线性回归-梯度下降法(波斯顿房价数据集)
数据集下载波斯顿房价数据集
import numpy as np
import pandas as pd
data = pd.read_csv("housing.csv")
data.head()class LinearRegression:
"""使用ptyhon实现线性回归算法,使用梯度下降法"""
def __init__(self,alpha,times):
"""初始化方法
Parameters:
----
alpha : float
学习率,用来控制步长(权重调整幅度)
times : int
循环迭代的次数
"""
self.alpha = alpha
self.times = times
def fit(self,X,y):
"""根据提供的训练数据对模型进行训练
Parameters:
X:类数组类型,形状[样本数量,特征数量]
待训练的样本特征属性,特征矩阵
y:类数组类型,形状[样本数量]
目标值,标签的信息
"""
X = np.asarray(X)
y = np.asarray(y)
#初始权重,权重向量初始值为0(或任何其他值),长度比X的特征数量多1(多出来的为截距)
self.w_ = np.zeros(1 + X.shape[1])
#创建损失列表,用来保存每次迭代后的损失值。损失值计算(损失函数):(预测值-真实值)的平方和 再除以2
self.lose_ = []
#进行循环,多次迭代。在每次迭代过程中,不断去调整权重值,使得损失值不断减小
for i in range(self.times):
#计算预测值
#np.dot(),计算点积
y_hat = np.dot(X,self.w_[1:]) + self.w_[0]
#计算真实值与预测值之间的差距
error = y - y_hat
#将损失加入到损失列表中
self.lose_.append(np.sum(error ** 2) / 2)
#根据差距(预测值与真实值),调整权重self.w_,根据公式调整为 权重(j) = 权重(j) + 学习率alpha * sum((y - y_hat) * x(j))
self.w_[0] += self.alpha * np.sum(error)
self.w_[1:] += self.alpha * np.dot(X.T,error)
def predict(self,X):
"""根据传递的样本,对样本进行预测
Parameters:
X:类数组类型,形状[样本数量,特征数量]
测试的样本
Return:
----
result:数组类型
预测结果
"""
X = np.asarray(X)
result = np.dot(X,self.w_[1:]) + self.w_[0]
return result#data洗牌,造成数据特别大的原因是:原始数据的数量基相差特别大
t = data.sample(len(data),random_state=0)
train_X = t.iloc[:400,:-1]
train_y = t.iloc[:400,-1]
test_X = t.iloc[400:,:-1]
test_y = t.iloc[400:,-1]
lr = LinearRegression(0.0005,20)
lr.fit(train_X,train_y)
result = lr.predict(test_X)
display(np.mean(result - test_y) ** 2)
display(lr.w_)
display(lr.lose_)
class StanderScaler:
"""对数据进行标准化处理。即均值为0,标准差为1
"""
def fit(self,X):
"""根据传递的样本,计算每个特征列的均值和标准差。
Parameters:
----
X:类数组类型
训练数据,用来计算均值和标准差
"""
X = np.asarray(X)
self.std_ = np.std(X,axis=0)
self.mean_ = np.mean(X,axis=0)
def transform(self,X):
"""对给定的数据X,进行标准化处理。(将X的每一列都变成标准正太分布的数据)
Parameters:
----
X:类数组类型
待转换的数据
Return:
----
result:类数组类型
参数X转换成标准正态分布后的结果
"""
return (X - self.mean_) / self.std_
def fit_transform(self,X):
"""对数据进行训练并转换,返回转换后的结果
Parameters:
----
X:类数组类型
待转换的数据
Return:
----
result:类数组类型
参数X转换成标准正态分布后的结果
"""
self.fit(X)
return self.transform(X)#为了避免每个特征数量级的不同,从而在梯度下降的过程中带来影响
#现在考虑对每个特征进行标准化处理
#data洗牌
s = StanderScaler()
data_s = s.fit_transform(data)
t = data_s.sample(len(data_s),random_state=0)
train_X = t.iloc[:400,:-1]
train_y = t.iloc[:400,-1]
test_X = t.iloc[400:,:-1]
test_y = t.iloc[400:,-1]
lr = LinearRegression(0.0005,20)
lr.fit(train_X,train_y)
result = lr.predict(test_X)
display(np.mean(result - test_y) ** 2)
display(lr.w_)
display(lr.lose_)#直线拟合可视化
import matplotlib as mpl
import matplotlib.pyplot as plt
#设置matplotlib 支持中文显示
mpl.rcParams['font.family'] = 'SimHei' #设置字体为黑体
mpl.rcParams['axes.unicode_minus'] = False #设置在中文字体是能够正常显示负号(“-”)
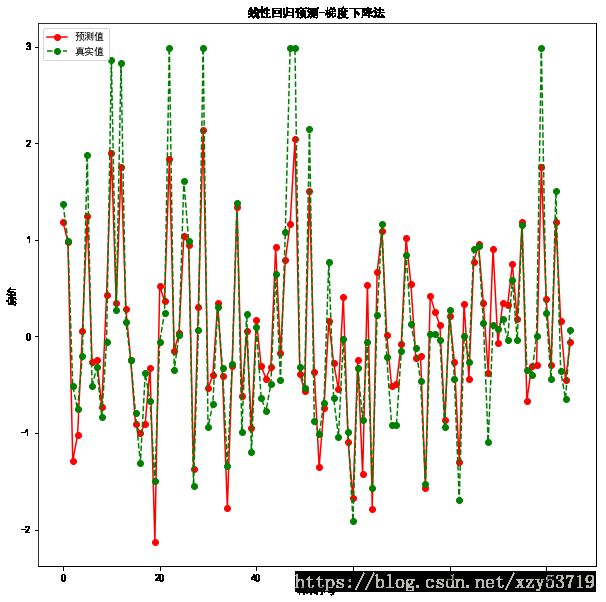
plt.figure(figsize=(10,10))
#绘制预测值
plt.plot(result,'ro-',label="预测值")
plt.plot(test_y.values,'go--',label="真实值")
plt.title("线性回归预测-梯度下降法")
plt.xlabel("样本序号")
plt.ylabel("房价")
plt.legend()
plt.show()