小白入门计算机视觉系列——ReID(二):baseline构建:基于PyTorch的全局特征提取网络(Finetune ResNet50+tricks)
ReID(二):baseline构建:基于PyTorch的全局特征提取网络(Finetune ResNet50+tricks)
小白入门系列是我和朋友准备一起做的一块内容,分模块分专题·,比如计算机视觉中的目标检测,ReID,OCR,语义分割以及大火大热的AutoML等等。
本次带来的是计算机视觉中比较热门的重点的一块,行人重识别(也叫Person ReID),车辆重识别和行人重识别类似,有很多的共同之处,所以以下统称该任务为ReID。
知乎:https://www.zhihu.com/people/bei-ke-er-1-34/activities
Github :https://github.com/lixiangwang/Person-ReID
1. baseline构建及ResNet-50的模型迁移
什么是baseline? 即所谓的基线网络,就是为个性化的模型提供基础框架和算法。
1.1 经典CNN的缺陷以及ResNet成因
在深度学习中的一个重要思想是模型的深度和模型的准确率有着很大的关系,例如在CV领域中,由卷积层,池化层和全连接构成了经典CNN网络,如LeNet。CNN的网络层数越多,可以学习到更多层的特征。考虑到网络层数的增加,必然会使网络变得更复杂,训练成本也越高。此外,增加网络层数并不一定能达到好的模型效果。何凯明曾做过实验:应用在CIFAR-10的数据集上训练了两个经典CNN网络(由卷积层,池化层,全连接层构成),一个20层,一个56层,实验结果如下:
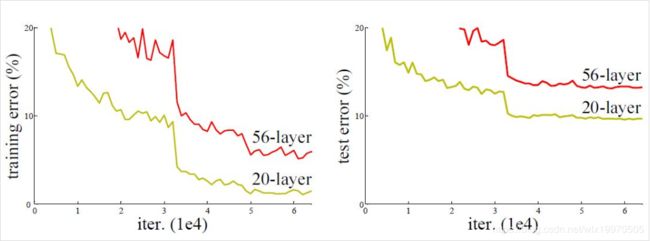
从结果上可以看出,56-layer的模型性能比20-layer差,且层数加深,效果却变差。并且这不是模型过拟合所导致的,因为如果过拟合导致的测试不理想,那么在训练集上的效果应该是非常好才对。
造成这种结果的原因有两个:一个是随着神经网络的层数加深,很可能发生梯度消失或梯度爆炸,这两种梯度现象均会招致模型在迭代的时候出现错误的梯度引导,结果使模型的收敛存在问题;另一个是退化现象,即随着网络的层次加深,假如在之前某一层已经达到了很好的输出效果,那么后续的网络结构会削弱前面的好效果的,也就是网络的学习能力遭受了退化。
考虑上述第二种原因,如果使得后续的网络不影响前面的最优结果,设计的目的也达到了,这也是ResNet设计的初衷。
1.2 ResNet以及finutune一个初始化参数的网络
微软亚研院何凯明博士借助深度残差网络,在众多CV算法比赛中成为冠军,同时其论文也获得了2016年CV顶会的最佳论文,ResNet也获得了很好的声誉,这在很大程度上导致了深度学习的革命。
ResNet的重点部件是其残差模块,如图所示。
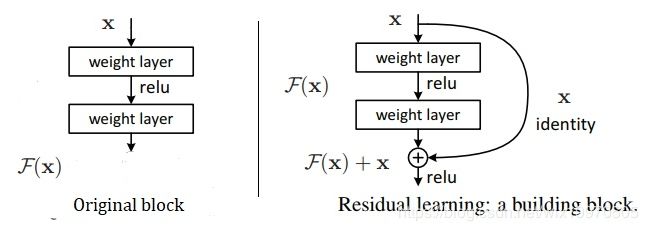
数学公式推导啥的我这里就不说了,其实我感觉如果一个初学者执着于数学公式是很打击自信心的,公式推导肯定要知道,慢慢来嘛!
