Learning Tree-based DeepModel for Recommender Systems
摘要
已经研究了用于推荐系统的基于模型的方法以提供更精确的结果。在具有
大型语料库的系统中,预测所有用户 - 项目对的偏好的学习模型的计算量是巨大的,这使得该模型难以直接用于候选推荐生成阶段。为了克服计算障碍,像矩阵分解这样的模型可以采用内积形式(即用用户和项目的潜在因素的内积作为偏好)和像哈希这样的索引执行有效的近似k-最近邻搜索。但是,其他由于计算量大,用户和项目特征之间的
表达性交互形式(例如,通过高级深度神经网络的交互)仍然被阻止从大的语料库推荐。在本文中,我们着重讨论如何引入
任意先进模型来从大型语料库中生成推荐的问题。我们提出了一种新的基于树的方法,它可以提供对数复杂度预测关于语料库大小与更深层的神经网络。树型模型的
主要思想是通过自上而下遍历树节点并决定是否将每个节点提供给用户来预测用户兴趣从粗到精。此外,我们还表明,树结构也可以共同学习,以更好地符合用户兴趣的分布,以促进培训和预测。在两个大型实际数据集中的实验表明,所提出的模型显着优于传统方法。在淘宝展示广告平台上的在线A / B测试结果证明了基于树的深度模型在生产中的有效性。
CCS概念
•计算方法→分类和回归树;神经网络;
•信息系统→推荐系统;
关键词基于树的学习,推荐系统,隐式反馈
1引言
推荐已被各种内容提供商广泛使用。
个性化推荐方法基于用户的兴趣可以从其历史行为或具有类似偏好的其他用户推断出的直觉,已被证明在YouTube [6]和亚马逊[18]中有效。设计这样的推荐模型以
从每个用户的整个语料库中预测最佳候选集合具有许多挑战。在拥有庞大语料库的系统中,一些效果良好的推荐算法可能无法从整个语料库中进行预测。线性预测复杂度w.r.t.语料库的大小是不可接受的。部署这样的大规模推荐系统需要对每个用户的预测计算量进行限制。除了精确性之外,推荐项目的新颖性也应该对用户体验负责。预期只包含具有用户历史行为的同类项目的结果。
为了减少计算量和处理庞大的语料库,
基于内存的协作过滤方法在工业中得到广泛应用[18]。作为协作过滤家族的一种代表性方法,基于项目的协同过滤[26]可以根据预先计算的项目对之间的相似度以及使用用户的历史行为作为触发器回忆那些最相似的项目,从非常大的语料库推荐计算相对较少的计算项目。然而,对候选集合的范围存在限制,即不是所有的项目,而只是与触发器相似的项目可以被最终推荐。这种直觉阻止了推荐系统跳出历史行为来探索潜在的用户兴趣,这限制了召回结果的准确性。而且在实践中,推荐新颖性也受到了批评。
另一个减少计算的方法是制作粗糙的推荐。例如,系统为用户推荐少量的项目类别,并挑选出所有相应的项目,并进行以下排序阶段。但是,对于大型语料库,计算问题仍未解决。如果类别编号很大,类别推荐本身也包含计算障碍。如果不是,一些类别将不可避免地包含太多项目,使得以下排名计算不可行。此外,所使用的类别通常不是针对推荐问题设计的,这会严重损害推荐的准确性。
在推荐系统的文献中,
基于模型的方法是一个活跃的话题。诸如
矩阵分解(MF)[15,25]等模型试图将成对的用户项目偏好(例如评级)分解为用户和项目因素,然后向每个用户推荐其最偏爱的项目。
因子分解机(FM)[23]进一步提出了一种统一的模型,它可以用任何类型的输入数据来模拟不同的分解模型。在一些没有明确偏好但只有隐式用户反馈(例如用户行为如点击或购买)的现实世界情景中,
贝叶斯个性化排名[24]给出了一个解决方案,
该偏好用偏序排列的三元组形式表示,并将其应用于MF楷模。在行业中,YouTube使用深度神经网络[6]来学习用户和项目的嵌入,其中两种嵌入是根据相应的功能单独生成的。在以上所有方法中,
用户 - 项目对的偏好可以表示为
用户和项目向量表示的内积。因此,预测阶段相当于在内积空间中检索用户矢量的最近邻居。对于矢量搜索问题,像近似k-最近邻(kNN)搜索的散列或量化[14]等指标可以确保检索效率。
然而,用户与项目向量表示之间的内在产品交互形式严重限制了模型的能力。还有其他一些更具表现力的交互形式,例如,用户的历史行为与候选项目之间的跨产品特征被广泛用于点击率预测[ 4]。最近的工作[11]提出了一种神经协同过滤方法,其中
使用神经网络而不是内积来模拟用户和项目的向量表示之间的交互。该工作的实验结果证明,多层前馈神经网络比固定内积算法更好。深度兴趣网络[28]指出用户兴趣是多样的,像网络结构这样的关注可以根据不同的候选物品。除上述工作外,其他方法如产品神经网络[22]也证明了先进神经网络的有效性。然而,由于这些模型不能用于用户和项目向量之间的内部产品以利用高效的近似kNNsearch,所以它们不能用于在大规模推荐系统中召回候选者。如何克服计算障碍使任意先进神经网络在大规模推荐中可行是一个问题。
