小白入门计算机视觉系列——ReID(三):进阶:学习分块局部特征
ReID(三):进阶:学习分块局部特征
小白入门系列是我和朋友准备一起做的一块内容,分模块分专题·,比如计算机视觉中的目标检测,ReID,OCR,语义分割以及大火大热的AutoML等等。
本次带来的是计算机视觉中比较热门的重点的一块,行人重识别(也叫Person ReID),车辆重识别和行人重识别类似,有很多的共同之处,所以以下统称该任务为ReID。
知乎:https://www.zhihu.com/people/bei-ke-er-1-34/activities
Github :https://github.com/lixiangwang/Person-ReID
1. 局部特征学习方法
早期的ReID研究,人们更多的方向的是全局特征,就像上一篇说的baseline一样,将整个图像作为网络的输入,通过学习网络的特征提取得到特征图谱。但是ReID任务的数据集是多样性的,有时候并不能得到完好的全身图像,而全局特征也忽略了图像本身的一些细粒度信息,所以,基于局部特征的ReID也是行人重识别研究的一个重要方向之一。
基于局部特征学习方法的ReID目前主要有两种做法,一种是利用人体的关键点定位,通过区域联结获取行人的姿态特征。Spindle Net是这种做法的一个代表网络,如图所示。

图中,蓝色部分为已经预训练好的RPN网络,用于获得人体的14个关键点,同时由14个关键点得到7个ROI块,完整的图像通过CNN网络提取特征,同时7个ROI块也通过相同的网络来提取特征,CNN网络之间参数共享。最终得到的8个特征以不同的尺度结合在一起,以这种融合特征的方式去做ReID的任务。
另一种主要的做法是区域分块,一般通过水平分块切分一个图像,每个part部分分别提取特征,最终也是联结到一起,去训练网络使得损失loss降低,模型的网络参数不断更新。区域分块的方式可以关注行人图片上的细节特征,相比于做关键点定位的姿态估计网络,有些图像数据并没有清晰的人像,因此很难做到关键点的定位,即使是定位了也可能不准确,导致模型的识别产生较大的误差。
2. PCB网络
基于卷积基线网络的分块(Part-based Convolutional Baseline,PCB) 网络来自于2018年ECCV的一篇论文:原文链接。该模型属于上面介绍的均匀切块方法,论文中将整个图像水平切成6块,6个部分被别用不同的loss来训练网络。PCB网络的结构如下图所示。
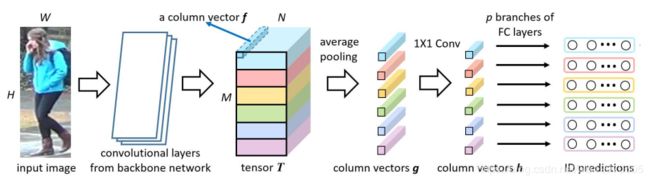
PCB网络的backbone 网络的选择有很多,在后面的实验中,backbone 网络采用上一篇构建的baseline网络。
由上图可以看到,经过骨干网络提取的特征后,原来的均值池化层和全连接层被移除,将特征图水平分成6个部分,再分别对每个部分做全均值池化,此时每个部分的维度为2048,再经过一个1*1的卷积核降维得到的特征块维度为256。最后,对6个softmax分类器进行了训练,分类的数量取决于训练集ID个数。测试时的向量为降维前的2048维向量串接降维后的256维向量。该网络使用交叉熵代价函数作为损失函数,而去掉最后一次的全均值池化,是为了增加细粒度的特征。
3. 计算结果分析(完整代码见作者GitHub)
实验的环境和前面一样,基于PyTorch框架,数据加载同样使用ImageFolder和 torch.utils.data.DataLoader接口,每个batch包装前的数据是打乱的,使用8个CPU线程来加载。预处理的方式按照论文给出的方式,如下:
transform_train_list = [
transforms.Resize((384,192), interpolation=3),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
transform_val_list = [
transforms.Resize(size=(384,192),interpolation=3), #Image.BICUBIC
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
所有的图像被resize为384*192大小,train set采用随机水平翻转的方式增强数据,将格式转换为tensor之后,对所有图像数据做正则化。
我们基于前面的baseline,按照论文思路做出PCB分块:
class PCB(nn.Module):
def __init__(self, class_num ):
super(PCB, self).__init__()
self.part = 6
model_ft = models.resnet50(pretrained=True)
self.model = model_ft
self.avgpool = nn.AdaptiveAvgPool2d((self.part,1))
self.dropout = nn.Dropout(p=0.5)
self.model.layer4[0].downsample[0].stride = (1,1)
self.model.layer4[0].conv2.stride = (1,1)
for i in range(self.part):
name = 'classifier'+str(i)
setattr(self, name, ClassBlock(2048, class_num, droprate=0.5, relu=False, bnorm=True, num_bottleneck=256))
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
x = self.model.layer2(x)
x = self.model.layer3(x)
x = self.model.layer4(x)
x = self.avgpool(x)
x = self.dropout(x)
part = {}
predict = {}
for i in range(self.part):
part[i] = torch.squeeze(x[:,:,i])
name = 'classifier'+str(i)
c = getattr(self,name)
predict[i] = c(part[i])
y = []
for i in range(self.part):
y.append(predict[i])
return y
class PCB_test(nn.Module):
def __init__(self,model):
super(PCB_test,self).__init__()
self.part = 6
self.model = model.model
self.avgpool = nn.AdaptiveAvgPool2d((self.part,1))
# remove the final downsample
self.model.layer4[0].downsample[0].stride = (1,1)
self.model.layer4[0].conv2.stride = (1,1)
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
x = self.model.layer2(x)
x = self.model.layer3(x)
x = self.model.layer4(x)
x = self.avgpool(x)
y = x.view(x.size(0),x.size(1),x.size(2))
return y
在运行一个epoch的时间上比较如下表(基于Market-1501)

