python爬虫+R数据可视化 实例
声明:本次实例不涉及隐私信息,爬取数据全为笔者所能获取的公开信息
python 和 r语言这对黄金搭档,在数据获取,分析和可视化展示方面,各具特色,相互配合,当之无愧成为数据分析领域的两把利剑。该项目分为两个模块:1,数据准备阶段 采用python网络爬虫,实现所需数据的抓取,2,数据处理和数据可视化,采用r语言作为分析工具并作可视化展示。
第一,数据准备模块
数据来源选用笔者所在学校的内网(校内俗称OB),采用保存cookie模拟登录,以板块为单位,进行论坛帖子的抓取,并且根据发贴人的连接,再深入到发贴人的主页进行发贴人个人公开信息的抓取,最后以每一条帖子作为一条记录保存到文件,按照此逻辑笔者于2016年5月13日-2016年5月26日设置ubuntu下定时任务,按时抓取并保存获得数据,关于linux下如何设置定时任务,请参考设置linux下的定时任务。
以下进行详细分析:
首先需要载入的库:
#coding:utf-8
import urllib
import urllib2
import cookielib
import re
from bs4 import BeautifulSoup
import block_list
import time,sys,datetime,random进行模拟登录并保存cookie
需要有登录界面和论坛首页的url和保存cookie和错误日志文件
post_url = 'http://ourob.cn/bbs/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1'
url = 'http://ourob.cn/bbs/forum.php'
err_str = '' #保存error详情
filename = 'cookie_ob.txt'模拟登录和生成cookie文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#post请求参数
postdata = urllib.urlencode({
'fastloginfield':'username',
'handlekey':'ls',
'username':'my user name',
'password':'my password',
'quickforward':'yes',
'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:46.0) Gecko/20100101 Firefox/46.0',
'Connection':'keep-alive'
})
login_url = post_url
opener.open(login_url,postdata)
cookie.save(ignore_discard=True,ignore_expires=True)
尝试用cookie模拟登录论坛首页,并下载源码,提取所需字段信息
login_url = post_url
opener.open(login_url,postdata)
cookie.save(ignore_discard=True,ignore_expires=True)
try:
result = opener.open(url)
except Exception,e:
err_str += 'first page err:%s \n' %(e)
#time.sleep(random.randint(0,1))
str_0 = result.read() #str_0 列表页源码
以下即可采用正则表达式,提取 今日发帖数,会员人数,在线人数
代码如下:
#正则获取列表页 user_num,topic_num,online_num
user_num = 0
topic_num = 0
online_num = 0
pattern_topic_num = re.compile('<p class="chart z">今日: <em>(\d*?)em><span class=')
topic_num = re.findall(pattern_topic_num,str_0)[0]
pattern_user_num = re.compile('</span>会员: <em>(\d*?)em>')
user_num = re.findall(pattern_user_num,str_0)[0]
pattern_online_num = re.compile('<span class=.*?> (\d*?)strong>')
online_num = re.findall(pattern_online_num,str_0)[0]
result_0 = 'date:%s,今日发帖:%s,会员人数:%s,在线人数:%s,'%(time.ctime(time.time()),topic_num,user_num,online_num)
这种广度搜索爬虫都会涉及到需要补全链接的坑,所以本文采用定义补全链接函数,在需要的部分对该函数进行调用。
#补全链接函数
def full_url(list):
for i,item in enumerate(list):
list[i] = ('http://ourob.cn/bbs/' + item.replace('amp;',''))
return list
接下来,就是深入到各个板块下进行爬取,事先定义好了一个盛放各板块url的.py文件block_list,已经在开始部分导入,还需要增加翻页功能,如下:
#板块下爬虫
block_url = []
block_url = block_list.block_url
#增加翻页功能:简单起见,只翻2页
for i in range(31):
list_temp = []
list_temp.append(block_url[i][0] + '&page=2')
list_temp.append(block_url[i][1])
block_url.append(list_temp)
后续的部分思路相对比较简单,但是涉及到提取字段,代码部分比较复杂,这里值得提一下的是:有的网站登录一段时间由于某些原因是会失效的(ob就是),但是究竟多久失效,这个没办法知道,所以为了避免因为登录失效而导致爬去失败或者数据丢失,干脆直接采用抓取页面前,均使用cookie重新登录,实现如下(提取字段部分不全):
for i in range(0,62):#range(len(block_url)):
print 'num:%d,block_name:%s,blcok_url:%s'%(i,block_url[i][1],block_url[i][0])
#print block_url[i][0],block_url[i][1]
str_1 = '' #临时存储板块源码,用于后续提取正文url
list_1 = [] #临时存储列表页中当日帖子的正文url
try:
cookie = cookielib.MozillaCookieJar()
cookie.load('cookie_ob.txt',ignore_discard=True,ignore_expires=True)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
opener.open(login_url,postdata)
str_1 = opener.open(block_url[i][0]).read()
except Exception,e:
err_str += 'block url:%s err:%s ' %(block_url[i][0],e)
import time
#time.sleep(random.randint(9,10))
'''
list_1 = str_1.split('em>\.\*\?')
print len(list_1)
'''
if str_1 != '':
soup = BeautifulSoup(str_1)
#print soup.prettify()
for tag in soup.find_all('td'):
if tag.em != None:
if tag.em.span != None:
if tag.em.span.has_attr('class') and tag.em.span.get('class')[0] == 'xi1':
#print tag.em.span.string
#if tag.previous_sibling.previous_sibling.a.has_attr('class'):
list_1 = re.findall(re.compile('href="(.*?)"'),str(tag.previous_sibling.previous_sibling.find_all('a',class_='xst')))
#调用函数,自动补全list中url
list_1 = full_url(list_1)
#进行下一层爬虫-正文页
for item in list_1:
str_2 = '' #临时存储正文页源码,供后续提取字段
str_3 = '' #临时存储楼主主页源码,供提取相关字段
name='';time='';view_num='';comment_num='';title = ''
#print item
try:
str_2 = opener.open(item).read()
except Exception,e:
err_str += 'content url:%s err:%s ' %(item,e)
#以下类似 省略
最终得到的数据是这个样子的:

第二,数据处理和数据可视化
主要采用r语言读取数据,进行频数统计和图表展示
简单贴几段代码:
读取剪切板数据
并采用table()函数求频数
data3<-read.table("clipboard",header = T)
tb3<-as.data.frame(table(data3))
colnames(tb3) <- c("b_type","freq")柱状图
#柱状图
p <- ggplot(data = tb3, aes(x=b_type,y=freq))
p + geom_bar(stat="identity" , width = 0.4, fill = "cornflowerblue") + ggtitle("13-26日发帖人血型统计")
折线图
ggplot(data=data1,aes(x=time))+geom_line(aes(y=在线人数,colour="在线人数"))+geom_line(aes(y=今日发帖,colour="今日发帖"))
+ scale_colour_manual("items",values = c("在线人数" = "red","今日发帖" = "blue"))
饼图
#饼图
p<-ggplot(data=tb3,aes(x="",y=freq,fill=factor(b_type)))+geom_bar(stat="identity",width=1)
#p+ geom_bar(stat="identity" , width = 0.8, fill = "cornflowerblue")+coord_polar(theta="y")
p+coord_polar(theta = "y")+ ggtitle("13-26日 发帖人血型分布")
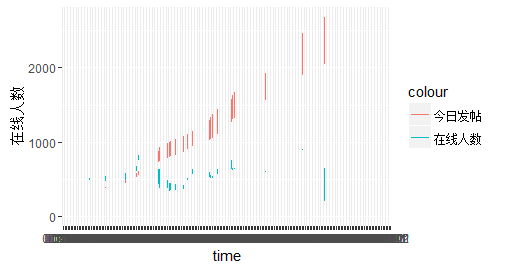
很显然,发帖数和在线人数呈现正相关关系,二者在23:30左右的时候急速下降,主要是由于校内这个时候断网,断电,大家也都该洗洗睡了~,一直到早上7:20左右,人数开始回升,从这也可以看出童鞋们起床时间还是很早滴(因为要上课…),在线人数全天除了后半夜基本保持在500以上,上图:

r语言版
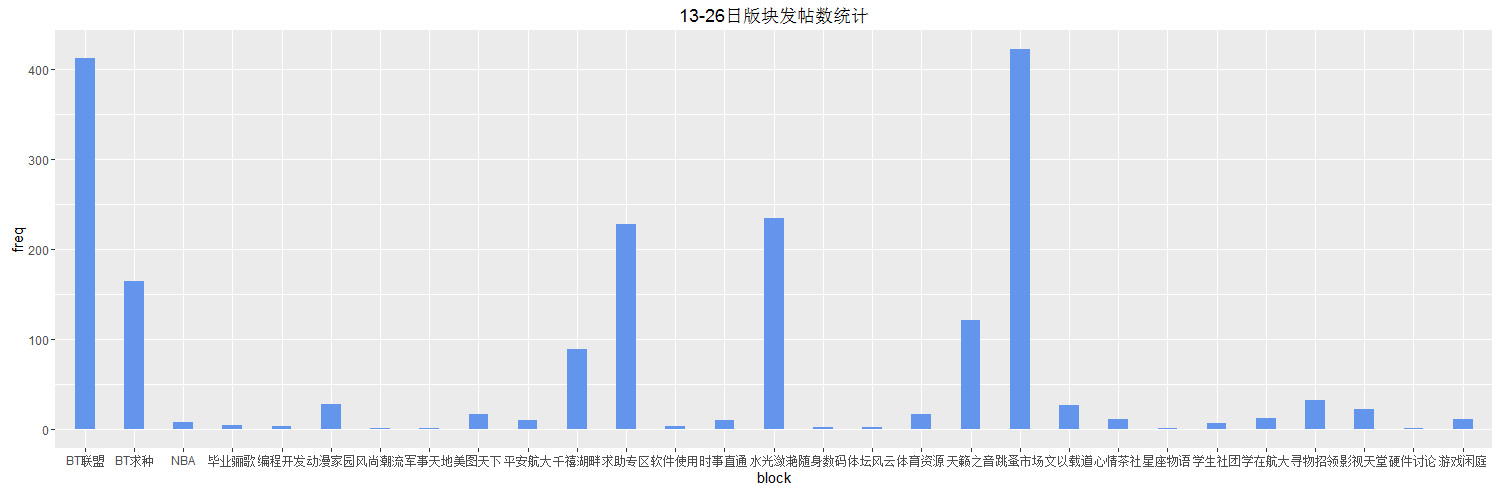
发帖人数统计,呈现波动性很大,通过查询日历,显而易见,发帖数高的日期13,14,21,22均为周末,看来大家周末放松的方式之一还真是逛~O~B,再看16,17,18可想而知童鞋们都胶着在上课,作业中,无暇顾及玩ob了…