关于ResNet我看到过有一个很有意思的理解,这里是原文链接
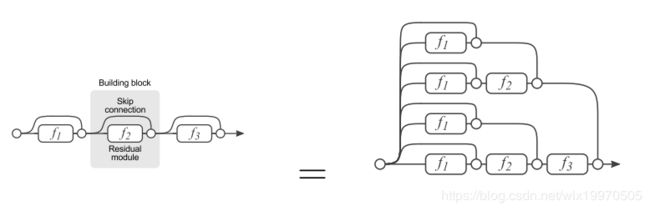
残差网络单元其中可以分解成上面右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。如果把残差网络理解成一个Ensambling系统,那么网络的一部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该适合删除的残差单元的个数成正比的,论文里的结论也印证了这个猜测。
ResNet的确可以做到很深,但是从上面的介绍可以看出,网络很深的路径其实很少,大部分的网络路径其实都集中在中间的路径长度上,如下图所示:
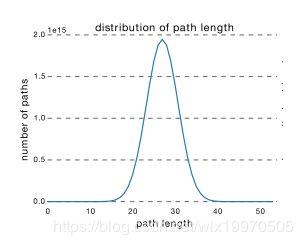
从这可以看出其实ResNet是由大多数中度网络和一小部分浅度网络和深度网络组成的,说明虽然表面上ResNet网络很深,但是其实起实际作用的网络层数并没有很深,我们能来进一步阐述这个问题,我们知道网络越深,梯度就越小,而通过各个路径长度上包含的网络数乘以每个路径的梯度值,我们可以得到ResNet真正起作用的网络是什么样的,如下图所示 。
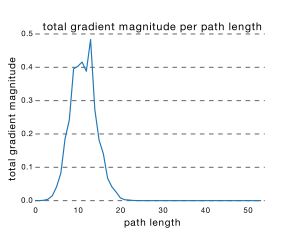
我们可以看出大多数的梯度其实都集中在中间的路径上,论文里称为effective path。 从这可以看出其实ResNet只是表面上看起来很深,事实上网络却很浅。 所以ResNet真的解决了深度网络的梯度消失的问题了吗?似乎没有,ResNet其实就是一个多人投票系统。
在我们的ReID任务中,我们采用50层的深度残差网络ResNet-50作为基线网络,并且在使用ResNet-50的时候需要做一个finetune迁移学习。finetune是一种重要的迁移学习方式,即通过微调,不用对模型的各个参数进行重新训练。finetune一般都是基于一个大数据集预训练下的网络,对于一个数据量不是很大的深度学习任务,finetune也可以比避免因模型复杂而数据不够造成的过拟合学习。
在我们的ReID任务中,我们的finetune的是一个ResNet-50网络,它最初是基于一个大数据集的初始训练。PyTorch的模型库中初始训练的ResNet-50的示意图如图。
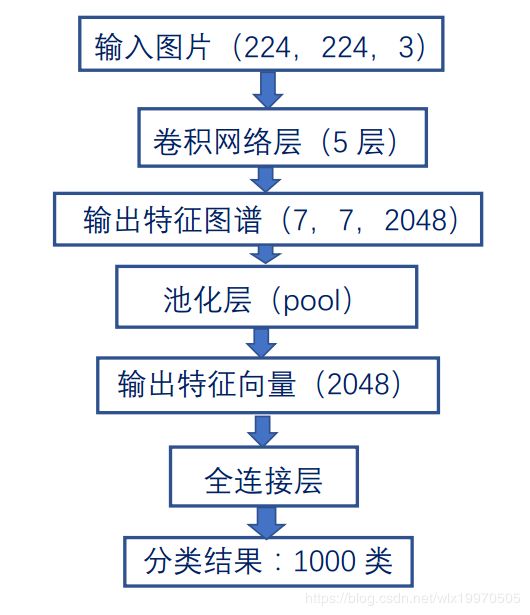
模型需要finetune的是特征图谱和最终全连接层的分类标签。实验中,我们基于PyTorch,在模型库里面可以加载预训练网络,如下:
from torchvision import models #torchvision库中的models包含了一些常用网络模型以及训练好的参数
model_ft = models.resnet50(pretrained=True)
pretrained参数为True则继承了模型库中的模型参数和结构,若为false则只加载模型结构,也就失去了finetune的意义。
2. 模型的一些tricks
tricks是个很只可言传不可意会的东西,因为很多论文包括一些顶会的论文都用到了一些tricks来提高跑分的分数却在论文中不说。???