可以看出,PCB方法的训练时间远比基线网络的要长,这是由于局部特征的分块计算。每一个part损失函数都不一样,计算量更大,同时,加入了几个策略,REA为数据扩展方法,增加了数据,而dropout等策略则增加了计算量,因而耗费了更多的训练时间。
对模型参数的实验是ReID任务的重要步骤,原论文中并没有给出所有的参数设置,所以需要我们的实验和调整。由于GPU显存为8G,所以我们的batchsize规定为32,对于epochs,我们做了多组实验,以top1和mAP作为主要指标,结果如图。

对于分块参数P的讨论,实验结果如下(基于Market-1501)。

对于指标mAP和Rank-1,分别做了两组实验,一个是基于基本骨干网络的PCB,即没有加入第三章的策略,一个是加入了第三章的训练策略。由于Re-ranking可以较大幅度的提高mAP,而我们更关注的是训练算法和模型本身,所以计算结果并没有做重排序。
从图可以看出,我们的tricks对模型的性能是有着较大提升的,同时,分块参数P=6时,模型的性能最佳。也就是说,原始的行人照片被分成六等份。从直观上的理解来看,6等份恰好可以适当的表示行人的6部分特征,而再细分的话,可能在语义上就重复了,比如一个人的小腿都被划成了几小块,实际上,小腿作为一个特征去训练似乎是最合理的。

上图为在Market-1501数据集上,训练过程的可视化,我们训练了80个epochs的数据,初始学习率为0.05,在第30个epochs时的学习率降为0.005,可以看到,loss有个突降,当学习率被调小时,相当于梯度下降的步长变得更小,寻找最优解变得更仔细,说明模型进入了更为细致的学习。在第60个epochs时候降为0.0005,可以看出,loss已经基本不变了,说明了模型的学习到了极限。观察train loss和val loss,整个过程中,无论tran loss是下降还是不变,val loss都没有上升,说明了模型没有发生过拟合,我们的tricks是有效的。
模型在三个数据集上的评测结果如下:

从上表可以看出,基于局部特征的PCB方法相对于基线网络的全局特征学习,具有更好的搜索效果,局部特征更关注图像的细节,而在PCB方法中,我们在测试的时候结合了降维前的特征分块和降维后的特征分块,而不是仅仅用降维后的特征分块训练,也保证了特征图谱中细粒度的特征不会被丢失。从表中还可以看出,我们的tricks对model性能的改进也很有帮助。
下面给出基于我们的baseline的PCB模型在三个数据集(Market-1501、DukeMTMC-reID和CUHK-03)上搜索目标行人的一个demo。


