Q:有些学习器强,有些学习器弱,有没有方法让弱的学习器战胜强的学习器?
所谓“弱学习器”,就是指性能比起随机猜测高一点的学习器,比如弱分类器就是指分类准确率比50%高一点的分类器。俗话说:“三个臭皮匠,赛过诸葛亮”。我们可以通过某种“合作制度”,使得多个弱学习器结合起来一起进行分类(回归),获得甚至高于强学习器的学习性能。这被称为集成学习(ensemble learning)。
Q:用于集成学习的每个个体学习器如何生成?
集成学习的个体学习器有两类生成方式:串行生成和并行生成。串行生成指学习器一个接一个生成,后面的个体学习器基于前面的个体学习器的情况生成;并行生成是所有用到的学习器一起生成,不分先后。显然串行方式相对来说比并行方式更耗时间。串行生成的代表算法是Boosting算法家族中的AdaBoost,并行生成的代表算法是Bagging算法,而其变体算法Random Rorest 最为著名和常用。
Q:AdaBoost算法的基本思想是怎样的?
首先我们想一下现实生活中的经历——我们在学习的时候,尤其是初高中学习模式中,总是会有听课-测验-总结测验结果-重点学习测验中做错的知识点这样的学习模式。
Boosting算法的基本思想和上面的学习模式很像。Boosting算法要做的事情就是用同一个训练数据集,训练出n个弱学习器,然后把这n个弱学习器整合成一个强学习器。其学习过程也是:首先根据原始的数据集训练出第一个学习器,然后根据学习器的学习结果,看看这个学习器在哪些样本上犯了错。然后下一轮训练时给在上一轮犯错的样本给予更多的关注,训练出一个新的学习器。
AdaBoost是Boosting算法家族中著名的算法之一。算法会对训练数据集里每一个样本赋予一个权值。然后开始了n轮的训练,第一轮的时候每个样本的权值都是均等的,假设训练数据集有m个样本,则每个样本权值都是。用这些数据和权值可以训练出第一个学习器(一般是决策树算法)。
用数学语言来描述的话,假设单个基学习器为其对应的权重为,则集成后的学习器为
Q:那么AdaBoost中每个基分类器亦即对应的权重如何求得?
我们现在只考察二分类任务。在开始探究AdaBoost的算法流程之前,首先要搞清楚几个概念,或者说在西瓜书里容易混淆的符号:
- —— 基学习器,用于集成学习器的基本元素,最常用的是单层决策树。
- —— 集成学习器中每个基分类器的权重
- —— 集成学习器,多个基学习器预测结果的加权求和。
- —— 样本x的真实值(真实标记)。
- —— 训练数据集。
- —— 第t轮训练中样本x对应的权重w。
- —— 原分布在当前样本权重下形成的新分布。
AdaBoost是一个迭代算法,每一轮要做的事情是在当前的样本权重下,用训练数据训练出一个基学习器,亦即对应的学习器权重,最后确定下一轮学习的样本权重。
先看基分类器。
机器学习(更准确一点,参数化模型训练)的一个讨论时设定一个损失函数,然后最小化这个损失函数,以获得一组能使预测结果最好的模型参数。对于AdaBoost,损失函数被定义为:
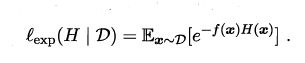
那么第t轮训练中,基学习器应当能训练目标就是和前面t-1个学习器一起令总体损失最小:
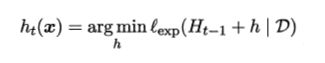
将上面公式展开,再变形,就能得到下面新的损失函数,含义是在当前样本权重下使得分类器的损失最小。也可以理解为在新分布下最小化错误率。本质上就是关注前面几轮都误判的样本,使得这一轮生成的分类器能尽可能正确预测这些困难的样本。
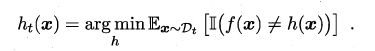
再看基分类器权重。
从上面分析可知,(t>2)的训练数据不再是呈原分布D,而是经过权重调整过后的新分布。则应该使得最小化指数损失函数

最后决定下一轮的样本权重。权重更新的指导思想就是,这一轮被误判的样本,要在下一轮获得更多的关注:
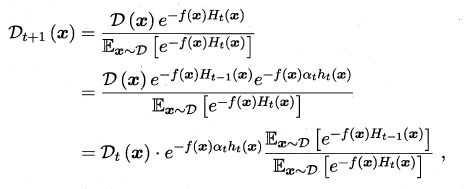
如此我们就有知道了训练一个AdaBoost集成学习器的全流程。贴一张AdaBoost算法总体流程的伪代码:

更多关于Adaboost算法的知识,比如应用于回归问题的AdaBoost,可以看看这篇博文。
Q:Bagging和Random Forest算法的大致内容如何?