这里我们说几个常用的:
2.1 REA
数据扩展常作为一种增强训练效果的策略,它可以使有限的数据集经过算法获得更多的数据。
随即擦除增广(Random Erasing Augmentation,REA)是一种基于随机擦除的数据扩展方法。算法思路为在图像中随机选择一个区块,掩盖上噪声区块。随机擦除是一种数据扩展的方式,可以降低模型过拟合的程度,因此可以提升模型的性能。
原论文中给出的算法流程如图。

实验中采用原论文设置的参数,应用在一个batch的Market1501 数据集上的效果如图。
2.2 动态学习率机制
学习率(learning rate,lr)是深度学习的一个关键参数,它参与了优化器下降的步长,决定了网络参数更新的速度。一般而言,lr越大,更容易收敛,但下降步长过大容易错过最优解,学习率越小,下降步长越小,但网络收敛的更慢,同时也更容易陷入局部的最佳解。下图反映来不同学习率对优化器寻找损失最小值的表现。
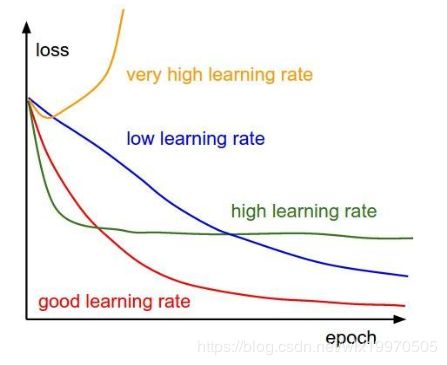
在一个ReID任务中,我们设定了动态调整学习率的机制,即随着不同epochs数据的训练,模型的学习率是不同的,具体如何调整学习率需要观测训练过程的loss。一般而言,初始的lr设为较大值,以使模型能快速收敛,且不错过局部最优,等loss不再降低的时候,适当调小学习率,梯度下降的步长更小,使得模型学习的更细致。
罗浩大佬采用的一个warm up策略,论文链接(CVPR 2019)。
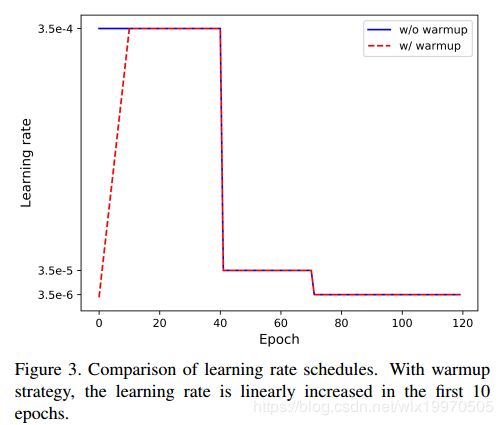
按作者所说:Warmup学习率并不是一个新颖的东西, 在很多task上面都被证明是有效的,在之前的工作中也有过验证。标准Baseline使用是的常见阶梯下降型学习率,初始学习率为3.5e-4,总共训,120个epoch,在第40和70个epoch进行学习率下降。用一个很大的学习率初始化网路可能使得网络震荡到一个次优空间,因为网络初期的梯度是很大的。Warmup的策略就是初期用一个逐渐递增的学习率去初始化网络,渐渐初始化到一个更优的搜索空间。下图是论文中用最简单的线性策略,即前10个epoch学习从0逐渐增加到初始学习率。
2.3 特征图扩张
在使用ResNet-50作为backbone的时候,最后一层卷积层之后会接一个下采样,也就是最后一个卷积层的stride参数为2。在ReID中,输入图像为256128,经过特征提取网络之后得到的特征图为84。考虑到更好的学习特征,一个策略就是扩大特征图的尺寸,也就是将最后一个卷积层的stride参数变为1,这样特征图尺寸就变为16*8。更大的特征图能体现到更多的特征,也就可以提升模型的学习能力。
3. 计算结果分析(完整代码见作者GitHub)
3.1 数据载入和预处理
在PyTorch中,ImageFolder和DataLoader函数可以载入指定路径的数据:
image_datasets = {}
#ImageFolder 数据加载器,指定路径下加载并执行组合好的transforms操作
image_datasets['train'] = datasets.ImageFolder(os.path.join(data_dir, 'train' + train_all),
data_transforms['train'])
