简述
通过前面练习,应该抓取简单静态页面so easy,本节主要实现抓取动态加载(JavaScript)内容页面。
抓取数据请勿存档,商用请联系 环境保护部信息中心 获取授权。
爬取对象
抓取环保部数据中心“12369”举报案件情况
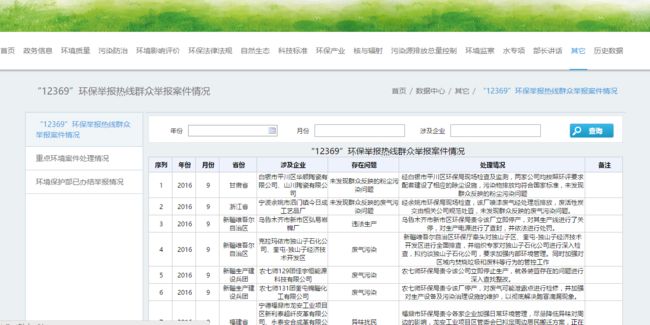
“12369”举报案件情况
使用包
import pymssql # MS Sql Server 操作
from bs4 import BeautifulSoup
import time, os
import requests
import datetime
实现步骤
1、抓取对象初步分析
- 通过
F12捕获页面内容,分析页面加载内容,得知目标内容主要为Table布局,通过javascript:jumpPage2(2);进行页面跳转。
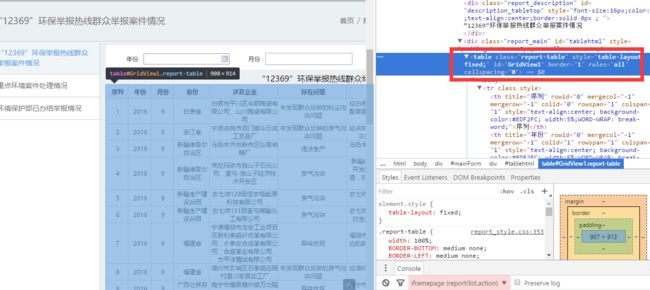
页面分析

页面跳转方式
- 分析总结主体抓取步骤如下
Start
1、获取总页数,确定循环次数
2、单页内容抓取,按行拆分存储至数据库
3、测试翻页抓取
End_重复上述步骤
2、实际抓取
获取总页数
DOWNLOAD_URL = 'http://datacenter.mep.gov.cn/index!MenuAction.action?name=e3022e3d34274fdeabccd9ca8b17fef4'
# 页面下载
def download_page(url):
return requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content
# 获得总页数
def parse_html(html):
soup = BeautifulSoup(html, "html.parser")
print(soup.find('div', attrs = {'class': 'report_page'}))
#None
html = download_page(DOWNLOAD_URL)
allPageNum = parse_html(html)
- 遇到问题,抓取返回
Null。 - 分析得知,目标对象与请求
Url为父子页面关系,通过Iframe关联
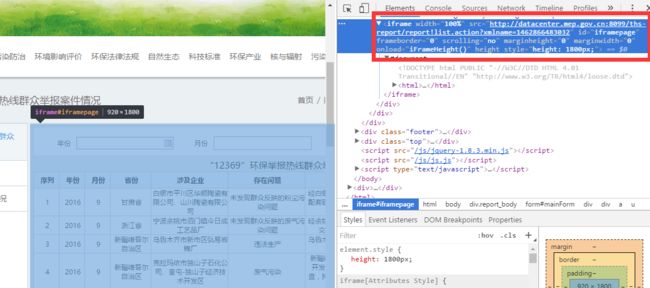
Table在iframe中
#修改请求URL
DOWNLOAD_URL = 'http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1462866483032'
# 获得总页数
def parse_html(html):
soup = BeautifulSoup(html, "html.parser")
page = str(soup.find('div', attrs = {'class': 'report_page'}).findAll('a')[-1]) # 取出 “末页” 翻页,得到总页数
allPageNum = page[page.index('(') + 1:page.index(')')]
print("总页数:" + allPageNum)
return allPageNum
单页内容抓取
- 循环解析
Table入库即可,期间sql因格式化字符串少写一个,遇到如下问题
#如 %s 与 column_0未对齐,出现异常提示如下:TypeError: not enough arguments for format string
sql = "insert into Space0011A values ('%s','%s','%s','%s','%s','%s','%s','%s')" % (column_0,column_1,column_2,column_3,column_4,column_5,column_6,column_7)
#如未对齐,出现异常提示如下:IndexError: tuple index out of range
#sql = "insert into Space0011A values ('{0}', '{1}', '{2}', '{3}', '{4}', '{5}', '{6}', '{7}')".format(column_0,column_1,column_2,column_3,column_4,column_5,column_6,column_7)
ms.ExecNonQuery(sql.encode('utf-8'))
翻页抓取

