XGBoost算法应用入门学习实践
随机森林与XGBoost都是以决策树作为基模型的集成模型。
| 算法的有点 | 算法的缺点 |
|---|---|
| 可解释性强 | 缺乏平滑性(回归预测时输出值只能输出有限的若干种数值) |
| 可处理混合类型特征 | 不适合处理高维稀疏数据 |
| 具体伸缩不变性(不用归一化特征) | |
| 有特征组合的作用 | |
| 可自然地处理缺失值 | |
| 对异常点鲁棒 | |
| 有特征选择作用 | |
| 可扩展性强,容易并行 |
关于目标函数的一个非常重要的事实是,它们 must always(必须总是) 包含两个部分:training loss (训练损失) 和 regularization(正则化)。
其中 L 是训练损失函数, Ω 是正则化项。 training loss (训练损失)衡量我们的数据对训练数据的预测性。 例如,常用的训练损失是 mean squared error(均方误差,MSE)。
另一个常用的损失函数是 logistic 回归的 logistic 损失。
首先,让我们先来了解一下 xgboost 的 model(模型) : tree ensembles(树集成)。 树集成模型是一组 classification and regression trees (CART)。 下面是一个 CART 的简单的示例,它可以分类是否有人喜欢电脑游戏。
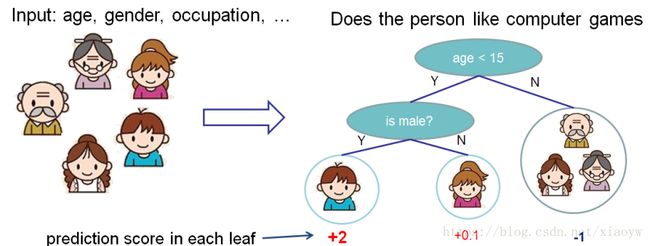
我们把一个家庭的成员分成不同的叶子,并把他们分配到相应的叶子节点上。 CART 与 decision trees(决策树)有些许的不同,就是叶子只包含决策值。在 CART 中,每个叶子都有一个 real score (真实的分数),这给了我们更丰富的解释,超越了分类。 这也使得统一的优化步骤更容易,我们将在本教程的后面部分看到。
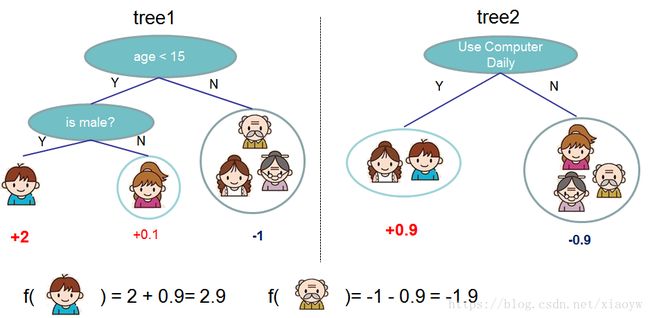
通常情况下,单棵树由于过于简单而不够强大到可以支持在实践中使用的。实际使用的是所谓的 tree ensemble model(树集成模型),它将多棵树的预测加到一起。
跳过一系列推导,我们直接来看xgboost中树节点分裂时所采用的公式:
这个公式可以分解为 1) 新左叶上的得分 2) 新右叶上的得分 3) 原始叶子上的得分 4) additional leaf(附加叶子)上的正则化。 我们可以在这里看到一个重要的事实:如果增益小于 γ,我们最好不要添加那个分支。这正是基于树模型的 pruning(剪枝) 技术!通过使用监督学习的原则,我们自然会想出这些技术工作的原因 :)
对于真实有价值的数据,我们通常要寻找一个最佳的分割。为了有效地做到这一点,我们把所有的实例按照排序顺序排列,如下图所示。
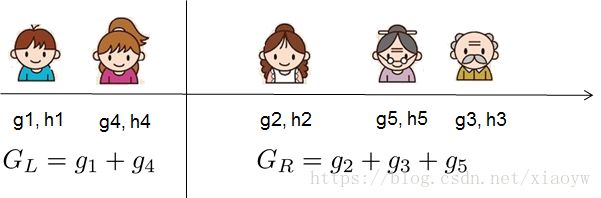
XGBoost的发起人——陈天奇博士说。
(1). XGBoost专注于模型的可解释性,而基于人工神经网络的深度学习,则更关注模型的准确度。
(2). XGBoost更适用于变量数较少的表格数据,而深度学习则更适用于图像或其他拥有海量变量的数据。
(3). 不同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。
XGBoost 所应用的算法就是 gradient boosting decision tree,既可以用于分类也可以用于回归问题中。Gradient boosting 是 boosting 的其中一种方法,所谓 Boosting ,就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法。Gradient Tree Boosting (别名 GBM, GBRT, GBDT, MART)是一类很常用的集成学习算法
作为一个非常有效的机器学习方法,Boosted Tree是数据挖掘和机器学习中最常用的算法之一。因为它效果好,对于输入要求不敏感,往往是从统计学家到数据科学家必备的工具之一,它同时也是kaggle比赛冠军选手最常用的工具。最后,因为它的效果好,计算复杂度不高,也在工业界中有大量的应用。
XGBoost 中的树形模型输出 dump model
Dump model 是一个基础特性,目前为止只有树形模型支持文本输出。
它可以把决策树用文本的方式输出出来。
booster[0]:
0:[odor=pungent] yes=2,no=1
1:[stalk-root=cup] yes=4,no=3
3:leaf=1.71218
4:leaf=-1.70044
2:[spore-print-color=orange] yes=6,no=5
5:leaf=-1.94071
6:leaf=1.85965
booster[1]:
0:[stalk-root=missing] yes=2,no=1
1:[odor=pungent] yes=4,no=3
3:leaf=0.784718
4:leaf=-0.96853
2:leaf=-6.23624基于Windows环境,首先下载第三方包,xgboost‑0.72‑cp36‑cp36m‑win_amd64.whl
Xgboost, a distributed gradient boosting (GBDT, GBRT or GBM) library.
Requires the Microsoft Visual C++ Redistributable for Visual Studio 2017.