为了解决上述挑战,本文提出了一种新颖的基于树的深度推荐模型(TDM)。
基于树和树的方法在多类分类问题[1,2,5]和语言模型[20]中进行了研究,但是研究人员很少涉足使用树结构的推荐系统。实际上,信息的层次结构普遍存在于许多领域。例如,在电子商务场景中,iPhone是细粒度的产品,而智能手机则是iPhone所属的粗粒度概念。所提出的TDM方法利用了这种信息层次并将推荐问题转化为一系列分层分类问题。通过解决从容易到困难的问题,TDM可以提高准确性和效率。我们的论文的主要贡献总结如下:
•据我们所知,TDM是第一种使用任意先进模型从大型语料库生成推荐的方法。受益于分层树搜索,TDM可以计算对数量的计算量。进行预测时的语料库大小。
•TDM可以更精确地帮助您找到新颖而有效的推荐结果,因为整个语料库已被探索,更有效的深度模型也可以帮助您找到潜在的兴趣。
•除了更先进的模型之外,TDM还通过分层搜索提高了推荐的准确性,将大问题分解为更小的问题,并逐次从容易到困难地解决问题。
•作为一种指标,还可以通过学习树结构来实现项目和概念的最佳层次结构,以便更有效地进行检索,从而促进模式训练。我们采用树学习方法,允许联合训练神经网络和树结构。
•我们对两个大规模真实世界的数据集进行了广泛的实验,显示TDM显着地执行现有方法
它也指出基于树的方法也在语言模型工作分层softmax [20]中进行了研究,但它不同于提出的TDM不仅仅是动机,而且也在制定中。在接下来的单词预测问题中,传统的softmax必须计算归一化项来获得任何单个字的概率,这非常耗时。
分层softmax使用树结构,并且
下一个字的概率被转换为沿着树路径的节点概率的乘积。这种表述将下一个字的概率的计算复杂度降低到对数幅度w.r.t.语料库的大小。然而,在推荐问题中,目标是在整个语料库中搜索那些最喜欢的项目,这是一个检索问题。在分层softmax树中,最优的父节点不能保证最优的低层节点在它们的后代,并且仍然需要遍历所有条目才能找到最优节点。因此,它不适合这样的检索问题。为了解决检索问题,我们
提出了一个像树型一样的最大堆,并引入了深度神经网络来对树进行建模,这对于大规模推荐来说是一种有效的方法。以下部分将展示其在制定方面的差异及其在性能上的优势。此外,分层softmax采用单一隐含层网络来处理特定的自然语言处理问题,而提出的TDM方法可用于任何神经网络结构。
所提出的
基于树的模型是各种在线内容提供者的通用解决方案。本文的其余部分安排如下:第2部分,我们将介绍淘宝展示广告的系统架构,以展示所提出的方法的位置。第3节将对所提议的基于树的深度模型进行详细介绍和形式化。接下来的第4节将介绍基于树的模型如何在线服务。第5节给出了大规模基准数据集和淘宝广告数据集的实验结果。最后,第6节给出了我们的工作结论。
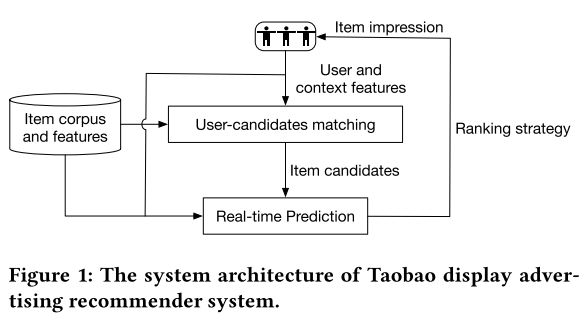
2 SYSTEMARCHITECTURE
在本节中,我们将介绍
淘宝显示广告推荐系统的体系结构,如图1所示。在接收到用户的页面查看请求后,系统使用
用户特征,
上下文特征和
项目特征作为输入来生成相对小得多的集合(通常为数百)来自匹配服务器中整个语料库(数亿个)的候选项目。基于树的推荐模型在这个阶段需要付出努力,并将候选集的大小缩小几个数量级。
有数百个候选项目,实时预测服务器使用更具表现力但更耗时的模型[28]来预测点击率或转换率等指标。并且在按策略[29]进行排序后,几个项目最终受到用户。
如前所述,所提出的推荐模型
旨在构建具有数百个项目的候选集合。这个阶段是必不可少的,也很困难。用户是否对所生成的候选人感兴趣会给出印象质量的上限。如何从整个语料库中抽取候选人的称重效率和效率是一个问题。
3基于树的深度模型
在这部分,我们首先介绍在我们的树型模型中使用的树结构,给出一个整体的概念。其次,我们引入分层softmax [20]
来说明为什么它的公式不适合推荐。之后,我们给出了一个像树型一样的新型最大堆,并展示了如何训练基于树的模型。然后介绍深度神经网络体系结构。最后,我们展示如何构建和学习基于树的模型中使用的树。
3.1推荐树
推荐树由一组节点N组成,其中N = {n1,n2,...,n | N |}表示| N |个体非叶或叶节点。除根节点以外的N中的每个节点都有一个父节点和一个任意数量的子节点。具体而言,语料库C中的每个项目ci对应于树中唯一的一个叶节点,而那些非叶节点是粗粒度概念。不失一般性,我们假设noden1总是根节点。举个例子树在图2的右下角示出,其中
