网易云爬虫-爬取单曲和歌单所有歌曲
网易云爬虫-爬取单曲和歌单所有歌曲
今天断网了 敲代码不听歌的程序员是没有灵魂的,但是本地下载又太繁琐了,想着能不能一下把一个歌单的内容按文件夹进行下载,说做就做.
首先网上已经有了网易云js加载encSecKey和params参数的加密过程,分析也是稍微有些繁琐。这里我根据网易云的一个外链进行简单的下载
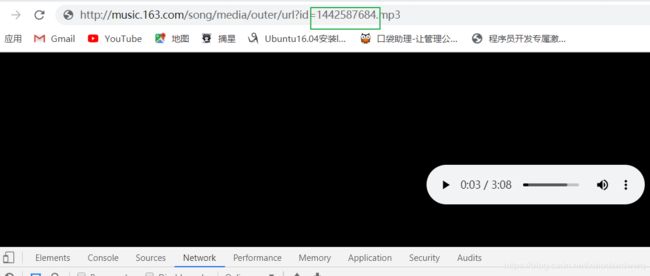
http://music.163.com/song/media/outer/url?id={}.mp3每个根据都有不同的id 我们只需要将不同歌曲的id给填充下载,就可以请求数据,保存到本地 就是下载了。
下载网易云歌单同理:
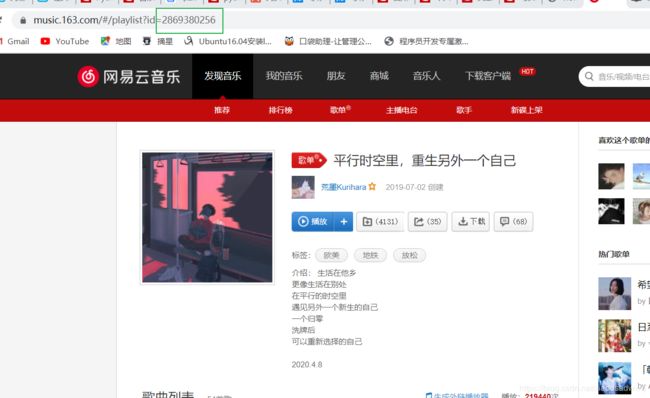
每个歌单的id都是固定,前面的url都是一样的,我们用户只需要点开歌单 填充歌单id就能够得到这个歌单的页面数据,然后再对这个页面数据进行分析,拿到每一个歌曲的id 再根据第一步下载单曲的步骤就能将歌曲下载下来了。是不是很简单, 下载我将我写的源代码贴下,不足之处,请大家指教!
#!/usr/bin/python
# -*- coding: utf-8 -*-
# @Time : 2020/4/24 15:05
# @Author : zh
# @File : wangyiyun.py
import json
import os
import re
from pprint import pprint
import requests
from selenium import webdriver
class WangYiYun():
def __init__(self):
self.song_mp3_url = 'http://music.163.com/song/media/outer/url?id={}.mp3'
self.song_list_id = 'https://music.163.com/#/playlist?id={}'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"
}
self.song_url = "https://music.163.com/#/search/m/?s={}&type=1"
self.songs = []
def show_menu(self):
print("欢迎来到网易云音乐下载中心")
print("-"*50)
print("1. 下载单曲")
print("2. 下载歌单")
print("3. 退出")
print("-"*50)
def run(self):
self.show_menu()
while True:
option = int(input("请输入您要进行的操作:"))
if option not in [1,2,3]:
print("请重新输入")
if option == 1:
song_name = input("请输入歌曲名称:")
song_id = self.get_song_id(song_name)
if option == 2:
# 下载歌单
menu_id = int(input("请输入您要下载的歌单id:"))
list_id = self.get_song_list_id(menu_id)
else:
break
def get_song_list_id(self, nmenu_id):
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(r'chromedriver.exe',
chrome_options=option)
driver.get(self.song_list_id.format(nmenu_id))
driver.switch_to.frame('g_iframe')
list_name = driver.find_element_by_xpath('//div[@class="tit"]/h2').text
list_name = "".join(list_name.split())
list_name = re.sub(r'\W', '', list_name)
if not os.path.exists(list_name):
os.mkdir(list_name)
a_list = driver.find_elements_by_xpath('//span[@class="txt"]/a')
title_list = driver.find_elements_by_xpath('//span[@class="txt"]/a/b')
for a in a_list:
item = {}
item["song_id"] = a.get_attribute('href').split("=")[-1]
item["song_name"] = title_list[a_list.index(a)].get_attribute('title').replace(u'\xa0', u'')
item["song_name"] = item["song_name"].replace(u'\xf1',u'')
self.songs.append(item)
for item in self.songs:
self.download_song(item, list_name)
def get_song_id(self, song_name):
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(r'C:\Users\zh\Desktop\jxsz_code\pachong_code\chromedriver.exe',
chrome_options=option)
driver.get(self.song_url.format(song_name))
driver.switch_to.frame('g_iframe')
song_url = driver.find_element_by_xpath("//div[@class='text']/a").get_attribute('href')
item = {}
item["song_id"] = song_url.split('=')[-1]
item["song_name"] = driver.find_element_by_xpath("//div[@class='text']/a/b").get_attribute('title')
self.download_song(item)
driver.close() # 退出当前页面
driver.quit() # 退出浏览器
def download_song(self, item, dir_name=None):
req = requests.get(self.song_mp3_url.format(item["song_id"]), headers = self.headers)
if dir_name is None:
with open('%s.mp3'%item["song_name"], 'wb') as f:
f.write(req.content)
else:
try:
with open('%s/%s.mp3'%(dir_name, item["song_name"]), 'wb') as f:
# with open('%s.mp3' % item["song_name"], 'wb') as f:
f.write(req.content)
print(item["song_id"])
print("%s 下载完成"%item["song_name"])
except:
pass
def test(self):
req = requests.get(self.song_mp3_url.format(1439803847), headers = self.headers)
# print(req.headers)
with open("a.mp3", "wb") as f:
f.write(req.content)
wangyiyun = WangYiYun()
wangyiyun.run()
为了方便大家使用,我还使用pyinstaller将此程序打包成可执行文件,大家双击就行运行。
链接:https://pan.baidu.com/s/1YeFFkcUg1vCZQCBoXKo7eg
提取码:mp23
复制这段内容后打开百度网盘手机App,操作更方便哦
操作视频演示:
链接:https://pan.baidu.com/s/1d-mn5kSSqPhkTrNdA_YbCg
提取码:egj2
复制这段内容后打开百度网盘手机App,操作更方便哦