Post参数分析
- 尝试直接模拟参数提交
DOWNLOAD_URL = 'http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1462866483032'
# 页面下载
def download_page_post(url,pageNum):
formdata = {'page.pageNo':pageNum,'page.orderBy':'','page.order':'','orderby':'','ordertype':'','xmlname':'1462866483032','gisDataJson':'','queryflag':'close','isdesignpatterns':'false','YEAR':'','MONTH':'','ENTE':'','inPageNo':3}
return requests.post(url,timeout=60, data=formdata, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content
def parse_html(html):
soup = BeautifulSoup(html, "html.parser")
print(soup)
html = download_page_post(DOWNLOAD_URL,2)
parse_html(html)
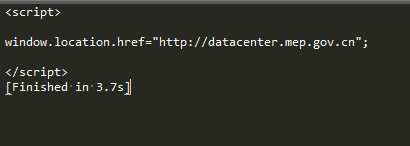
返回HTML
- 根据返回怀疑是参数传递不正确,自动跳转主页
- 后尝试将参数转成
json提交
def download_page_post(url,pageNum):
formdata = {'page.pageNo':pageNum,'page.orderBy':'','page.order':'','orderby':'','ordertype':'','xmlname':'1462866483032','gisDataJson':'','queryflag':'close','isdesignpatterns':'false','YEAR':'','MONTH':'','ENTE':'','inPageNo':3}
return requests.post(url,timeout=60, data=json.dumps(formdata), headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content
返回抓取页面
- 切换页面继续测试,- -,行号一直是 1 - 20,原来转换
json不正确,导致服务器一直认为应该返回首页 - 去掉
json格式转换,继续对比分析,许久后发现参数中xmlname与URL中重复,发现去掉其一即可......
DOWNLOAD_URL = 'http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1462866483032'
# 页面下载
def download_page_post(url,pageNum):
formdata = {'page.pageNo':pageNum}
return requests.post(url,timeout=60, data=formdata, headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}).content

返回第二页数据
总结
本轮示例主要实现JavaScript动态翻页数据解析,期间主要使用 Post带参提交,完成模拟翻页操作,至此完成“12369”举报数据抓取......
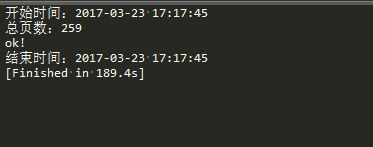
抓取完成
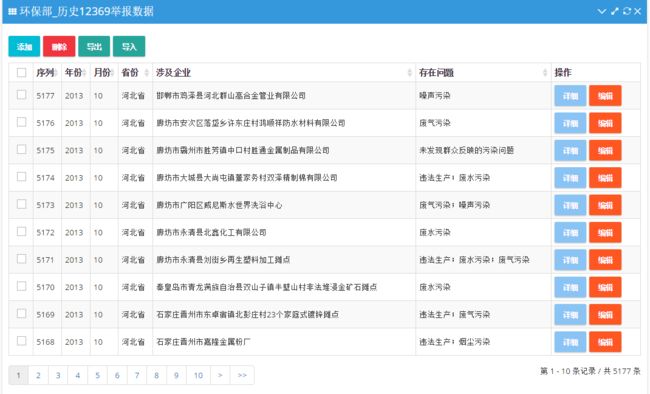
简易展示
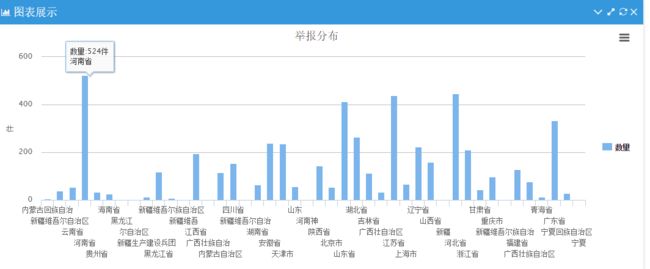
简易分析
源码:
MSSql_SqlHelp
spider_12369