回顾图像分割的经典算法
[转] https://www.leiphone.com/news/201801/vV9tk5kK95g0spUG.html
图像语义分割是 AI 领域中一个重要的分支,是机器视觉技术中关于图像理解的重要一环。近年的自动驾驶技术中,也需要用到这种技术。车载摄像头探查到图像,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。随着近些年深度学习的火热,使得图像分割有了巨大的发展,本文为大家介绍深度学习中图像分割的经典算法。
在近期雷锋网(公众号:雷锋网) GAIR 大讲堂上,来自浙江大学的在读博士生刘汉唐为等候在直播间的同学们做了一场主题为「图像分割的经典算法」的技术分享,本文根据直播分享内容整理而成,同学们如果对嘉宾所讲的内容感兴趣还可以在 AI 慕课学院观看直播回放。(技术细节推荐观看视频回放)
刘汉唐,浙江大学计算机系博士生在读,阿里巴巴 iDST 实习生。研究方向是计算机视觉、深度学习。个人公众号是:贾维斯的日常(jarvisdaily)。
分享提纲:
图像分割的问题定义,以及在实际场景中的应用样例
全卷积网络
双线性上采样
特征金字塔
Mask-RCNN
大家好,我是浙江大学在读博士生刘汉唐,目前在阿里巴巴 iDST 实习。接下来的分享首先会为大家介绍图像分割具体是做什么的,图像分割有哪些应用场景以及做图像分割实验经常用到的几个数据集。
最后再讲解图像分割的几个方法。分为两个部分,第一部分是传统视觉的图分割算法,虽然现在很少用,但自认为算法比较优美。第二部分是深度学习算法,会介绍最近几年流行的经典技巧。
什么是图像分割?
图像分割就是预测图像中每一个像素所属的类别或者物体。图像分割有两个子问题,一个是只预测类别层面的分割,对每个像素标出一个位置。第二个是区分不同物体的个体。

应用场景,比如自动驾驶,3D 地图重建,美化图片,人脸建模等等。
最常用的数据集
主要介绍三个:Pascal VOC;CityScapes;MSCOCO。
第一个是 Pascal VOC 数据集

这是一个比较老牌的数据集,它提供 20 个类别,包括,人,车等。有 6929 张标注图片,提供了类别层面的标注和个体层面的标注,也就是说既可以做语义分割,只区分是不是车;也可以做个体分割,区分有几辆车,把不同的车标记出来。
第二个是CityScapes数据集

主要面向道路驾驶场景,它有 30 个精细的类别。其中有 5000 张图片进行了精细标注,精确到像素级别。还有 20000 张图片有粗糙的标注。它也可以提供语义层面分割和个体层面分割。
第三个是MS COCO数据集

