策略产品经理--NLP技术基础与算法模型
前言:BERT模型的出现,使NLP技术进入新的时代。由此机会窥探NLP技术全貌,学习了解NLP相关技术与算法模型。
一、基本概念
词向量(Word Embedding):
词向量主要用于将自然语言中的词符号数学化,这样才能作为机器学习问题的输入。
数学化表示词的方式很多,最简单的有独热编码,即“足球”=[0,0,1,0,0,0,0,…],“篮球”=[0,0,0,0,0,1,0,…],向量的长度为总词数。显然,独热编码有以下缺点:1.可能导致维数过大,对深度学习来说复杂度过高。2.两个词的相似程度无法表示。
词向量与独热编码不同,一般是以下形式:[0.2333,0.4324,0.6666,-0.9527,….],维数以50维和100维比较常见。词向量解决了维度过大的问题,且两个词的相似度可以用欧几里得距离,余弦相似度等方法求得。
语言模型:
语言模型形式化的描述就是,给定一个字符串,看它是自然语言的概率P(w1,w2,…,wt),其中wi表示这句话中的各个词。有个很简单的推论,(语言模型就是用来计算一个句子的概率的模型):
P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)(条件概率公式)
而事实上,常用的语言模型都是在近似地求P(wt|w1,w2,…,wt-1),语言模型后续介绍,谷歌的BERT模型也属于语言模型(预训练类)。
分类衡量指标:
以信息检索为例,总共50篇文献,其中20篇是我感兴趣的目标文献。输入特定检索条件返回10篇文献,其中5篇是我要的文献。则
精确率(Precision) = 查出的文章中有多少是正确目标 = 5/10
召回率(Recall) = 总共正确的文章中有多少被正确查出 = 5/20
两种值都是我们想要提高的,但不能两全其美:想要精确率为1,最好的结果就是一篇文献也没搜到,返回的结果肯定没有分类错误,但这样也没有意义;想要召回率为1,最好的情况就是50篇 返回,这样搜索本身也失去了意义。
定义F1分数为精确率与召回率的调和平均数:
![]()
这样可以避免出现精确率和召回率一个为1一个为0的极端情况出现
还可以根据对精确率/召回率的不同偏好设置F_beta分数

另一个角度来看这个问题。假设我们现在要判断一个用户是好人还是坏人,定义:TP(True Positive)为预测正确的好人的个数,FP(False Positive)为预测错误的好人的个数,FN(False Negative)为预测错误的坏人的个数,TN(True Negative)为预测正确的坏人的个数。可以写出混淆矩阵(Confusion matrix)如下:
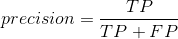 (返回的预测正确的与预测错误的目标的总数)
(返回的预测正确的与预测错误的目标的总数)
![]() (召回率的分母是总的正确的符合目标的数目,TP是返回的正确的符合目标的,FN是未返回的符合目标 的数目,即未返回的预测正确的好人的数目,也即预测错误的坏人的个数的另一种解释),注意与准确率和错误率(包含了预测正确的负向的那部分)相区别开。
(召回率的分母是总的正确的符合目标的数目,TP是返回的正确的符合目标的,FN是未返回的符合目标 的数目,即未返回的预测正确的好人的数目,也即预测错误的坏人的个数的另一种解释),注意与准确率和错误率(包含了预测正确的负向的那部分)相区别开。
(参考原文:https://blog.csdn.net/qq547276542/article/details/78274459?utm_source=copy )
二、NLP的两个关键问题
选择什么样的语言模型? 不同语言模型的区别,也就是对文本提取特征的不同。
选择什么样的分类算法? 后续介绍
2.1 常用的语言模型及算法介绍
语言模型的演化图
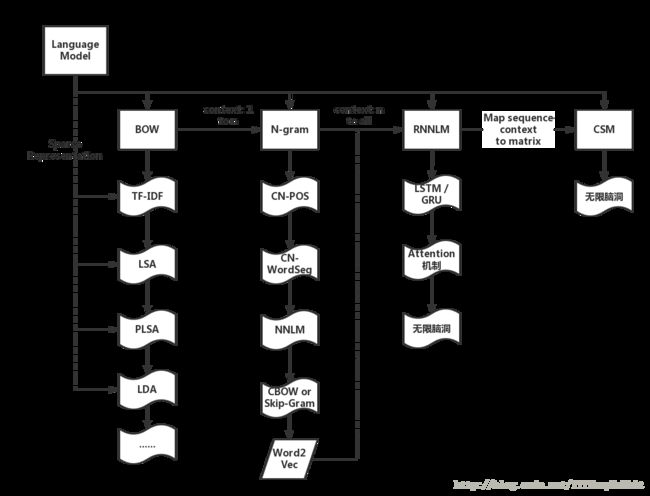
这里只讲几个简单的模型原理,LSA等都是对基于BOW,利用TF,IDF等