image_datasets['val'] = datasets.ImageFolder(os.path.join(data_dir, 'val'),
data_transforms['val'])
#torch.utils.data.DataLoader:
#该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入
#shuffle 是否将图片打乱 / num_workers:使用多少个子进程来导入数据 /pin_memory: 在数据返回前,是否将数据复制到CUDA内存中
#
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=opt.batchsize,
shuffle=True, num_workers=8, pin_memory=True)
for x in ['train', 'val']}
数据加载进来后需要预处理:
transform_train_list = [
#transforms.RandomResizedCrop(size=128, scale=(0.75,1.0), ratio=(0.75,1.3333), interpolation=3), #Image.BICUBIC)
transforms.Resize((256,128), interpolation=3), #重置图像大小(分辨率),interpolation为插值方法
transforms.Pad(10), #填充
transforms.RandomCrop((256,128)), #按指定尺寸随机裁剪图像(中心坐标随机)
transforms.RandomHorizontalFlip(), #以0.5概率使图像随机水平翻转 (这些都是增强数据的实际效果,泛化性等)
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #数据归一化
]
transform_val_list = [
transforms.Resize(size=(256,128),interpolation=3), #Image.BICUBIC
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
Transform是torchvision中的图像处理库。由于数据集的图像大小可能不同,我们需要统一训练数据的大小,transforms.Resize函数可以重置图像大小。
transforms.RandomCrop和transforms.RandomHorizontalFlip分别为随机裁剪和水平翻转,均为数据扩展的处理方法。在计算机视觉中,我们计算一副图像需要对其做标准化,即减去均值和除以标准差,在此之前需要将数据转换为tensor的格式才能计算。
3.2 实验分析
深度学习的训练需要大量的时间,因次,模型的调参是每个深度学习任务的重要步骤之一。由前文的叙述可知,实验我们采用了finetune的方式加载了一个预训练好的网络,并在此基础上加入了若干组训练策略。
在训练时间的比较中,我们规定batchsize为32,epoch的个数为80,均在Market-1501上的训练,实验结果如下表。