每个圆圈表示一个节点并且节点的数量是它在树中的索引。该树总共有8个叶节点,每个叶节点对应于语料库中的一个itemin。尽管给出的例子是一个完整的二叉树,但我们并没有强加完整的和二元的作为我们模型中树的类型的限制。
3.2相关工作
在树结构中,我们首先介绍相关的工作层级softmax,以帮助理解它与我们的TDM的区别。在分层softmax中,树中的每个叶节点n都具有从根节点到节点的唯一编码。例如,如果我们将1编码为选择左分支,将0编码为选择右分支,则图2中树中的n9编码为110,n15的编码为000.将bj(n)表示为级j中节点n的编码。在分层softmax的表达式中,给定上下文的下一个字的概率被推导为
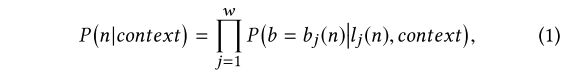
其中w是叶节点n的编码长度,lj(n)是n级的祖先节点。
以这种方式,
分层softmax通过避免常规softmax中的归一化项(语料库中的每个词需要被遍历)来解决概率计算问题。然而,
为了找到最可能的叶子,该模型仍然需要遍历整个语料库。沿树路径遍历每个级别的最可能节点自顶向下不能保证成功检索最佳叶节点。因此,分层softmax公式不适合大规模检索问题。另外,根据等式1,树中的每个非叶节点被训练为二元分类器以区分其两个子节点。但是如果树中有两个节点是邻居,它们可能是相似的。在推荐场景中,用户可能对两个孩子都感兴趣。
分层softmax模型的重点在于区分最优和次优选择,这可能会
失去区分全局视图的能力。如果使用贪婪的束搜索来检索那些最可能的叶节点,那么
一旦在树的上层进行了糟糕的决策,该模型可能无法在较低级别的低质量候选者中找到相对更好的结果。 YouTube的工作[6]也报告说,他们尝试使用分层softmax来学习用户和项目嵌入,但它比采样softmax [13]的方式表现更差。
鉴于分层softmax的公式不适合大规模推荐,我们在下一节中提出了一种新的树模型公式。
3.3基于树的模型制定
为了解决最优先项目的有效top-k检索问题,我们提出了一个像树概率公式那样的最大堆。像树这样的最大堆是一种树结构,其中j级中的每个非叶节点n对于每个用户u满足以下等式:
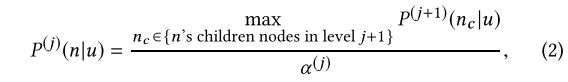
其中
P(j)(n | u)是用户u对n感兴趣的地面真实概率。
α(j)是层级j的层特定标准化项,以确保层级中的概率和等于1.请注意,表示u不仅表示特定用户,还包含用户状态,如历史行为。等式2说
父节点的地面真实偏好等于其子节点的最大偏好,除以正规化项。
目标是找到具有最大偏好概率的k个叶节点。假设树中有每个节点n的基本事实P(j)(n|u),我们可以在层次上检索出具有最大偏好概率的k个节点,并且只需要探索每个层次顶k的子节点。在这种情况下,可以最终检索前k个叶节点。实际上,在上述检索过程中,我们不需要知道每个树节点的确切的地面真实概率。我们需要的是每个级别的概率顺序,以帮助查找关卡中的前k个节点。基于这种观察,我们使用
用户的隐式反馈数据和神经网络来训练每个级别的鉴别器,其可以说明
偏好概率的顺序。假设用户u与叶节点nd有交互作用,即nd是u的正样本节点。它表示一个订单P(m)(nd | u)> P(m)(nt | u),其中m是叶子的等级,nt是任何其他叶子节点。在任何级别j中,表示lj(nd)为j级的祖先。根据公式2中树的表达式,我们可以导出P(j)(lj(nd)| u)> P(j)(nq | u),其中nq是级j中除lj(nd) 。在以上分析的基础上,我们可以使用
负面抽样[19]来训练每个级别的阶次鉴别器。详细来说,与用户u有交互作用的叶节点及其祖先节点构成用户每层的正样本集合。并且随机选择的节点除了每个级别中的正节点构成负样本的集合。图2中的绿色和红色节点给出了采样示例。然后将这些样本输入到二进制概率模型中以得到各级的阶次鉴别器。我们使用一个具有不同输入节点特征的全局深度神经网络二进制模型用于所有级别的阶次鉴别器。可以采用任意先进的神经网络来提高模型能力。
将Y + u和Y-u表示为用户u的正和负样本的集合。似然函数的推导如下:
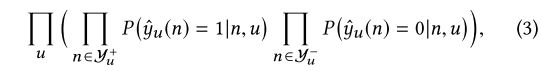
其中yu(n)是给定用户u的节点n的预测标签。
相应的损失函数是
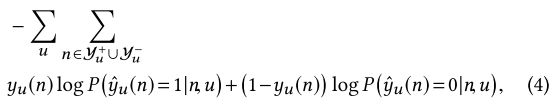
其中yu(n)是给定用户u的节点n的地面真值标签。
注意,所提出的
抽样方法与分层softmax中的底层抽样方法有很大不同。与分层softmax中使用的导致模型区分最优和次优结果的方法相比,我们在