A、Bag-of-words模型(BOW,词袋模型)类
1,BOW模型
最初应用于文本处理领域,用来对文档进行分类和识别。BoW 模型因为其简单有效的优点而得到了广泛的 用。其基本原理可以用以下例子来给予描述。给定两句简单的文档:
文档 1:“我喜欢跳舞,小明也喜欢。”
文档 2:“我也喜欢唱歌。”
基于以上这两个文档,便可以构造一个由文档中的关键词组成的词典:
词典={1:“我”,2:“喜欢”,3:“跳舞”,4:“小明”,5:“也”,6:“唱歌”}
这个词典一共包含6个不同的词语,利用词典的索引号,上面两个文档每一个都可以用一个6维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数。这样,根据各个文档中关键词出现的次数,便可以将上述两个文档分别表示成词向量的形式:
文档 1:[1, 2, 1, 1, 1, 0]
文档 2:[1, 1, 0, 0, 1, 1]
从上述的表示中,可以很清楚地看出来,在文档表示过程中并没有考虑关键词的顺序,而是仅仅将文档看成是一些关键词出现的概率的集合(这是Bag-of-words模型的缺点之一),每个关键词之间是相互独立的,这样每个文档可以表示成关键词出现频率的统计集合。
2、基于Term frequency(TF) , Inverse document frequency(IDF), 以及TF-IDF的统计特征的模型
这种语言模型主要是用词汇的统计特征来作为特征集,每个特征都能够说得出物理意义,看起来会比bag-of-words效果好,但实际效果也差不多。其实也属于基于BOW模型的一种。
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
![]() (N1为在某一类中词条w出现的次数,N为该类中所有的词条数目)
(N1为在某一类中词条w出现的次数,N为该类中所有的词条数目)
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
![]() (N3为语料库的文档总数,NW为相应的包含词条w的文档总数,+1是是为了防止分母为0,即一种最原始的平滑算法,拉普拉斯平滑)
(N3为语料库的文档总数,NW为相应的包含词条w的文档总数,+1是是为了防止分母为0,即一种最原始的平滑算法,拉普拉斯平滑)
![]()
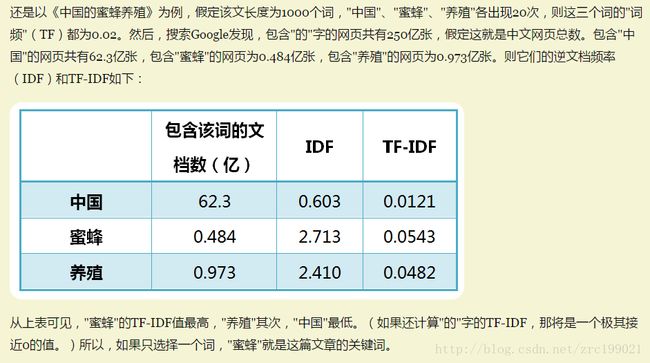
(参考:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html)
3. LSA潜在语义分析–文本稀疏表示–>文本相似度度量、主题模型
了解了TF-IDF模型,我们得到了文本的基本向量化表示,即得到了文本的(特征)向量,向量具有一定语义表达的能力。LSA正是在此基础上挖掘文本的潜在语义,建构主题模型等。
遍历语料库,得到全部文本-单词的权重矩阵,权重即上文所求TF-IDF值。建立文本-单词权重矩阵X后,可以通过SVD奇异值矩阵分解的方式将矩阵X转换为它的低秩逼近矩阵。可以去前k维作为主要特征,实现数据降维(原矩阵X维度为N*M,M为语料词汇总数)
其他BOW模型算法如PLSA,可以参考https://blog.csdn.net/tiffanyrabbit/article/details/72650606
B、N-gram模型类
一种考虑了词汇顺序的模型,每个样本转移成了转移概率矩阵。用来根据前(n-1)个item来预测第n个item。在应用层面,这些item可以是音素(语音识别应用)、字符(输入法应用)、词(分词应用)或碱基对(基因信息)。一般来讲,可以从大规模文本或音频语料库生成n-gram模型。 习惯上,1-gram叫unigram,2-gram称为bigram,3-gram是trigram。还有four-gram、five-gram等,不过大于n>5的应用很少见。