实验中并没有考虑学习率变化的影响,应为学习率和梯度下降的方法一样,如果模型收敛较慢,只要是还在收敛,只要epochs数量足够,它对最终的训练时间是没有影响的。从表可以看到,几个明显增强训练时间的步骤是dropout和REA,dropout增大了网络的计算量,而REA则是增加了数据,带来了更大的时间开销。
关于数据预处理阶段图像统一尺寸的讨论:我们实验了几组重置后的尺寸,采用相同的算法(没有做Re-ranking),在Market-1501上得到如下计算结果:

从上表中可以看到,同一算法和数据集下,图像重置后的尺寸对实的结果影响不大,我们认为图像resize后的具体大小对模型的评测是没有大的影响的,所以为了方便起见,我们所有图像的大小在预处理阶段均resize到256*128的尺寸。实验中,我们实验了三个数据集:Market-1501,DukeMTMC-reID,CUHK-03。
随机选择Market-1501训练数据集中每个ID的一张图片作为val_set,其余图片作为train_set。批量大小设置为32,ResNet-50主干网络训练60个epochs,加入训练技巧后的网络训练80个epochs。
在增加训练技巧之前,训练过程中的损失曲线和top1误差曲线如下图。

初始学习率为0.05,前30个epochs的lr为0.05,30-60个epochs的lr为0.005,从train loss和val loss的曲线可以看出,模型收敛是比较快的,train_set的效果低于val_set的学习效果是由于模型本身的不足导致的,可以看到,训练后续学习平稳,且没有产生过拟合的现象。下图为加入训练策略后的训练情况。
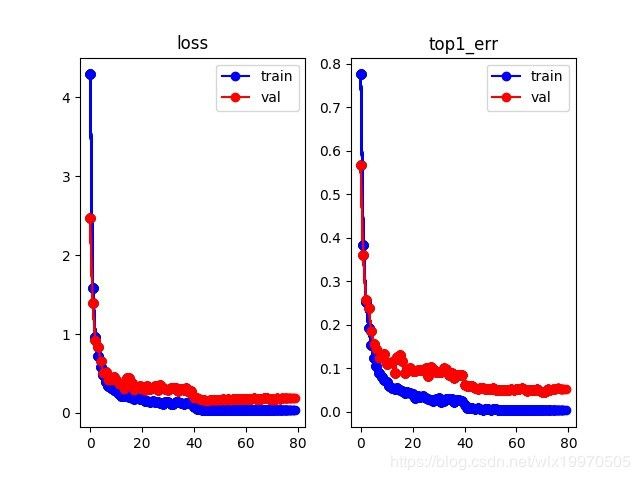
加入策略后,由于数据增多,计算变得更复杂,所以数据一共训练了80个epochs,前40个epochs的lr为0.05,后40个epochs的lr为0.005.图中可以明显看到,加入策略后,模型的收敛变慢了,在学习率调整后,模型得到了进一步学习,且train loss和val loss均保持平稳,没有过拟合的现象发生。
DukeMTMC-reID和CUHK-03的训练过程和Market-1501类似,train-val组合验证的意义是监测过拟合的发生,而dropout也避免了过拟合。三组数据集在模型下的表现性能如下表:

从表中可以看出,加入的训练策略在三个数据集中均可以明显提高模型的性能。从结果上来看,三个数据集中难度最大的为CUHK-03,而CUHK-03数据集本身就具有很多的挑战性,比如在一个ID的标注框中却不止一个行人。
下为近两年的流行算法以及我们的基线网络性能上的对比。其中,our baseline是基于backbone为ResNet-50网络加上几个策略,并且没有做Re-ranking。
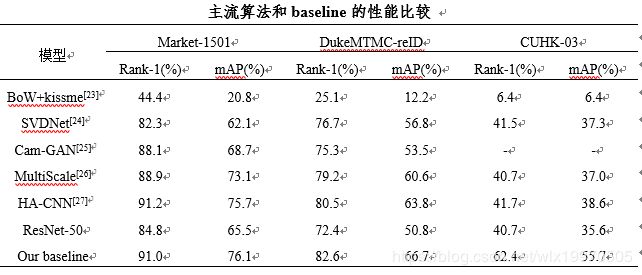
从上表可以看到,我们的基线网络经过若干优化之后的性能还是很强的,这说明几个策略极大的改善了模型的性能,可以作为更复杂模型的基线网络。
下面三张分别为Market-1501、DukeMTMC-reID和CUHK-03的一组演示demo。



query为待查询图像,右边列出gallery库中相似度排名前10的图像,绿色的编号表示查找正确,红色的编号表示查询错误。第三张图的CUHK-03的demo可以看到带查询图像特征很不明显,任务不清晰,且一框图片中可能存在多个人,为重识别一个很大的难点,目前来说,CUHK-03仍然是难度很大的数据集之一。