码)。
Hot Spot Code有两种:一种是被多次调用的方法,一种是被多次调用的循环体。
为了提高热点代码的执行效率,在运行时,虚拟机将会把热点代码(字节码)编译成与本地平台相关的机器码,并进行各层次的优化,完成这项任务的正是JIT编译器。
JIT编译器与解释器的区别是:即时编译生成机器相关的中间码,可重复执行缓存效率高。解释执行直接执行字节码,重复执行需要重复解释。
目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
更复杂的优化是消除函数调用(即“内联”)。即时编译器知道哪些类已经加载,基于当前加载的类集,如果特定的函数不会被覆盖,就可以使用内联。必要时还可以撤销优化。
方法内联后,减少了线程中方法栈的栈帧,也减少了创建、销毁栈及方法调用的耗时,对时间和空间都有优化。
但是如果方法虽然是热点方法(被执行了1500次或者10000次),但是方法体比较大(大于325字节),也不会被内联优化。
此外,即使对方法做了内联优化,还有可能因为方法被继承,导致需要类型检查而没能达到优化的效果。
因此,要想使得JIT的内联优化发挥作用,需要注意以下几点:
- 拆分大的方法,减小每个方法的方法体。
- 尽量使用final、private、static修饰符
- 使用+printInlining检查效果
- 可参考Netty库上使用内联优化的例子
关于前端编译器(Javac)和后端编译器(JIT)
JIT的几种优化JVM性能的手段
第二章 java程序设计环境
2.1.1 下载安装JDK
术语
JDK : 编写java程序的程序员使用的软件
JRE : 运行java程序的用户使用的软件,包含虚拟机但不包含javac编译器
java SE:Standard Edition,用于桌面或者简单服务器应用的java平台
Java EE: Enterprise Edition ,用于复杂服务器应用的java平台
Open JDK:java SE的一个免费开源实现
SDK:software dev kit , 一个过时的术语,98-06年之间的JDK
update:Oracle的术语,表示bug修正版本。8u31是1.8.0_31
NetBeans:Oracle的集成开发环境
版本选择
对于linux,建议选择 .tar.gz,而非RPM。
.tar.gz可以选择在任何位置解压缩。
RPM安装,需要反复检查是否装在了/usr/java/jdk1.8.0_version
安装
windows操作系统上,注意安装路径不要有空格和中文。
linux系统上,装到/opt/jdk1.8.0_31
Linux系统目录详解
| 目录 | 全称 | 用途 |
|---|---|---|
| /root | root | root用户即超级管理员用户的主目录 |
| /sbin | super bin | super User使用的命令,引导、修复或者恢复系统的命令。即超级管理员用户使用的管理系统命令的文件夹 |
| /etc | and so on | 等等,其它文件的意思。存放系统管理的配置文件 |
| /home | - | 普通用户主目录的根目录,在此目录下,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的 |
| /opt | optional | Optional application software packages。这里主要存放那些可选的程序。你想尝试最新的firefox测试版吗?那就装到/opt目录下吧,这样,当你尝试完,想删掉firefox的时候,你就可 以直接删除它,而不影响系统其他任何设置。安装到/opt目录下的程序,它所有的数据、库文件等等都是放在同个目录下面。主机额外安装软件的安装目录。比如安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。 |
| /var | variable-可变的 | 存放着在不断扩充着的东西,那些经常被修改的目录放在这个目录下。包括各种日志文件。非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下 |
| /lib | - | 存放着系统最基本的动态连接共享库,类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库 |
| /usr | Unix Software Resource | Unix操作系统软件资源所放置的目录,所有系统默认的软件都会放置到/usr, 系统安装完时,这个目录会占用最多的硬盘容量 |
| /usr/bin | - | 普通用户的可使用指令,绝大部分都放在这里 |
| /usr/sbin | - | 非系统正常运作所需要的指令,常见的是某些网络服务器软件的服务指令 |
| /bin | Binary | 命令 |
| /media | 自动识别的一些设备,例如U盘、光驱等等,会被挂载到这个目录下 | |
| /proc | :所有正在运行进程的映像 | |