每个正节点随机选择相同水平的负样本。这种方法使每个级别的鉴别器成为一个
全局内部的鉴别器。每个级别的全局鉴别器都可独立进行精确决策,而不依赖于上级决策的优劣。全局鉴别能力对于分层推荐方法非常重要。它可以确保即使模型做出了错误的决策并且低质量的节点泄漏到高层候选集中,那么相对更好的节点而不是非常糟糕的节点可以通过以下级别的模型进行选择。
给定一个推荐树和一个优化模型,在
算法1中描述了详细的层次预测算法。检索过程是分层和自上而下的。假设所需的候选项目号是k。对于大小为| C |的语料库C,最多遍历2 * k * log | C |节点可以在完整的二叉树中得到最终的建议集。需要遍历的节点数量是对数关系w.r.t.语料库大小,这使先进的二进制概率模型成为可能。

我们提出的
TDM方法不仅减少了预测时的计算量,而且与所有叶节点中的强力搜索相比,还具有
提高推荐质量的潜力。
如果没有树,直接找到最优项的训练模型是一个难题,因为语料库的大小。使用树层次结构,大规模推荐问题被分解为许多较小的问题。在树的高层只存在少量节点,因此歧视问题更容易。高层做出的决策会优化候选集,这可能有助于降低层次,从而做出更好的判断。 5.4节中的实验结果表明,提出的分层检索方法比直接蛮力搜索更好。
3.4 DeepModel
在下面的部分中,我们将介绍
深度模型的使用。受到
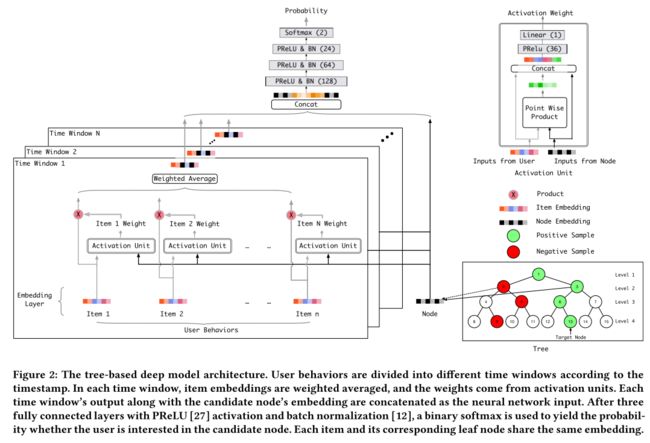
点击率预测工作[28]的启发,我们学习树中每个节点的低维嵌入,并使用注意模块轻松搜索相关行为以获得更好的用户表示。为了利用包含时间戳信息的用户行为,我们设计了
区块式输入层来
区分位于不同时间窗口中的行为。历史行为可以沿时间轴分为不同的时间窗口,每个时间窗口中的迭代嵌入加权平均。注意模块和下面的网络大大加强了模型的能力,并且也使得用户对候选项目的偏好不能调整为内部产品形式。
树节点和树结构本身的嵌入也是模型的一部分。 Tominimize Loss 4,采样的节点和相应的特征用于训练网络。注意,我们仅仅示出了图2中的用户行为特征的用法以简化,而其他特征例如用户简档或上下文特征可以没有障碍地使用在实践中。
3.5树的构建和学习
推荐树是基于树的深度推荐模型的基础部分。在分层softmax [20]中,词层次结构是根据WordNet的专家知识构建的[17]。在推荐场景中,并非每个语料库都可以提供特定的专业知识。一种直观的交替方式是根据从数据集中得出的项目一致性或相似性,
使用层次聚类方法构建树。但是聚类树可能相当不平衡,这对训练和检索是不利的。由于成对项目的相似性,算法[1]给出了一种通过
谱聚类递归地将项目分成子集的方法[21]。然而,对于大规模语料库,谱聚类不够可扩展(立体时间复杂度w.t.t。语料库大小)。在本节中,我们将重点放在
合理可行的树木建设和学习方法上。
树初始化。既然我们假设树代表了用户兴趣的分层信息,那么以类似的项目组织在相近位置的方式来构建树是很自然的。鉴于类别信息在许多领域都有广泛的应用,我们直观地提出了一种
利用项目类别信息来构建初始树的方法。在不失一般性的情况下,本节以二叉树为例。首先,我们随机地对所有类别进行排序,并将属于同一类别的项目放在类别内的随机顺序中。如果一个物品属于一个类别以上,则该物品被分配给随机的物品以获得唯一性。通过这种方式,我们可以获得排名项目的列表。其次,
这些排序的项目被递归地减半为两个相等的部分,直到当前集合仅包含一个项目,这可以构建自上而下的
接近完整的二叉树。上述的基于类别的初始化可以在我们的实验中获得比完整的随机树更好的层次和结果。
树学习。作为模型的一部分,可以在模型训练之后学习每个叶节点的嵌入。然后,我们使用学习的叶节点的嵌入向量来聚类新的树。考虑到语料库的大小,我们使用
k-means聚类算法来实现其良好的可扩展性。在每一步中,根据它们的嵌入向量将项目聚类为两个子集。注意,为了更均衡的树,这两个子集调整为相等。当只剩下一个项目时,递归停止,并且二叉树可以以这种自顶向下的方式构建。在我们的实验中,当使用单个机器的语料库大小约为4百万时,需要大约一个小时才能构建这样的聚类树。第五部分的实验结果将显示给定树学习算法的有效性。深层模型和树结构以另一种方式共同学习:1)构建初始树并训练模型; 2)学习基于经过训练的叶节点的嵌入来获得新的树结构; 3)再次用学过的树训练模型。
4在线服务
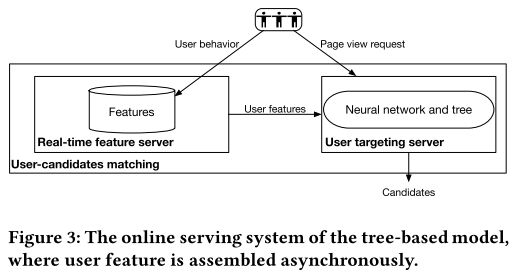
