大数据Hadoop集群中常用的任务调度框架
在大数据的集群环境中,经常用到的任务调度框架有如下几个,根据公司的业务的需要选择适合自己的业务调度的框架,
调度框架anzkaban,crontab(Linux自带)、zeus(Alibaba)、Oozie(cloudera),下面将分别介绍各个调度框架
使用任务调度工具功能:
时间调度:基于时间条件触发程序运行
依赖调度:基于其他程序的执行结果进行调度执行
数据可用性调度:
一、anzkaban的介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
优点:
功能相对较为全面-----操作性较好
缺点:
特点:
Compatible with any version of Hadoop----------适合任何Hadoop版本
Easy to use web UI------------------ 简单易用的web用户界面
Simple web and http workflow uploads------简单的web平台提交工作流
Project workspaces---------项目空间
Scheduling of workflows---------------工作流的调度
Modular and pluginable----------------- 模块化、支持插件
Authentication and Authorization-------------------权限和认证
Auth2Tracking of user actions--------------- 追踪用户行为
Email alerts on failure and successes----------------任务状态 邮件通知
SLA alerting and auto killing--------------------- 支持SLA等级服务协议,自动终止程序
Retrying of failed jobs------------------------重试运行失败的任务
azkaban三大组件
web server:提供用户访问接口,接收用户提交的工作流,实现工作流监控
executor: 执行用户提交的工作流 任务
mysql:用于存储所有工作流的信息、状态、日志在web server提交一些job,job id等信息存放在mysql中
executor执行任务的状态,执行到第几步,执行了多少时间等信息存放到mysql中。
azkaban伪分布式的安装:创建安装目录 mkdir -p /opt/modules/azkaban-3.3.0 解压3个安装包
数据库相关
为azkaban创建对应的用户,数据库,设置权限
https://azkaban.github.io/azkaban/docs/latest/#getting-started
CREATE DATABASE azkaban;
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
flush privileges;
select user,host from mysql.user;
sudo service mysqld restart
执行相关SQL创建对应的表
mysql -u root -p
use azkaban
source /opt/modules/azkaban-3.3.0/azkaban-sql-0.1.0-SNAPSHOT/create-all-sql-0.1.0-SNAPSHOT.sql
source /opt/modules/azkaban-3.3.0/azkaban-sql-0.1.0-SNAPSHOT/update.active_executing_flows.3.0.sql
source /opt/modules/azkaban-3.3.0/azkaban-sql-0.1.0-SNAPSHOT/update.execution_flows.3.0.sql
配置web server
-》进入web server目录
cd azkaban-web-server-0.1.0-SNAPSHOT/
-》生成认证密钥
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
-》修改配置
conf/azkaban.properties
default.timezone.id=Asia/Shanghai
mysql.host=bigdata-hpsk01.huadian.com
jetty.password=123456
注意:
默认开启了SSL,访问必须使用https来访问8443端口
如果,不想使用https,关闭SSL,
jetty.ssl.use=false;
关闭之后,访问端口是8081
jetty.ssl.port=8443
jetty.port=8081
jetty.keypassword=123456
jetty.truststore=keystore
jetty.trustpassword=123456
-》添加log4j配置
vi conf/log4j.properties
log4j.rootLogger=INFO,C
log4j.appender.C=org.apache.log4j.ConsoleAppender
log4j.appender.C.Target=System.err
log4j.appender.C.layout=org.apache.log4j.PatternLayout
log4j.appender.C.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
-》添加日志转换包
cp /opt/softwares/slf4j-log4j12-1.6.6.jar lib/
配置execute
cd azkaban-exec-server-0.1.0-SNAPSHOT/
修改配置文件:
default.timezone.id=Asia/Shanghai
mysql.host=bigdata-hpsk01.huadian.com
mysql.database=azkaban
关闭内存检查
内存<3GB 不执行任务
mkdir -p plugins/jobtypes
vim plugins/jobtypes/commonprivate.properties
memCheck.enabled=false
启动登录
-》启动web Server
bin/azkaban-web-start.sh
-》启动execute
bin/azkaban-executor-start.sh
-》登录
https://bigdata-hpsk01.huadian.com:8443
azkaban工作流的创建
创建工作流
-》创建一个project
-》创建工作流
一个job等于一个job文件,后缀名为.job
type:指定job的类型
command=类型为command
-》将job统一变成一个压缩文件
-》上传到对应的project中
依赖调度:
job1:上传一个文件到HDFS上
job2:对文件进行wordcount处理
job3:将上传好的文件移动到备份目录
job4:将处理好的结果下载到Linux本地
要求:job2,job3依赖job1
job4 依赖job3、job2
二、crontab(Linux自带)的介绍
crontab命令常见于Unix和Linux的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于"crontab"文件中,以供之后读取和执行。
在Linux系统中,Linux任务调度的工作主要分为以下两类:
1、系统执行的工作:系统周期性所要执行的工作,如备份系统数据、清理缓存
2、个人执行的工作:某个用户定期要做的工作,例如每隔10分钟检查邮件服务器是否有新信,这些工作可由每个用户自行设置
Linux crontab:基于分钟基准的时间调度
使用:crontab -e
* * * * * command(shell)
分 时 日 月 周
每2分钟: */2 * * * * rm
优点: 简单
缺点:不能实现依赖调度和任务并发
crontab -u //设定某个用户的cron服务,一般root用户在执行这个命令的时候需要此参数 crontab -l //列出某个用户cron服务的详细内容 crontab -r //删除没个用户的cron服务 crontab -e //编辑某个用户的cron服务
/sbin/service crond start //启动服务 /sbin/service crond stop //关闭服务 /sbin/service crond restart //重启服务 /sbin/service crond reload //重新载入配置
三、zeus(Alibaba)
zeus:阿里巴巴开源的,不在维护https://www.oschina.net/p/alibaba-zeus
优点:
支持大多数的任务类型调度
支持hive元数据管理
文档是中文
提供web端的可视化操作界面
实现了资源调度
缺点:
阿里巴巴开源了zeus1,支持Hadoop1
zeus2是个人开发者在维护
bug多
一般现在使用的版本:携程
Zeus是Alibaba开源的一个完整的Hadoop的作业平台,用于从Hadoop任务的调试运行到生产任务的周期调度。
宙斯支持任务的整个生命周期。从功能上来说,支持:
* Hadoop MapReduce任务的调试运行
* Hive任务的调试运行
* Shell任务的运行
* Hive元数据的可视化查询与数据预览
* Hadoop任务的自动调度
* 完整的文档管理
Zeus是针对Hadoop集群任务定制的,通用性不强,是基于Python的工作流引擎
基于Python的工作流引擎优点是:The DAG definition is code。因此可维护性,版本管理,可测性和协作性更好
四、Oozie(cloudera)
Oozie:cloudera公司产品
优点:
功能强大,支持的调度任务的类型比较多
缺点:
安装部署、任务流开发比较复制
现实业务中处理数据时不可能只包含一个MR操作,一般都是多个MR,并且中间还可能包含多个Java或HDFS,甚至是shell的操作,利用Oozie可以完成这些任务。
实际上Oozie不是仅用来配置多个MR工作流的,它可以是各种程序夹杂在一起的工作流,比如执行一个MR1后,接着执行一个java脚本,再执行一个shell脚本,接着是Hive脚本,然后又是Pig脚本,最后又执行了一个MR2,使用Oozie可以轻松完成这种多样的工作流。使用Oozie时,若前一个任务执行失败,后一个任务将不会被调度。