Bagging算法的思想很简单——假设现在有含m个样本的样本数据集D。对D进行m次有放回抽样,得到一个含m个样本的训练数据集T。根据概率,D中有约63%的样本被抽到T中(部分会重复出现)。进行数次这样的操作,得到数个训练集。用这n个训练集可以训练出n个不同的个体学习器。
Random Forest算法是基于Bagging算法的扩展——以决策树为个体学习器的集成学习器算法。除此以外,一般的,单个的决策树在构建树的节点时,会在所有可选属性中选择最优的属性作为节点的划分属性。而随机森林中的决策树在构建树的节点时,会先在所有可选属性中随机选择k个属性出来,然后选出这k个属性中最优的属性作为当前节点的划分属性。假设数据集一共有d个属性,西瓜书推荐。显然,随机森林中的每一棵性能都比一般的决策树性能弱,但是许多棵这样的决策树形成森林后,其总体性能则大大强于一般的决策树了。
Q:现在有了多个个体学习器,有哪些“合作规则”让多个弱学习器一起工作?
对于分类任务,最简单的就是投票法,看看哪一个类别得到更多学习器的支持,就把待分类任务归到哪一个类别,如果同时有两个或以上类别得到同样多票数,则从这几个类别中随机选一个,这叫相对投票法。也有绝对投票法,即把待分类样本归属到得票多于半数的那一个类别。如果没有一个类别得票多于半数,则拒绝本次预测,即待分类样本不归属到任何一个类别。另外还有加权投票法,给每一个学习器加一个权值,表示各个学习器票数的重要度,再进行绝对或相对投票。
对于预测任务,或者说输出是连续值的任务,最简单的是用平均法,有简单平均法,即各个学习器的结果直接取平均;也可以用加权平均法,同样给各个个体学习器加一个权值,然后将各个结果乘上相应权值再取平均。
当数据量足够多时,可以考虑更加强大的合作规则——学习法,亦即把各个个体学习器的输出结果当作一个新的数据集,通过一个新的学习算法得到一个新的学习器。如果把前两种合作规则看作是一群人讨论得出结果,那么“学习法”就是一群人把他们的知识经验全部传授给一个学生,由这个接受了多人功力的学生(实际上就是一个强学习器了)来做判断。
学习法最典型的算法是stacking算法。假设现在有一个数据集D,先把数据集分成两部分,一部分用来训练初级学习器(个体学习器),可以用于boosting或者bagging的训练方式。另一部分则作为输入,喂给训练出来的每个个体学习器,从而得到输出,形成一个新的数据集——这个新的数据集中每个样本有n个属性和1个标记,对应n个个体学习器的输出结果,以及原来的喂给个体学习器的数据集中每个样本的标记。
用这个新的数据集作为训练集,训练出一个新的学习器,这个学习器就是最终的集成学习器。这个最终的学习器一般使用线性回归算法来训练。
Talk is cheap, show me the code!
下面的代码是一个只支持二分类任务的AdaBoost集成分类器。
"""
Simple AdaBoost Classifier
:file: ensemble.py
:author: Richy Zhu
:email: [email protected]
"""
import copy
import numpy as np
class MyAdaBoostClassifier:
def __init__(self, base_learner=None, max_learners=100):
'''
Create an AdaBoosted ensemble classifier
(currently only do binary classification)
Parameters
----------
base_learner: object
weak learner instance that must support sample weighting when
training suppport fit(X, y, sample_weight), predict(X),
and score(X, y) methods. By default use `DecisionTreeClassifier`
from scikit-learn package.
max_learners: int
maximum number of ensembled learners
'''
if base_learner is None:
from sklearn.tree import DecisionTreeClassifier
base_learner = DecisionTreeClassifier(max_depth=1)
# base learner must support sample weighting when training
self.learners = [copy.deepcopy(base_learner) for k in range(max_learners)]
self.alphas = [0] * max_learners # weights of each learner
def fit(self, X, y):
'''
Build an AdaBoosted ensemble classifier
Parameters
----------
X: ndarray of shape (m, n)
sample data where row represent sample and column represent feature
y: ndarray of shape (m,)
labels of sample data
Returns
-------
self
trained model
'''
# weights of each training sample
weights = np.ones(len(X)) * (1/len(X))
for k in range(len(self.learners)):
self.learners[k].fit(X, y, sample_weight=weights)
y_hat = self.learners[k].predict(X)
err_rate = 1 - self.learners[k].score(X,y)
if err_rate > 0.5:
break
alpha = 0.5 * np.log((1-err_rate)/(err_rate))
self.alphas[k] = alpha
weights = weights * np.exp(-alpha * y * y_hat)
weights /= sum(weights)
self.learners = self.learners[:k+1]
self.alphas = np.array(self.alphas[:k+1]).reshape([-1,1])
return self
def predict(self, X, func_sign=None):
'''
Make prediction by the trained model.