在Win10 64bit下,安装XGBoost第三方包,安装命令如下:
D:\Python\Python36\Tools>pip install D:\Python\xgboost-0.72-cp36-cp36m-win_amd64.whl
Processing d:\python\xgboost-0.72-cp36-cp36m-win_amd64.whl
Requirement already satisfied: scipy in d:\python\python36\lib\site-packages (from xgboost==0.72)
Requirement already satisfied: numpy in d:\python\python36\lib\site-packages (from xgboost==0.72)
Installing collected packages: xgboost
Successfully installed xgboost-0.72其中,依赖scipy与numpy,详见《Python sklearn决策树算法实践》中安装过程。
示例代码说明:
(1). 从文本文件加载训练和测试数据:
dtrain = xgb.DMatrix(‘data/agaricus.txt.train’)
dtest = xgb.DMatrix(‘data/agaricus.txt.test’)
(2). 设置参数
param = {‘max_depth’:2, ‘eta’:1, ‘silent’:1, ‘objective’:’binary:logistic’}
(3). 训练模型
watchlist = [(dtest, ‘eval’), (dtrain, ‘train’)]
num_round = 2
bst = xgb.train(param, dtrain, num_round, watchlist)
(4). 预测
preds = bst.predict(dtest)
labels = dtest.get_label()
'''
Created on 2018年6月24日
@author: XiaoYW
'''
import numpy as np
import scipy.sparse
import pickle
import xgboost as xgb
### simple example
# load file from text file, also binary buffer generated by xgboost
dtrain = xgb.DMatrix('data/agaricus.txt.train')
dtest = xgb.DMatrix('data/agaricus.txt.test')
# specify parameters via map, definition are same as c++ version
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
# specify validations set to watch performance
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
num_round = 2
bst = xgb.train(param, dtrain, num_round, watchlist)
# this is prediction
preds = bst.predict(dtest)
labels = dtest.get_label()
print('error=%f' % (sum(1 for i in range(len(preds)) if int(preds[i] > 0.5) != labels[i]) / float(len(preds))))
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
bst.dump_model('dump.nice.txt', 'data/featmap.txt')
# save dmatrix into binary buffer
dtest.save_binary('dtest.buffer')
# save model
bst.save_model('xgb.model')
# load model and data in
bst2 = xgb.Booster(model_file='xgb.model')
dtest2 = xgb.DMatrix('dtest.buffer')
preds2 = bst2.predict(dtest2)
# assert they are the same
assert np.sum(np.abs(preds2 - preds)) == 0
# alternatively, you can pickle the booster
pks = pickle.dumps(bst2)
# load model and data in
bst3 = pickle.loads(pks)
preds3 = bst3.predict(dtest2)
# assert they are the same
assert np.sum(np.abs(preds3 - preds)) == 0
###
# build dmatrix from scipy.sparse
print('start running example of build DMatrix from scipy.sparse CSR Matrix')