图3说明了本方法的在线服务系统。输入要素组装和项目检索分为两个异步阶段。包括点击,购买和将商品添加到购物车中的每个用户行为都将触发实时特征服务器以组装新的输入特征。一旦接收到页面查看请求,用户定位服务器将使用预先组装的特征从树中检索候选项。如算法1中所述,检索是分层的,并且使用训练的神经网络来计算给定输入特征的节点是优选节点的概率。
5实验研究
我们在本节中研究提议的基于树的模型的性能。介绍MovieLens-20M [10]和淘宝广告数据集UserEventBehavior的实验结果。在实验中,我们将所提出的方法与其他现有方法进行比较,以显示模型的有效性,实证研究结果显示了基于树的模型和树学习算法是如何工作的。
5.1数据集
这些实验在两个具有时间戳的大规模真实世界数据集中进行:1)用户从MovieLens [10]查看数据的电影; 2)来自淘宝的用户项目行为数据集称为UserBehavior。
详细信息:
MovieLens-20M:它包含此数据集中带有时间戳的用户电影评级。当我们处理隐含的反馈问题时,通过保持4或更高的等级来将这些符号二值化,这在其他作品中是常见的方式[7,16]。此外,只有观看至少10部电影的用户才会被保留。为了创建训练,验证和测试集,我们随机抽样1,000个用户作为测试集,另有1,000个用户作为验证集,其余用户构成训练集[7]。对于验证和测试集,沿时间线的用户电影视图的前半部分被视为已知行为来预测后半部分。
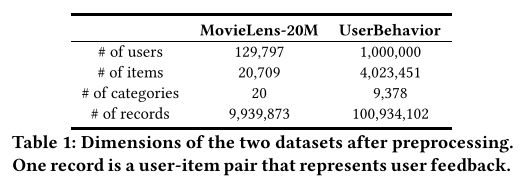
UserBehavior:这个数据集是淘宝用户行为数据的一个子集。我们在2017年11月25日至12月3日期间随机选择了至少有10种行为的用户,其中包括点击,购买和添加项目等至少10种行为。数据的组织方式与MovieLens-20M非常类似,即,项目行为由用户标识,项目标识,项目的类别标识,行为类型和时间戳组成。因为在MovieLens-20M中,随机选择10,000个用户作为测试集,另一个随机选择的10,000个用户为验证集。商品类别来自淘宝网当前商品分类的底层。表1总结了预处理后上述两个数据集的主要维度。
5.2度量和比较方法
为了评估不同方法的有效性,我们使用Precision @ M,Recall @ M和F-Measure @ M指标[16]。将用户u的召回的一组项目推导为Pu(| Pu | = M),并将用户的基本事实设置为Gu。 Precision @ M和Recall @ M都是
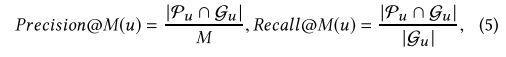
并且F-Measure @ M是
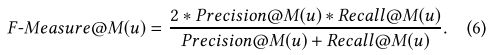
正如我们强调的那样,
推荐结果的新颖性对用户体验负责。现有的工作[3]提供了几种方法来衡量建议物品清单的新颖性。按照其定义之一,Novelty @ M被定义为
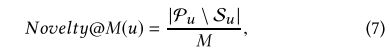
其中Su是在推荐之前与用户u进行交互的一组项目。测试集中上述四个指标的用户平均值用于比较以下方法:
•FM [23]。 FM是一个分解任务的框架。我们使用由xLearn1项目提供的FM的实现。
•BPR-MF [24]。我们使用其
矩阵分解形式进行隐式反馈推荐。使用由[9]提供的BPR-MF的实现。
•Item-CF [26]。基于项目的协同过滤是大规模语料库生产中使用最广泛的个性化推荐方法之一[18]。这也是淘宝网的主要候选人生成方法之一。我们使用Alibabamachine学习平台提供的项目CF的实现。
•YouTube产品-DNN [6]是YouTube提出的深度推荐方法。 Sampled-softmax [13]用于训练,
用户和项目嵌入的内积反映了偏好。我们在阿里巴巴深度学习平台中实施了YouTube产品-NDN,与我们提出的模型具有相同的输入功能。预测中采用内积空间的精确kNN搜索。
•TDM注意 - DNN(基于树的深度模型,使用关注网络)是我们在图2中提出的方法。该树以3.5节中描述的方式进行初始化,并在实验期间保持不变。
对于FM,BPR-MF和item-CF,我们根据验证集调整几个最重要的超参数,即FM和BPR-MF中的因子和迭代次数,以及项CF中的邻居数。 FM和BPR-MF要求测试或验证集中的用户在训练集中也有反馈。因此,我们将测试和验证集中的时间线上的前半部分用户迭代添加到两个数据集中的训练集中。对于YouTube产品-DNN和TDM注意-DNN,节点嵌入的维度设置为24,因为较高的维度在我们的实验中效果不佳。三个完全连接层的隐藏单元数分别为128,64和24。根据时间戳,用户行为被分为10个时间窗口。在YouTube产品-DNN和TDMattention-DNN中,对于每个隐式反馈,我们随机选择MovieLens-20M中的100个负样本和UserBehavior中的600个负样本。请注意,TDM的负样本数是所有级别的总和。我们在靠近叶子的位置采样更多的负值。