| /tmp | 每次重新引导就消失的临时文件 |
将java的命令路径设置到系统的执行路径变量中
用户在命令行窗口中键入某个命令并键入enter后,系统会遍历执行路径变量中配置的所有目录,在这些目录中找到要执行的命令,然后运行之,才能执行用户发出命令。
因此我们要想在命令行窗口中运行 javac.exe 或者java.exe或者jdk/bin下的其它命令,就必须把jdk/bin的路径配置到执行路径变量中去,并使之永久生效。
linux的环境变量配置中,要先删除~/.bash_profile中的三行关于~/.bashrc的 定义,然后把环境变量配置在~/.bashrc中
2.选择要使用的java环境:update-alternatives –config java
3.要使得刚修改的环境变量生效:source .bashrc
4.查看环境变量:env
也可以放到/etc/bash/bashrc,这样就是系统级的
安装源文件和文档
cd ~ //changge direcotry to ~ :进入用户主目录
mkdir javasrc //make directory :创建javasrc文件夹
cd javasrc
jar xvf jdk/src.zip
关于tar jar命令详见:
linux常用操作
第三章 java的基本程序结构
类名
必须大写字母开头,后跟字母和数字的任意组合,大小写遵循驼峰规则。
注意
在java中“字母”和“数字”的范围更大,字母包括a-z A-Z _ $,或者在某种语言中表示字母的任何Unicode字符。例如希腊人可以用π。数字除了0-9外,某种语言中表示数字的任何Unicode字符都可以。
如果想知道某个字符是否属于JAVA中的字母,可以调用Character.isJavaIndetifierStart(char c),来检测字符是否可以作为首字母
Character.isJavaIndetifierPart(int codePoint)方法来检测字符是否可以出现在类名中
每个应用程序必须有一个 public static void main(String [] args){}方法作为程序的入口。
3.3.2浮点类型
浮点类型的字面量会被JAVA自动识别为double,如果要标识为float,可以在数字后边加f。
99%的浮点数(小数)无法用二进制精确表示,正如十进制无法精确地表示分数1/3一样。
任意实数,整数部分用普通的二进制便可以表示,对于小数部分,将该数字乘以2,取出整数部分作为二进制表示的第1位;然后再将小数部分乘以2,将得到的整数部分作为二进制表示的第2位;以此类推,知道小数部分为0。
0.6 * 2 = 1.2, 取 1余0.2,
0.2 * 2 = 0.4,取0余0.4,
0.4 * 2 = 0.8,取0余0.8,
0.8 * 2 = 1.6, 取 1余0.6,
0.6 * 2 = 1.2,取1余0.2,进入循环 …
形成了一个无限循环的二进制:0.1001 1001 1001 1001…
因此只能截取一部分,存储浮点数的近似值。
参考:
小数的二进制表示与转换
浮点数在计算机中如何存储
double型精度是float型的两倍。
如果在数值计算中不允许有任何的舍入误差,可以用BigDecimal这个类来处理。
下面是用于表示溢出和出错情况 的三个特殊的浮点数值:
| 正无穷大 | Double.POSITIVE_INFINITY |
| 负无穷大 | Double.NEGATIVE_INFINITY |
| NaN | 不是一个数字,可以用Double.isNan(x)来判断 |
3.3.3 char类型
char类型的字面量值要用单引号括起来的单个字符来表示’A’。
码点(code point)与代码单元(code unit)
码点(code point)是指Unicode字符集中的每个字符对应的代码值。
比如,在Unicode字符集中,'A’的代码值是56,十六进制值是\u0037。
起初,Unicode字符集中的总字符数是不超过65536个的,也即其码点即代码值不会大于65535,那么在计算机中用两个字节16位就足够存储这些码值。
在java语言中,最初是是用char类型来表示Unicode字符集中的字符,用utf-16来编码存储。即一个char类型的字符,分配两个字节来存储。
但是随着Unicode字符集的逐渐扩充,字符个数远超65536,那么有些码点即代码值也大于65536了。
这时,char类型,两个字节的存储空间,是无法存储大于65535的码点的。
因此jdk5开始,将char类型的定义更新成了“char类型描述了Ut-16编码中的一个代码单元(code unit)”。
综上,char类型是一个代码单元
字符集与编码实现
针对Unicode字符集中字符数超过65536的问题,UTF-16编码方式采用如下方式解决:
首先,将Unicode的码点(code point ,每个字符的码值)分成17个代码级别。
第一个代码级别-基本的多语言级别,包括经典的Unicode码点,码点从U+0000到U+FFFF。
