大数据学习——HBase 入门
HBase
学习环境
shiyanlou 《HBase介绍、安装与应用案例》
- CentOS6.6 64位
- JDK 1.7.0_55 64位
- Hadoop 1.1.2
Hbase 介绍
HBase ——Hadoop Database,是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase 利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google BigTable利用Chubby作为协同服务,HBase使用的是Zookeeper作为对应。
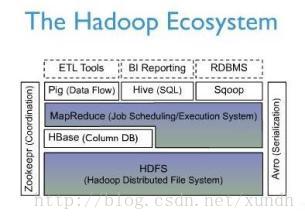
HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持,MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig和Hive为Hbase提供了高层语言支持,使得在HBase上进行数据统计处理变得简单。
Sqoop则为HBase提供了方便的RDBMS数据导入功能。
HBase官网: http://hbase.apache.org/
HBase特点
- 强一致性读写:HBase 不是“eventually consistent(最终一致性)”数据存储。这让它很适合高速计数聚合类任务;
- 自动分片(Automatic sharding): HBase 表通过 region 分布在集群中。数据增长时,region 会自动分割并重新分布;
- RegionServer 自动故障转移;
- Hadoop/HDFS 集成:HBase 支持开箱即用地支持 HDFS 作为它的分布式文件系统;
- MapReduce: HBase 通过 MapReduce 支持大并发处理;
- Java 客户端 API:HBase 支持易于使用的 Java API 进行编程访问;
- Thrift/REST API:HBase 也支持 Thrift 和 REST 作为非 Java 前端的访问;
- Block Cache 和 Bloom Filter:对于大容量查询优化, HBase 支持 Block Cache 和 Bloom Filter;
- 运维管理:HBase 支持 JMX 提供内置网页用于运维。
HBase应用场景
- 足够多数据,上亿或上千亿行数据
- 不依赖RDBMS的特性,如列类型、第二索引、事务、高级查询等
- 有足够的硬件,少于5节点Hadoop时,基本体现不出优势
优缺点
优点
- 列的可以动态增加,并且列为空就不存储数据,节省存储空间
- Hbase 自动切分数据,使得数据存储自动具有水平扩展
- Hbase 可以提供高并发读写操作的支持
- 与 Hadoop MapReduce 相结合有利于数据分析
- 容错性
- 版权免费
- 非常灵活的模式设计(或者说没有固定模式的限制)
- 可以跟 Hive 集成,使用类 SQL 查询
- 自动故障转移
- 客户端接口易于使用
- 行级别原子性,即,PUT 操作一定是完全成功或者完全失败
缺点
- 不能支持条件查询,只支持按照 row key 来查询
- 容易产生单点故障(在只使用一个 HMaster 的时候)
- 不支持事务
- JOIN 不是数据库层支持的,而需要用 MapReduce
- 只能在逐渐上索引和排序
- 没有内置的身份和权限认证
HBase 访问接口
- Native Java API
- HBase Shell
- Thrift Gateway
- REST Gateway:支持REST网格的HTTP API访问HBase
- Pig:Pig Latin流式编程语言来操作HBase中的数据。
- Hive:0.7.0版本的Hive加入HBase
HBase 数据模型

- Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
- Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
- Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Table & Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同region会被Master分配给相应的RegionServer进行管理。
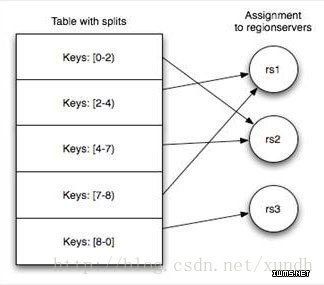
HBase中有两张特殊的Table, -ROOT- 和 .META.