5.3比较结果
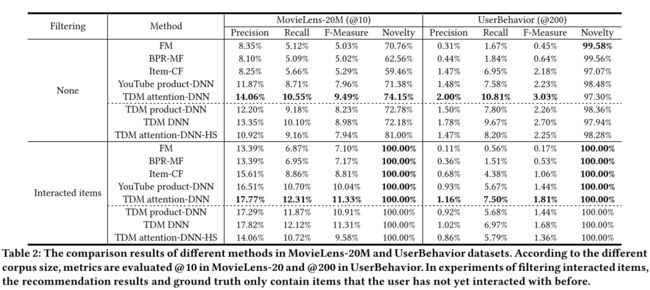
不同方法的比较结果如虚线上方表2所示。 Each metric是测试集中所有用户的平均值,所提供的值是具有方差的方法的五次不同运行的平均值。
首先,结果表明,在大多数度量标准中,所提出的TDM注意DNN在两个数据集中均显着优于所有基线。与次优YouTube产品DNN方法相比,TDM注意DNN分别在两个数据集中分别实现21.1%和42.6%的
回忆度量,而无需过滤。该结果证明了TDM关注-DNN采用的先进神经网络和分层树搜索的有效性。在内部产品形式中对用户偏好进行建模的方法中,YouTube产品-DNN由于使用了神经网络而优于BPR-MF和FM。广泛使用的项目-CF方法获得了
最新颖的结果,因为它对用户已经交互的内容有着强烈的记忆。
为了
提高新颖性,实践中常用的方法是对
推荐集中的交互项进行过滤[7,16],即仅推荐那些新颖的项目。因此,比较完整新颖结果集中的准确性更为重要。在本实验中,如果滤波后的结果集大小小于M,那么结果集大小将补充到所需的数量M.表2的下半部分显示,在过滤交互项后,TDM关注-DNN优于大型边缘中的所有基线。
为了进一步评估不同方法的
探索能力,我们通过从推荐结果中排除那些相互作用的类别来进行实验。每种方法的结果也作了补充以满足尺寸要求。事实上,
类别级别的新颖性是淘宝推荐系统中最重要的新颖度量标准,因为我们希望
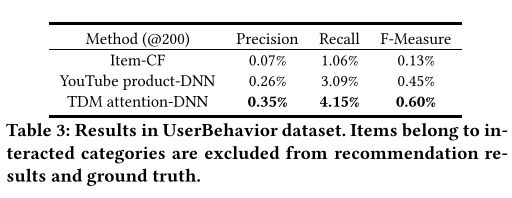
减少类似于用户交互项目的推荐量。由于MovieLens-20M总共只有20个类别,这些实验仅在UserBehavior数据集中进行,结果如表3所示。以Recme metric为例。我们可以观察到Item-CF的召回率仅为1.06%,因为它的推荐结果难以跳出用户的历史行为。 YouTube产品-DNN与item-CF相比获得了更好的结果,因为它可以从整个语料库中探索用户的潜在兴趣。提议的TDM关注度--DNN的回忆率比YouTube的内部产品制作者好34.3%。这种巨大的改进对于推荐系统来说非常有意义,并且证明
更先进的模型对于推荐问题是巨大的差异。
5.4实证分析
TDM的变体。为了理解所提出的TDM方法本身,我们推导并评估了几种TDM的变体:
•TDM-product-DNN。为了找出先进的神经网络能否使TDM的结果受益,我们测试了变体TDM产品-DNN。 TDM-produc-DNN使用与YouTube产品-DNN相同的内积。具体来说,图2中的关注模块被删除,节点嵌入项也从网络输入中删除。节点嵌入的内积和第三完全连接层的输出(没有PReLU和BN)以及S形激活构成了新的二元分类器。
•TDM-DNN。为了进一步验证注意模块在TDM-attention-DNN中带来的改进,我们测试了仅删除激活单元的变体TDMDNN,即图2中所有项目的权重均为1.0。
•TDM-attention-DNN-HS。如第3节所述,分层softmax(HS)方法[20]不适用于推荐。我们测试TDM注意-DNN-HS变体,即使用正节点的邻居作为负样本而不是随机选择的样本。相应地,在算法1的检索中,排序指标从单个节点的P(yu(n)= 1 | n,u)变为TTn'∈n的祖先P(yu(n')= 1 | n',u) 。注意-DNN被用作网络结构。
上述变体在两个数据集中的实验结果如虚线所示。表2中比较了TDM-attention-DNN和TDM DNN,UserBehavior数据集中近10%的查全率提高表明关注模块付出了很大的努力。 TDM产品-DNN执行比TDM DNN和TDM注意 - DNN更差,因为内部产品功能比神经网络交互功能少得多。这些结果证明,引入TDM中的高级模型可以显着提高推荐性能。注意,与TDM关注-DNN相比,TDM关注-DNN-HS获得了更多的结果,
因为分层softmax的公式不适合推荐问题。
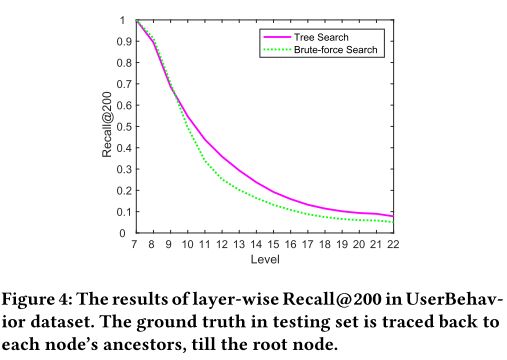