这是目前为止有语义分割的最大数据集,提供的类别有 80 类,有超过 33 万张图片,其中 20 万张有标注,整个数据集中个体的数目超过 150 万个,最新的一些论文都会在 MSCOCO 数据集上做实验,因为它的难度最大,挑战新最高。
传统的图切割
图切割就是移除一些边,使得两个子图不相连;图切割的目标是,找到一个切割,使得移除边的和权重最小。
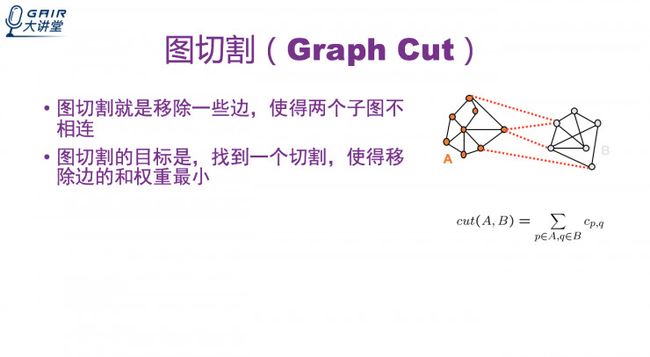
图切割的优点和缺点
优点是分割效果还不错,并且是一种普适性的框架 ,适合各种特征。缺点是时间复杂度和空间复杂度较高,需要事先选取分割块儿的数目。
图切割的失败案列
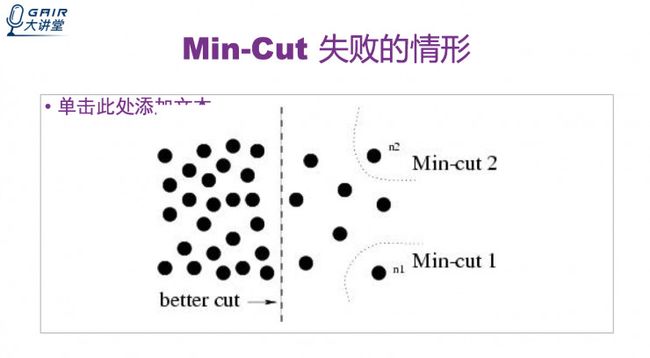
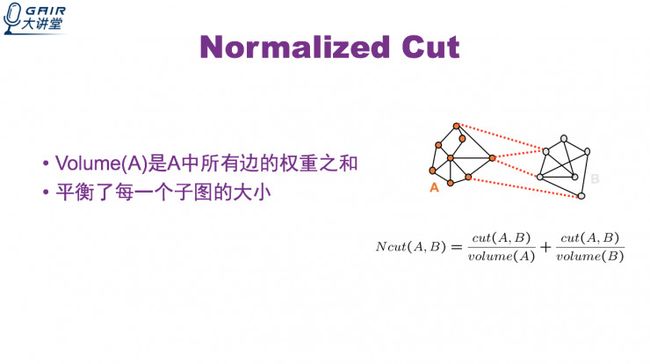
为了克服这个失败,有一篇论文提出了 Normalized Cut。它是在图分割中加入权重参数 Volume。Volume(A) 是 A 中所有边的权重之和。这种方法平衡了每一个子图的大小。
深度学习算法
第一篇比较成功用神经网络做图像分割的论文是 Fully Convolutional Networks (以下简称为 FCN)。
传统神经网络做分类的步骤是,首先是一个图像进来之后经过多层卷积得到降维之后的特征图,这个特征图经过全连接层变成一个分类器,最后输出一个类别的向量,这就是分类的结果。
而 FCN 是把所有的全连接层换成卷基层,原来只能输出一个类别分类的网络可以在特征图的每一个像素输出一个分类结果。这样就把分类的向量,变成了一个分类的特征图。
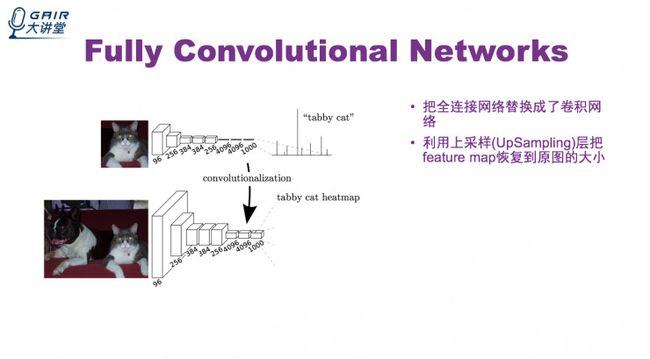
为了能让分类的特征图恢复到原图的大小,采用了上采样层。具体细节可观看视频回放。
FCN的结构图
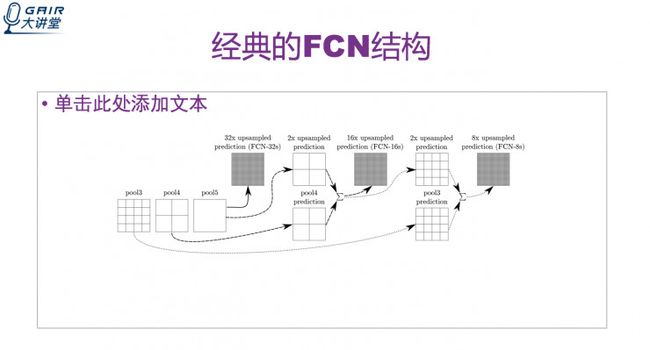
下面介绍一下怎么进行图片放大操作的。
这里有两个概念,第一个概念叫反卷积层(Deconvolution);第二个概念叫双线性差值上采样(Bilinear Upsampling)。
这里的「反卷积」其实不是真正的卷积的逆运算,用 Transposed Convolution 代替比较合适,但原论文中用的是 Deconvolution,我们下面还是用这个词,它可以等效于普通卷积。它的主要目的就是实现上采样。