- .META. :记录了用户表的Region信息,.META.可以有多个region
- -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
- Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
MapReduce on HBase
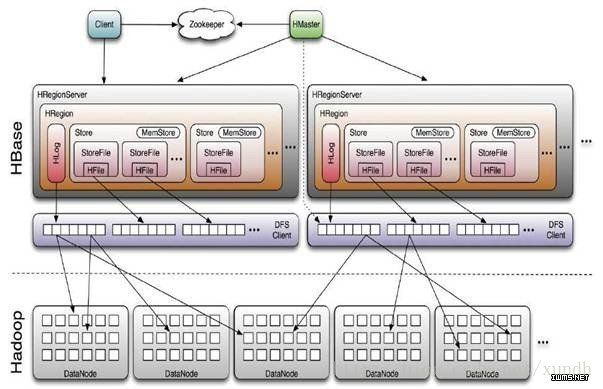
HBase 系统架构
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC。
Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到 Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的 单点问题。
HRegionServer
用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
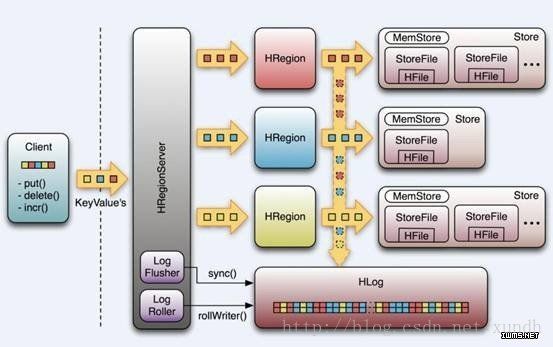
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个 Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
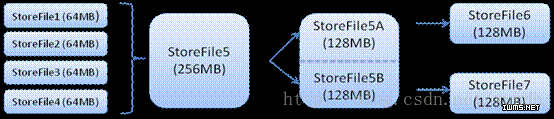
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。 MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进 行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要 进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前 Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
在理解了上述HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问 题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需 要引入HLog了。每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并 删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知 到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase 存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:
HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile 格式
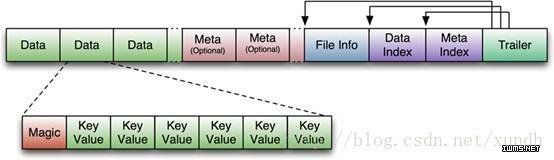
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer 中有指针指向其他数据块的起始点。File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey 的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数 值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HLogFile
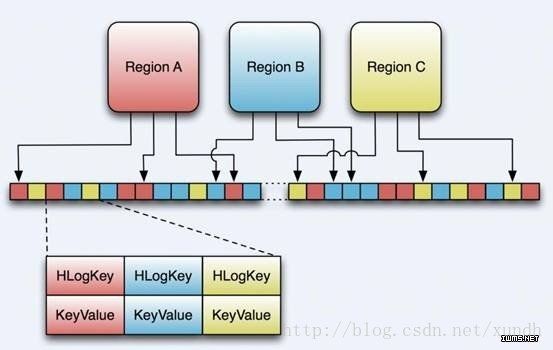
上图中示意了HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
Hadoop与HBase版本对应关系
版本
| HBase-0.94.x | HBase-0.98.x | HBase-1.0.x | HBase-1.1.x | HBase-1.2.x | Hadoop-1.0.x |
|---|---|---|---|---|---|
| X | X | X | X | X | |
| Hadoop-1.1.x | S | NT | X | X | X |
| Hadoop-0.23.x | S | X | X | X | X |
| Hadoop-2.0.x-alpha | NT | X | X | X | X |
| Hadoop-2.1.0-beta | NT | X | X | X | X |
| Hadoop-2.2.0 | NT | S | NT | NT | X |
| Hadoop-2.3.x | NT | S | NT | NT | X |
| Hadoop-2.4.x | NT | S | S | S | S |
| Hadoop-2.5.x | NT | S | S | S | S |
| Hadoop-2.6.0 | X | X | X | X | X |
| Hadoop-2.6.1+ | NT | NT | NT | NT | S |
| Hadoop-2.7.0 | X | X | X | X | X |
| Hadoop-2.7.1+ | NT | NT | NT | NT | S |
- S = supported and tested,支持
- X = not supported,不支持
- NT = not tested enough.可以运行但测试不充分
Hadoop和JDK版本对应关系
| Hbase版本 | JDK 6 | JDK 7 | JDK 8 |
|---|---|---|---|
| 1.2 | Not Supported | yes | yes |
| 1.1 | Not Supported | yes | Not Supported |
| 1 | Not Supported | yes | Not Supported |
| 0.98 | yes | yes | Not Supported |
| 0.94 | yes | yes | N/A |
数据模型操作
Get、Put、Scan 和 Delete安装部署HBase
cd /home/shiyanlou/install-pack
tar -zxf hbase-0.96.2-hadoop1-bin.tar.gz
mv hbase-0.96.2-hadoop1 /app/hbase-0.96.2
sudo vi /etc/profileexport HBASE_HOME=/app/hbase-0.96.2
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
hbase version
cd /app/hbase-0.96.2/conf
sudo vi hbase-env.shexport JAVA_HOME=/app/lib/jdk1.7.0_55
export HBASE_CLASSPATH=/app/hadoop-1.1.2/conf
export HBASE_MANAGES_ZK=true
cd /app/hbase-0.96.2/conf
sudo vi hbase-site.xml<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop:9000/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>bb5264235bb1value>
property>
configuration>启动并验证
cd /app/hadoop-1.1.2/bin
./start-all.sh
cd /app/hbase-0.96.2/bin
./start-hbase.sh
hbase shell创建表
hbase> create 'member','m_id','address','info'
list示例
学生成绩表:
| name | grad | course:math | course:art |
|---|---|---|---|
| Tom | 1 | 87 | 97 |
| Jerry | 2 | 100 | 80 |
这里grad对于表来说是一列,course对于表来说是一个列族,这个列族由两个列组成:math和art。
hbase> create 'scores','grade','course'
hbase> describe 'scores'新建Tom行
hbase> put 'scores','Tome','grade:','1'
hbase> put 'scores','Tome','course:math','87'
hbase> put 'scores','Tome','course:art','97'新建 Jerry行
hbase> put 'scores','Jerry','grade:','2'
hbase> put 'scores','Jerry','course:math','100'
hbase> put 'scores','Jerry','course:art','80'查看表
hbase> get 'scores','Tom'查看scores表所有数据
hbase> scan 'scores'文章内容主要来源:
- 实验楼
- http://www.thebigdata.cn/QiTa/14677.html