树的作用。树是所提出的TDM方法的关键组成部分。它不仅可以作为检索中使用的索引,而且还可以将语料库从粗到细的层次结构模型化。 3.3节提到直接制作细粒度推荐比分层方式更困难。我们进行实验来证明观点。图4说明了分层树搜索(算法1)和强力搜索(遍历相应级别中的所有节点)的分层Recall @ 200。这些实验是在具有TDM产品DNN模型的UserBehavior数据集中进行的,因为它是唯一可以使用强力搜索的变体。蛮力搜索稍高于高级别的树搜索(级别8,9),因为那里的节点号很小。一旦一个级别中的节点数量增加,树搜索比强力搜索得到更好的回想结果,因为树搜索可以将这些低级结果排除在高级别上,这降低了低级别问题的难度。该结果表明树结构中包含的层次结构信息可以帮助提高推荐的准确性。
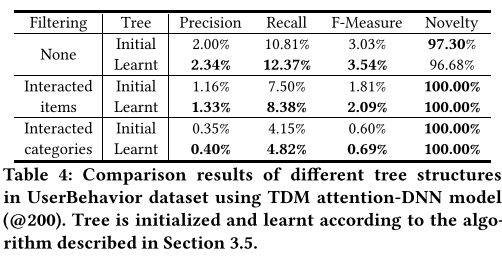
树学习。在3.5节中,我们提出树初始化和学习算法。表4给出了初始树和学习树之间的比较结果。从结果中,我们可以看到,具有学习树结构的训练模型显着优于初始模型。例如,在过滤互动类别的实验中,与初始树相比,学习树的召回度量从4.15%增加到4.82%,超过YouTube产品-DNN的3.09%和项目-CF的1.06%,这是非常大的。
为了进一步比较这两棵树,我们举例说明了TDM关注-DNN方法w.r.t的测试丢失和回忆曲线。训练迭代在图5中。从图5(a),我们可以看到学习的树结构获得了较小的测试损失。并且图5(a)和5(b)都表明模型收敛到学习树更好的结果。上述结果证明,树学习算法可以改善项目的层次结构,进一步促进训练和预测。

5.5在线结果
我们在具有真实流量的淘宝展示广告平台上评估所提出的TDM方法。实验在淘宝App主页的猜猜你喜欢的专栏中进行。两个在线指标用于衡量性能:点击率(CTR)和每千米收入(RPM)。详情如下:
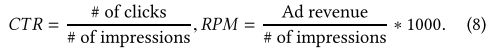
在我们的广告系统中,广告客户针对特定的广告群组进行出价。大约有140万个集群,每个广告集群包含数百或数千个类似的广告。实验以广告集群的粒度进行,以与现有系统保持一致。比较方法是逻辑回归混合[8],用于仅从那些相互作用的群集中挑选出优越的结果,这是一个强大的基线。由于在系统中有许多阶段,如图1所示的CTR预测[28]和排序[29],所以在线部署和评估所提出的TDM方法是一个巨大的项目,涉及整个系统的链接和优化。我们已经完成了迄今为止第一个TDM DNN版本的部署,并在线评估了其改进。每个比较桶都有在线流量的5%。值得一提的是,有几个在线同时运行推荐方法。他们以不同的观点进行努力,并将他们的推荐结果合并在一起进行以下阶段。 TDM只取代其中最有效的一个,同时保持其他模块不变。表5列出了TDM测试桶的平均公制升降率
如表5所示,TDM方法的CTR增加2.1%。这种改进表明,所提出的方法可以为用户回忆更准确的结果。另一方面,RPM指标增长6.4%,这意味着TDM方法也可以为淘宝广告平台带来更多收入.TDM已经部署到服务主要在线流量,我们相信上述改进仅仅是一个巨大项目的初步结果,并且还有进一步改进的余地。

预测效率。 TDM使先进的神经网络可以在大规模推荐中交互用户和项目,这为推荐系统打开了一个全新的视角。尽管先进的神经网络在推断时需要更多的计算,但是整个预测过程的复杂度不大于O(k * log | C | * t),其中k是所需的结果大小,| C |是语料库大小,t是网络单前馈通道的复杂度。在当前的CPU / GPU硬件条件下,这种复杂性上限是可以接受的,并且用户侧的特征在一次检索中在不同节点间共享,并且根据模型设计可以共享一些计算。在淘宝展示广告系统中,它实际上采用部署的TDM DNN模型约6毫秒平均推荐一次。这种运行时间比下面的点击率预测模块要短,而不是系统的瓶颈。
六,结论
我们计算出基于主要挑战的基于模型的方法来生成来自大规模语料库的推荐,即进行预测时的计算量问题。提出了一种基于树的方法,其中可以在大规模推荐中使用任意的高级模型来沿着树粗略地推断用户兴趣。除了对模型进行训练外,还采用了树结构学习方法,这证明了更好的树结构可以带来更好的结果。未来可能的方向是设计更精细的树学习方法。我们进行了广泛的实验来验证有效性的建议方法,无论是在建议的准确性和新颖性。此外,实证分析还展示了该方法的工作原理和方法。在淘宝展示广告平台上,所提出的TDM方法已经在生产环境中部署,既提高了商业效益,又提升了用户体验。
[1] Samy Bengio, JasonWeston, and David Grangier. 2010. Label embedding trees for largemulti-class tasks. In International Conference on Neural Information Processing Systems. 163–171.