从板块角度来看,人们对不同板块有不同的热爱,但是结果上,分布很不均匀,基本上大家经常水的就那么几个,有些则是很久页无人问津…

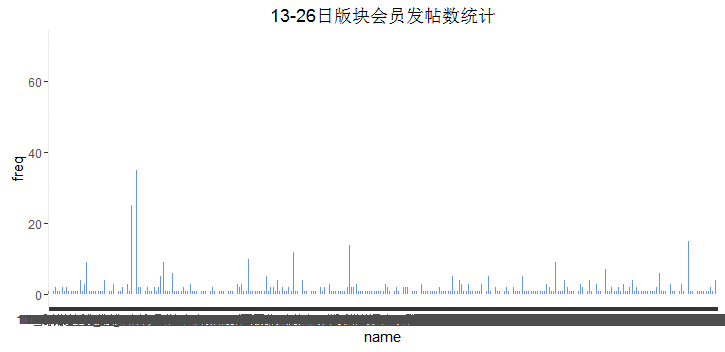
从ob会员上来看,分布依然很不均匀,活跃的就是那么几个(我猜大部分比较活跃的都是版主有木有~~)
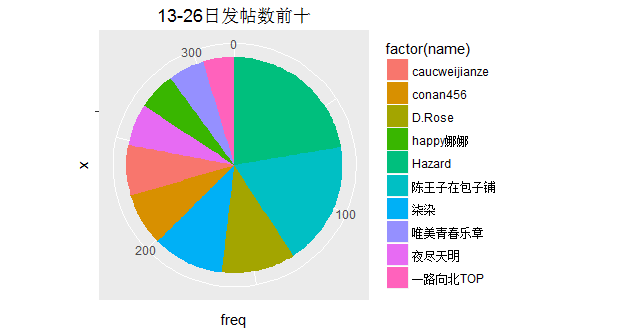
这里统计了一下,发帖数排名前十的,会员昵称,能找到你自己么??
那么还有一个问题,大家都是在几点比较容易发帖呢??用数据说话,接着看图…

结果就是发帖时间有两个高峰:一个是上午九点到十点,另一个是晚上七点到十点,也比较符合预期。
辛苦抓取了帖子作者的信息,我们来看一看,都是哪一级的学生经常浪迹ob,说实话,当我看到结果的时候,瞬间觉得我已经在沙滩上了。。。

来一张一目了然的~

喜欢发帖和出生月份有木有关系??,来看看…

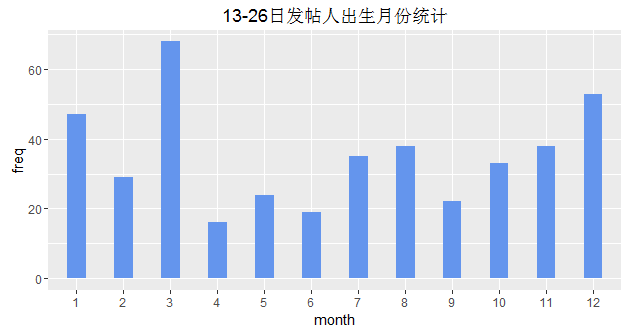
当然还要精确到天…


最后,还有血型
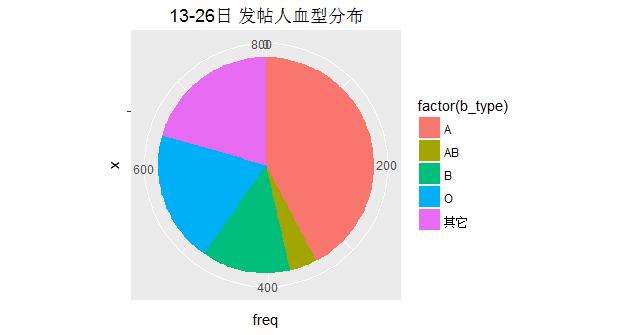

难道是说A型血,更倾向于逛ob吗,道理在哪里???
到此,全部结束