本文介绍了word2vec作者的一篇计算sentence vector的论文,在文本分类、文本向量表示中有着很好的应用。
需先深入了解word2vec的原理,语言结构:skip-gram,CBOW;优化方法:加速softmax (negative sampling和hierarchical softmax)
paper:
Distributed Representations of Sentences and Documents https://arxiv.org/abs/1405.4053
by mikolov (word2vec作者)
Bag-of-words
传统sentence embedding做法:Bag-of-words,即将sentence中每个vector的one-hot vector进行求和
缺点:
1. 忽略了句子的词序
比如 下面两句话
this movie is good,but I do not like it
this movie is not good, but I do like it
是完全一样的vector,在情感上却不同(注意,对一个句子中的词的词向量直接求sum或average,那么前面两句同样是一样的vector,区分不出来词序)
因此加入了 bag-of-ngrams.考虑了词序,比如 2-gram, is_good, not_good 为一个单词, not_like,do_like 也为一个单词,因此能区分上面两句。但是为了建模更大的上下文关系,选取很大的n会让训练参数过多,同时模型泛化能力会变差。
2. 维度太高+vector稀疏
sentence的维度 = unique word的个数,因此向量维度非常高。
3. 缺失语义性
每个单词都为 one-hot ,全部正交
更好的做法:
1.对句子中的word 的vector进行加权求和,来表示句子,但是同样丢失了order的信息(可以把n-gram同样求embedding之后对n-gram也进行加权?一定程度上解决order的问题)
2.构造一颗语法树,对里面word的vector进行concat
Paper中的做法:
method 1. Paragraph Vector: A distributed memory model (PV-DM)
借鉴word2vec,把文章单独赋予一个vector,每一次用文章的vector + 前k个单词的vector 拼接(文章与单词vector可以不同) or 平均(文章与单词vector必须相同?)后去预测下一个词。
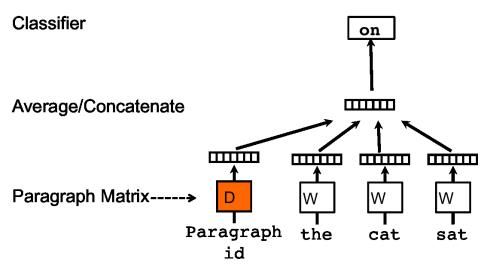
预测结构如图,和word2vec里的CBOW类似。
如此迭代训练,可以得到文章的vector,这样对于已有的文章embedding,可以很容易的使用类似LR,Kmeans的方法做分类或聚类。
预测阶段/得到一个新文章的vector:
显然,训练阶段得到的embedding只有已经训练过的文章的vector。
那么对于一篇新的文章怎么得到他的embedding?
此时固定住已经训练好的word的vector,同样用上图的结果,加入该新文章的vector(随机初始化)进行训练(基于SGD),可以得到新的文章的vector
method 2. Paragraph vector without word ordering: Distributed bag of words (PV-DBOW)

直接拿doc的embedding去预测词
相当于对每一个doc做(doc, doc(word)) 的skip-gram,这样自然也可以训练学习到doc的embedding
结果:
通常方法1的vector已经能很好的实现任务,但在experiment中,paper中使用 method1 和method2结合的方法,即把两个vector进行concat
Experiment:

在多个任务上能取得 state-of-the art
工具
强烈推荐facebook research的文本表示与分类工具fasttext。基于C++的多线程实现,速度很快且方便,几句简单的命令行就可以实现词向量与文本分类,一千万行语料做一万分类大概在3分钟左右。代码在github上下载,make后即可使用
无监督学习:
./fasttext skip-gram 或 ./fasttext cbow
可以学习得到词向量(与google的word2vec工具一样,但是可以选择多轮迭代,同时fasttext使用了例如subword等改进来提升词向量的效果)
有监督学习:
./fasttext supervised
注意在类别数非常多(比如10000类)时,需要指定loss=ns / hs,即与word2vec一样使用negative sampling和hierarchical softmax对做多分类时的softmax进行加速。
训练完成后使用./fasttext print-sentence-vector命令即可以得到句子的向量(但是不确定是否是论文中的方法)
工作应用
- 获取商品标题的vector计算基于标题的相似度(cos距离)
- 使用标题对商品类目/产品词进行分类,效果也不错,能达到95%左右F1值的baseline