反卷积具体是怎么计算的,详细过程可到AI慕课学院免费观看视频回放。
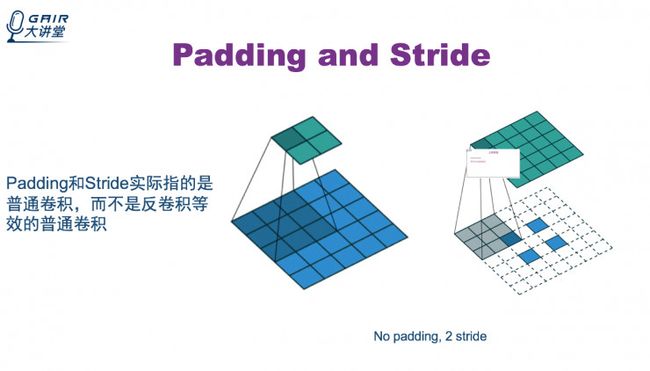
下面讲一下Padding和Stride。
Padding和Stride实际指的是普通卷积,而不是反卷积等效的普通卷积。
双线性上采样差

双线性上采样差值的三个用途:用作初始化反卷积的权重;不用反卷积,使用上卷积+卷积;只使用上采样。
下面介绍膨胀卷积或带洞卷积(Dilated Convolution )。
它的用途可以使特征图视野变大,但不增加计算量,对于图像分割的好处,更利于提取全局信息,这样就使得分割准确率增加很多。

特征金字塔(Feature Pyramid)
有以下几种特征金字塔

特征金字塔网络
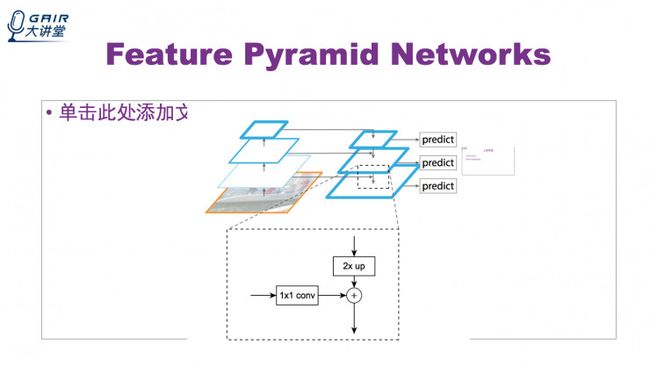
Pyramid Pooling
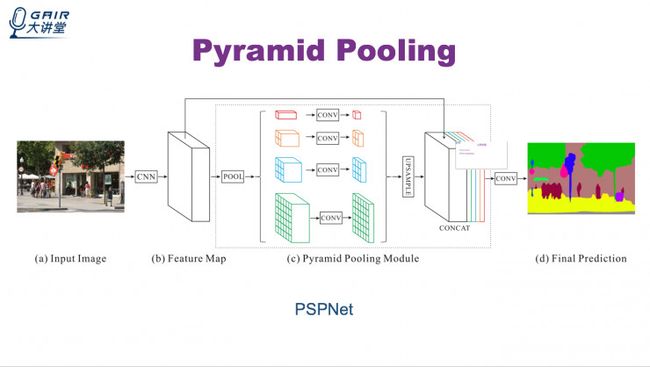
前面的是在不同的尺度上提取特征,而这个是把特征提取之后pooling到不同的大小。
Mask-RCNN的特点

第一个特点它是多分支输出的。它同时输出物体的类别,bounding box和Mask。
第二个特点是它使用了Binary Mask。之前神经网络都是使用多类Mask,而它只需要判断物体在哪个地方。
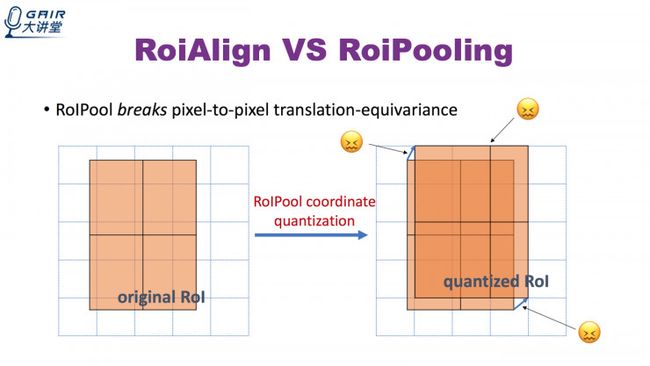
最后是RoiAlign层。能比较精确地把物体的位置对应到特征图的位置上。
具体讲解细节请观看免费的直播回放视频。
Rol Pooling 与Roi Align的比较

雷锋网AI 慕课学院提供本次直播回放视频,点击链接直达:http://www.mooc.ai/course/414/learn#lesson/2266。