labels = []
row = []; col = []; dat = []
i = 0
for l in open('data/agaricus.txt.train'):
arr = l.split()
labels.append(int(arr[0]))
for it in arr[1:]:
k,v = it.split(':')
row.append(i); col.append(int(k)); dat.append(float(v))
i += 1
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr, label=labels)
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
bst = xgb.train(param, dtrain, num_round, watchlist)
print('start running example of build DMatrix from scipy.sparse CSC Matrix')
# we can also construct from csc matrix
csc = scipy.sparse.csc_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csc, label=labels)
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
bst = xgb.train(param, dtrain, num_round, watchlist)
print('start running example of build DMatrix from numpy array')
# NOTE: npymat is numpy array, we will convert it into scipy.sparse.csr_matrix in internal implementation
# then convert to DMatrix
npymat = csr.todense()
dtrain = xgb.DMatrix(npymat, label=labels)
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
bst = xgb.train(param, dtrain, num_round, watchlist)运行结果:
[22:25:06] 6513x127 matrix with 143286 entries loaded from data/agaricus.txt.train
[22:25:07] 1611x127 matrix with 35442 entries loaded from data/agaricus.txt.test
[0] eval-error:0.042831 train-error:0.046522
[1] eval-error:0.021726 train-error:0.022263
error=0.021726
[22:25:07] 1611x127 matrix with 35442 entries loaded from dtest.buffer
start running example of build DMatrix from scipy.sparse CSR Matrix
[0] eval-error:0.042831 train-error:0.046522
[1] eval-error:0.021726 train-error:0.022263
start running example of build DMatrix from scipy.sparse CSC Matrix
[0] eval-error:0.042831 train-error:0.046522
[1] eval-error:0.021726 train-error:0.022263
start running example of build DMatrix from numpy array
[0] eval-error:0.042831 train-error:0.046522
[1] eval-error:0.021726 train-error:0.022263参考:
1. 《Python Package Introduction》 Scalable and Flexible Gradient Boosting 陈天奇, DMLC. All rights reserved.
2. 《XGBoost 与 Boosted Tree》 我爱计算机 陈天奇 2015年4月
3. 《周末漫谈|XGBoost与深度学习到底孰优孰劣?都说XGBoost好用,为什么名气总不如深度学习?》 搜狐/科技 来源|Quora,整理|AI100, 2017年6月
4. 《Gradient Tree Boosting (GBM, GBRT, GBDT, MART)算法解析和基于XGBoost/Scikit-learn的实现》 CSDN博客 LarryNLPIR 2017年3月
5. 《XGBoost:在Python中使用XGBoost》 CSDN博客 zc02051126 2015年7月
6. 《Python sklearn决策树算法实践》 CSDN博客 肖永威 2018年4月
注:下载,Microsoft Visual C++ 2017 Redistributable