其余的16个代码级别,码点从U+10000到U+10FFFF。
但是,第一个代码级别的码点虽然是从U+0000到U+FFFF,但是在设计上,并没有完全占用U+0000到U+FFFF中的所有码值,而是空闲出了U+D800 ~ U+DFFF这段码值。
0~0xD7FF 15+(15*16)+(16^2)*7+((16^3)*13)=55295个
0xE000~0xFFFF (2^13)+ (2^14) + (2^15) ~ (2^16-1) //共8191个
而其余的16个代码级别的字符,需要用两个代码单元来表示。就是利用了这段空闲的码值,将其分为U+D800~U+DBFF以及U+DC00~U+DFFF两部分,前一部分用来作为字符的第一个代码单元的前缀,后一部分用来作为字符的第二个代码单元的前缀。
据此,如果一个代码单元的值小于U+D800,或者大于U+DFFF,那么它就是第一代码级别的字符,也就是说这一个代码单元就表示一个字符。
而如果,一个代码单元的值处在U+D800~U+DFFF之间,那么这个代码单元就是需要两个代码单元的字符的其中一个代码单元。
使用下面公式编码:
-
计算 U’= U – 0x10000
-
将U’写成二进制形式:yyyy yyyy yyxx xxxx xxxx
-
加上标志位,1101 10yy yyyy yyyy 1101 11xx xxxx xxxx
可见,这是4个字节表示,2个6位标志位,20位有效位。因为U最大是0x10FFFF,所以U’最大是0xFFFFF,20位足够表示。
参考:字符集和字符编码4.9节UTF-16
windows上默认的Unicode编码方式就是UTF-16,使用wchar_t表示。
3.5 运算符
整数除以0会产生异常。
浮点数除以0会得到无穷大或者NaN。
3.5.1 数学函数与常量
直接在源文件头导入 Math.*即可:import static java.lang.Math.*;
floorMode()
由于java最初定的取余运算的规则是,负数余除于正数的结果为负,大部分场景下的业务需求都不是这样的,这也不符合“欧几里得”规则:余数总是>=0;因此专门提供了一个工具方法:
floorMode(x,n),x%n,可以保证余数为正数。
在java中:-5%2=-1,但floorMode(-5,2)=1
乘方:pow(a,n) a^n
开方:sqrt(a),平方根
正弦:sin
余弦:cos
正切:tan
无理数e的近似值:Math.E
π的近似值:Math.PI
自然对数:log(数学中用ln)
以10为底的对数:log10(数学中用lg)
3.5.3 类型转换
在一些数值运算中,java可能会进行自动类型转换,规则是:
- 如果两个操作数中有一个是 double 类型, 另一个操作数就会转换为 double 类型。
- 否则,如果其中一个操作数是 float 类型,另一个操作数将会转换为 float 类型。
- 否则, 如果其中一个操作数是 long 类型, 另一个操作数将会转换为 long 类型。
- 否则, 两个操作数都将被转换为 int 类型。
当将位数多的类型直接赋值给位数少的数值类型的时候,需要用户显式地进行强制类型转换cast。
int a=0; a=(cast)0.5;
扩展赋值运算符会默认对计算结果进行强转,因此无需用户显式地强转。
int a =0; a+=0.5;
3.5.7 位运算符
&(按位与) |(按位或) ^(按位异或) ~(按位取反) <<(带符号左移)>>(带符号右移)>>>(无符号右移)
&:利用&运算符可以得到二进制整数的各个位上的数字,即保留要获取的位上的数字,把其它位全掩掉:
例如任何二进制数x,进行如下运算后:x & 0b1000后,都只剩下从右边数的第4位有效。如果 x & 100,则可以获得第3位上的数字。
<<
带符号左移,x<
例如:
>>
带符号右移,意思是带着符号位一起向右移走n位,移走后空出的n位高位上要补上数值,全都用原符号位上的数值。
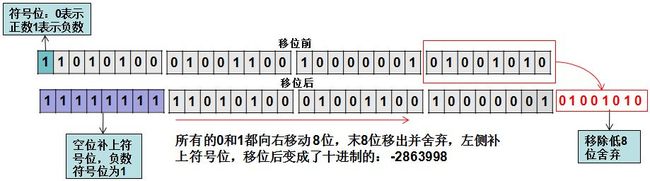
>>>
高位全部补0,无论原本的符号位是1还是0
3.6 字符串
s.substring(m,n); //从m开始复制,到n就不复制了。子串长度=n-m
‘+’ 字符串拼接符,当将一个字符串与一个非字符串的值进行拼接时,后者被转换成字符串(任何一个 Java对象都可以转换成字符串)
3.6.6 码点与代码单元
java字符串由char字符序列组成。
Char类型字符是一个采用UTF-16编码表示Unicode码点的代码单元,大多数Unicode字符使用一个代码单元就可以表示,但是辅助字符需要一对代码单元来表示。
string.length()方法返回的就是使用UTF-16编码表示给定的字符串时需要的代码单元的数量。
string.codePointCount(0,string.length())返回的是实际的码点数,即string中Unicode字符的数量。