工作流调度框架Oozie
- 工作流
import ->
hive -> export
- 调度
作业 / 任务 定时执行
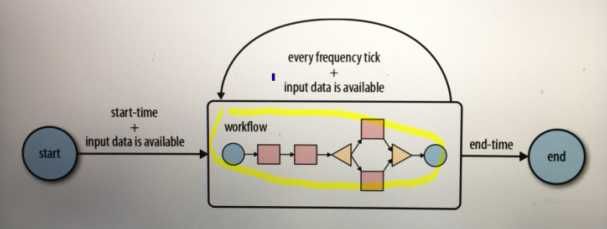
事件触发执行
时间(比如说。每天晚上10点到凌晨2点之间,没半个小时运行一次。比如说,每周五的晚上8点触发一次)
数据集(比如说。某个目录文件下有数据,就触发一次)
Oozie概述
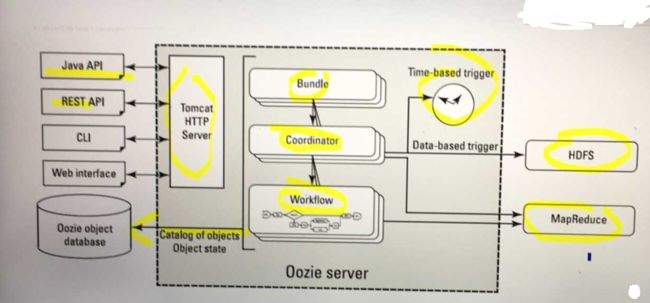
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
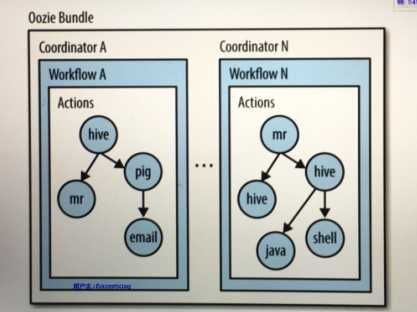
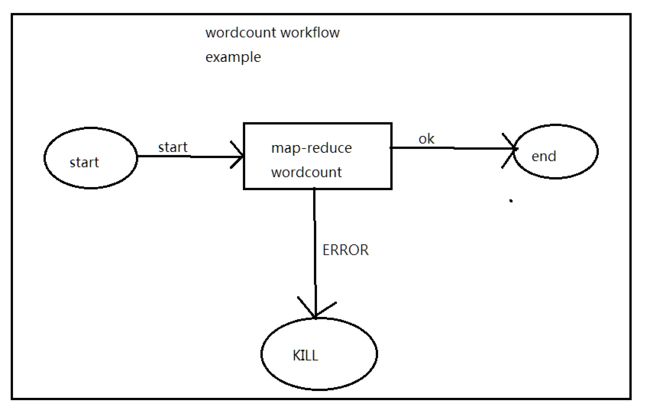
Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.

Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availabilty.
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).
Oozie is a scalable, reliable and extensible system.
1,一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop Mapreduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。
2,Oozie工作流定义,同Jboss jBPM提供的jPDL一样,提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般会有很多不同功能的节点,比如分支,并发,汇合等等。
3,Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision,fork,join等;而动作节点包括Haoop map-reduce hadoop文件系统,Pig,SSH,HTTP,eMail和Oozie子流程
Oozie Server Architecture

Oozie Server Components