Parameters
----------
X: ndarray of shape (m, n)
data to be predicted, the same shape as trainning data
func_sign: function
sign function that convert weighted sums into labels
Returns
-------
C: ndarray of shape (m,)
Predicted class label per sample.
'''
if func_sign is None:
def func_sign(x):
return np.where(x<0, -1, 1)
Y = []
for learner in self.learners:
Y.append(learner.predict(X))
Y = np.array(Y)
# weighted sum of result from each classifier
y = np.sum(Y * self.alphas, axis=0)
return func_sign(y)
测试代码如下,对于比scikit-learn的模型效果更好,我也很惊奇。但sklearn的模型能处理更稳定,也能处理更多情况,这一点还是要服产品级代码。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from ensemble import *
print('\nAdaBoost')
print('---------------------------------------------------------------------')
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
y_train[y_train==0] = -1
y_test[y_test==0] = -1
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=1)
myada = MyAdaBoostClassifier(tree)
myada.fit(X_train, y_train)
print('My AdaBoost:', accuracy_score(y_test, myada.predict(X_test)))
from sklearn.ensemble import AdaBoostClassifier
skada = AdaBoostClassifier(n_estimators=100, random_state=0)
skada.fit(X_train, y_train)
print('Sk AdaBoost:', accuracy_score(y_test, skada.predict(X_test)))
结果如下
$ python ensemble_examples.py
AdaBoost
---------------------------------------------------------------------
My AdaBoost: 0.952
Sk AdaBoost: 0.936
相比于AdaBoost那看上去比较复杂的数学公式实现,Random Forest的机制更加清晰简单,代码编写也更加容易(顺利...)
"""
Simple Random Forest, use decision tree model in scikit-learn package.
:file: ensemble.py
:author: Richy Zhu
:email: [email protected]
"""
import copy
import numpy as np
from collections import Counter
class MyRandomForestClassifier:
def __init__(self, n_learners=100):
from sklearn.tree import DecisionTreeClassifier
base_tree = DecisionTreeClassifier(max_features='log2')
self.learners = [copy.deepcopy(base_tree) for k in range(n_learners)]
def fit(self, X, y):
'''
Build an random forest classifier
Parameters
----------
X: ndarray of shape (m, n)
sample data where row represent sample and column represent feature
y: ndarray of shape (m,)
labels of sample data
Returns
-------
self
trained model
'''
for learner in self.learners:
new_index = np.random.choice(range(len(X)), int(0.6*len(X)), replace=False)
new_X = X[new_index]
new_y = y[new_index]
learner.fit(new_X, new_y)
return self
def predict(self, X):
'''
Make prediction by the trained model.
Parameters
----------
X: ndarray of shape (m, n)
data to be predicted, the same shape as trainning data
func_sign: function
sign function that convert weighted sums into labels
Returns
-------
C: ndarray of shape (m,)
Predicted class label per sample.
'''
Y = []
y = []
for learner in self.learners:
Y.append(learner.predict(X))
Y = np.array(Y)
for i in range(Y.shape[1]):
counter = Counter(Y[:, i])
y.append(counter.most_common(1)[0][0])
return np.array(y)
测试一下
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from ensemble import *
print('\nRandom Forest')
print('---------------------------------------------------------------------')
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
y_train[y_train==0] = -1
y_test[y_test==0] = -1
myforest = MyRandomForestClassifier()
myforest.fit(X_train, y_train)
# print(myforest.predict(X_test))
print('My forest:', accuracy_score(y_test, myforest.predict(X_test)))
from sklearn.ensemble import RandomForestClassifier
skforest = RandomForestClassifier()
skforest.fit(X_train, y_train)
print('SK forest:', accuracy_score(y_test, skforest.predict(X_test)))
结果如下
$ python ensemble_examples.py
Random Forest
---------------------------------------------------------------------
My forest: 0.956
SK forest: 0.956
更多代码请参考https://github.com/qige96/programming-practice/tree/master/machine-learning
本作品首发于 和 博客园平台,采用知识共享署名 4.0 国际许可协议进行许可。