理论依据例子:给定一串字母,如”for ex”,下一个最大可能性出现的字母是什么。从训练语料数据中,我们可以通过极大似然估计的方法,得到N个概率分布:是a的概率是0.4,是b的概率是0.0001,是c的概率是。。。。
n-gram模型概率公式推导,根据条件概率和乘法公式:
![]()
得到
![]()
拿一个应用来讲,假设T是由词序列A1,A2,A3,…An组成的,那么P(T)=P(A1A2A3…An)=P(A1)P(A2|A1)P(A3|A1A2)…P(An|A1A2…An-1) 如果直接这么计算,是有很大困难的,需要引用马尔科夫链的假设,即当前这个词仅仅跟前面几个有限的词相关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上诉算式的长度,即:一个item的出现概率,只与其前m个items有关,当m=0时,就是unigram,m=1时,是bigram模型(n元表示相邻的n个词之间是有关系的)。
因此,P(T)可以求得,例如,当利用bigram模型时,P(T)=P(A1)P(A2|A1)P(A3|A2)…P(An|An-1) 而P(An|An-1)条件概率可以通过极大似然估计求得,等于Count(An-1,An)/Count(An-1)。
n-gram的应用:文化研究(不了解)、分词算法、语音识别、输入法、垃圾邮件识别。输入法中例如搜狗输入法如下,根据拼音判断合理的句子,其实底层原理是根据概率算出最优的一些算法。其实这个思想可以用在一些推荐策略上,根据概率算出。

N-gram计算原理:根据已有的(历史)语料库的词句统计的概率或者次数来预测新的语句的概率,然后输出概率最高的语句结果。
其应用例如搜索引擎的提示答案(输入一个关键词,自动输出几个结果提示)。
NNLM等都是对N-gram模型进行训练后延伸出的一些神经网络模型。
C、word embeding、Word2vec、 GloVe 、CBOW、skip-gram,one-hot,N-gram关系
word embedding 是一个将词向量化的概念,词嵌入。
Word2vec、 GloVe是 执行word embedding的具体算法,是一种训练算法。
CBOW、skip-gram是Word2vec训练算法中用到的语言模型(通过神经网络训练得到最后的词向量矩阵)
one-hot是最初的得到词向量的方法,n-gram是语言模型,这种语言模型和word2vec算法中模型是并列的关系,只不过n-gram自己可以利用概率计算得到相关的应用结果,我认为也可以说n-gram是一种算法。
上述这些都是围绕着“词向量”的概念的NLP算法模型技术,都属于浅层的方法,“效率换表达力”。
D、语言模型的迁移学习(预训练语言模型)
预训练的语言表征经过精调后可以在众多NLP任务中达到更好的表现,所以新出的这些预训练算法与模型是最新的技术发展概念,以及最新的BERT预训练模型。通过迁移学习与特定的任务相结合的方式有2种
feature-based:训练出的representation作为feature用于任务,也就是利用预训练的语言模型获得特征向量,将其用于具体任务。新的ELMo也属于这类,但迁移后需要重新计算出输入的表征。
fine-tuning:在预训练的语言模型基础上稍作改变,根据具体任务引入新的结构和参数,再次进行训练。通过与预训练语言模型的结合,许多原有的模型在任务上的效果进步提升。以阅读理解为例,人类在做道阅读理解题目时,并不仅仅从这篇文章,以及类似的阅读理解任务(训练集)中学习,而是会使用在此之前积累的各项知识。大规模语料预训练的语言模型正是这种知识的积累。这个主要借鉴于CV,就是在预训练好的模型上加些针对任务的层,再对后几层进行精调。新的ULMFit和OpenAI GPT属于这一类。
关于谷歌最新推出的BERT,全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。关于BERT的模型介绍可参考:https://zhuanlan.zhihu.com/p/46652512