string.charAt(i)返回的是第i个代码单元,如果string中有一个辅助字符,即占了两个代码单元的字符,那么返回的第i个代码单元就有可能是辅助字符的第2个代码单元,而非string中的一个字符。
因此,为了预防开发人员使用char类型时出现代码单元和实际字符数量的混淆,代码中最好不要有对char类型的操作。
而是,通过string.codePoints()获得一个int流,然后.toArray()获得每个字符的码值数组int []。
反之,要用一个码点数组构造一个字符串,可以用
new String(codePoints,0,codePoints.length)
3.6.7常用String API
Java 中的 String类包含了 50 多个方法。令人惊讶的是绝大多数都很有用, 可以设想使 用的频繁非常高。
int compareTo(String other);-1,0,1
boolean equals(String other) / equalsIgnoreCase(String other)
boolean startWith(String prefix) / endsWith(String suffix)
int indexOf(String sub) / indexOf(String sub, int from)
int indexOf(int codePoints) / indexOf(int codePoints, int from)
从索引位置0或者from开始查找是否有匹配sub或则cp的子串,如果有,返回第一个子串的位置
int lastIndexOf()…返回最后一个子串的位置
3.6.8 字符串连接
用’+'拼接字符串比较浪费内存,因此推荐使用StringBuilder,在多线程情况下用StringBuffer,但其效率相对较低。
StringBuilder的常用API:
append(String s)
insert(int offset, String str)
delete(int start, int end)
length()
toString()
3.7 输入输出
java.util.Scanner**
首先构造一个Scanner对象,然后将之与System.in关联。
参考:类Scanner
Scanner scanner = new Scanner( System.in );
useDelimiter(String pattern / Pattern pattern);
skip(String pattern / Pattern pattern);
useRadix(int radix); //设置数值显示时的进位制
hasNext() / hasNextLine()
hasNextByte / Short / Int / Long / Float / Double / Boolean / BigInteger / BigDecimal()
文件输入输出
读文件:new Scanner(Paths.get(“myfile.txt”, “UTF-8”));
写文件:new PrintWriter(“myfile.txt”, “UTF-8”);
java.io.Console
首先使用System类中的一个静态方法获取一个Console的实例:
static Console System.console();
然后使用Console进行交互:
static char[] readPassword( String prompt, Object … args );
static String readLine(String prompt,Object … args);
显示字符串prompt并读取用户输入,直到输入行结束。args参数可以用来提供输入格式。
格式化输出
System.out.printf( formatString , argvalues…);
在formatString中有三个概念,一个是格式说明符,一个是转换字符,最后是控制格式化输出的各种标志。
以%字符开始的都是格式说明符,格式说明符尾部的是转换符。
格式说明符都要用相应的参数实际值argvalue替换,转换符则指示被格式化的数值的类型。
| 格式转换符 | 数值类型 | 举例 |
|---|---|---|
| d | 十进制整数 | |
| o | 八进制整数 | |
| x | 十六进制整数 | |
| s | 字符串 | |
| c | 单个字符 | |
| b | 布尔类型 | |
| % | 百分号 | 由于%自身的特殊意义导致的 |
另外还有 f (定点浮点数,15.9),e(指数浮点数,1.59e+01),g(通用浮点数)
| 标志 | 目的 | 举例 |
|---|---|---|
| + | 打印正数和负数的符号 | +3333.33 |
| ( | 如果是负数,用括号括起来 | (-3333.33) |
| 空格 | 在正数之前添加空格 | |
| 0 | 数字前面补0 | 003333.33) |
| ( | 如果是负数,用括号括起来 | (-3333.33) |