[2] Alina Beygelzimer, John Langford, and Pradeep Ravikumar. 2007. Multiclass classification with filter trees. Gynecologic Oncology 105, 2 (2007), 312–320.
[3] PabloCastells, SaÞlVargas, and JunWang. 2011. Novelty andDiversityMetrics for Recommender Systems: Choice, Discovery and Relevance. In Proceedings of InternationalWorkshop on Diversity in Document Retrieval (2011), 29–37.
[4] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 7–10.
[5] Anna E Choromanska and John Langford. 2015. Logarithmic time online multi-class prediction. In Advances in Neural Information Processing Systems. 55–63.
[6] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. In ACM Conference on Recommender Systems. 191– 198.
[7] RobinDevooght andHugues Bersini. 2016. Collaborativefilteringwith recurrent neural networks. arXiv preprint arXiv:1608.07400 (2016).
[8] Kun Gai, Xiaoqiang Zhu, Han Li, Kai Liu, and ZheWang. 2017. Learning Piece-wise Linear Models from Large ScaleData forAd Click Prediction. arXiv preprint arXiv:1704.05194 (2017).
[9] Zeno Gantner, Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2011. MyMediaLite: A free recommender systemlibrary. In Proceedings of the fifth ACM conference on Recommender systems. ACM, 305–308.
[10] FMaxwellHarper and JosephA Konstan. 2016. The movielens datasets:History and context. ACM Transactions on Interactive Intelligent Systems 5, 4 (2016), 19.
[11] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. In Proceedings of the 26th International Conference onWorldWideWeb. 173–182.
[12] Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning. 448–456.
[13] Sébastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. 2014. On using very large target vocabulary for neural machine translation. arXiv preprint arXiv:1412.2007 (2014).
[14] Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity searchwith GPUs. arXiv preprint arXiv:1702.08734 (2017).
[15] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix Factorization Techniques for Recommender Systems. Computer 42, 8 (2009), 30–37.
[16] Dawen Liang, Jaan Altosaar, Laurent Charlin, and David M. Blei. 2016. Factorization Meets the Item Embedding:Regularizing Matrix Factorization with Item Co-occurrence. In ACM Conference on Recommender Systems. 59–66.
[17] D. Lin. 1999. WordNet: An Electronic Lexical Database. Computational Linguistics 25, 2 (1999), 292–296.
[18] Greg Linden, Brent Smith, and Jeremy York. 2003. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet computing 7, 1 (2003), 76–80.
[19] TomasMikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and JeffreyDean. 2013. Distributed representations of words and phrases and their compositionality. In International Conference on Neural Information Processing Systems. 3111–3119.
[20] Frederic Morin and Yoshua Bengio. 2005. Hierarchical probabilistic neural network language model. Aistats (2005).
[21] Andrew Y. Ng, Michael I. Jordan, and YairWeiss. 2001. On spectral clustering: analysis and an algorithm. In International Conference onNeural Information Processing Systems: Natural and Synthetic. 849–856.
[22] YanruQu,Han Cai, Kan Ren,Weinan Zhang, Yong Yu, YingWen, and JunWang. 2016. Product-based neural networks for user response prediction. In IEEE 16th International Conference on Data Mining. IEEE, 1149–1154.
[23] Steffen Rendle. 2010. Factorization Machines. In IEEE International Conference on DataMining. 995–1000.
[24] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the 25th conference on uncertainty in artificial intelligence. AUAI Press, 452–461.
[25] Ruslan Salakhutdinov andAndriyMnih. 2007. ProbabilisticMatrix Factorization. In InternationalConference onNeural Information ProcessingSystems. 1257–1264.
[26] Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In International Conference onWorldWideWeb. 285–295.
[27] Bing Xu, NaiyanWang, Tianqi Chen, and Mu Li. 2015. Empirical evaluation of rectified activations in convolutional network. arXiv:1505.00853 (2015).
[28] Guorui Zhou, Chengru Song, Xiaoqiang Zhu, Xiao Ma, Yanghui Yan, Xingya Dai, Han Zhu, Junqi Jin, Han Li, and Kun Gai. 2017. Deep interest network for click-through rate prediction. arXiv preprint arXiv:1706.06978 (2017).
[29] Han Zhu, Junqi Jin, Chang Tan, Fei Pan, Yifan Zeng, Han Li, and Kun Gai. 2017. Optimized Cost Per Click in Taobao Display Advertising. In Proceedings of the 23rd ACM SIGKDD Conference. ACM, 2191–2200.