CVPR 2018 | 腾讯AI Lab关注的三大方向与55篇论文
感谢阅读腾讯 AI Lab 微信号第 32 篇文章,CVPR 2018上涌现出非常多的优秀论文,腾讯 AI Lab 对其中精华文章归类与摘要,根据受关注程度,对生成对抗网络、视频分析与理解和三维视觉三大类论文进行综述。
第一部分:生成对抗网络
1.1 Learning to Generate Time-Lapse Videos Using Multi-Stage Dynamic Generative Adversarial Networks
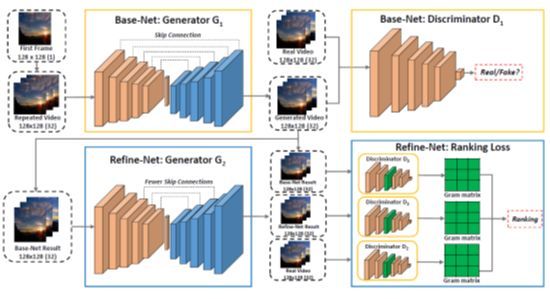
这个工作由腾讯 AI Lab 和罗切斯特大学共同完成,主要研究的问题是给定第一帧,如何生成接下来的视频帧,使得生成的画面兼具有真实的内容和生动的运动。为了完成这个任务,作者提出了一个多阶段的动态生成网络。具体地,在第一阶段,生成网络专注于生成真实的内容,判别网络进行“真”和“假”的二分类任务;在第二阶段的生成网络专注于对第一阶段的输出视频进行优化,使之具有生动的运动信息。为了达到这个目的,作者引入了 gram 矩阵并且提出了一个排序损失(ranking loss),使得生成的视频的运动信息与真实视频更加接近。该工作在一个提出的 Sky Scene 数据集上面取得了当前的最优性能。
1.2 PairedCycleGAN: Asymmetric Style Transfer for Applying and Removing Makeup
这个工作由普林斯顿大学、Adobe Research 和加利福尼亚大学伯克利分校共同完成,主要研究的是给定一幅没有化妆的人物图像 A 和一幅带妆容的参考图像 B,如何给人物图像 A 自动上妆。作者通过一种不对称的风格转换来完成这一目的。具体地,作者同时学习一个上妆函数对 A 进行上妆得到 A' 和一个移除妆容的函数对 B 进行移除妆容的操作得到 B',然后再次对 B' 进行化妆操作得到 B" 和对 A' 进行移除妆容操作得到 A",通过约束 A" 与 B" 分别与 A 和 B 接近来学习整个风格转换。作者在不同的人物图像和妆容风格上面取得了不错的结果。

1.3 SeGAN: Segmenting and Generating the Invisible
这个工作由华盛顿大学和艾伦人工智能研究所(AI2)共同完成,主要研究的是如何对被遮挡的物体完成补全。这个挑战性的问题同时涉及到分割和生成两个任务。研究者提出了 SeGAN 来解决这个问题。具体地,输入一张图像和它的可见部分的分割掩码(mask),该工作通过学习分割网络来得到不可见部分的分割结果,再通过 GAN 来对这些不可见部分进行补全,更为重要的是这两个任务在同一个框架里面进行联合优化,从而得到最终的输出。该工作取得了当前的最佳结果。
1.4 Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network
该工作由佛罗里达大学完成,主要研究的是给定文本描述生成高分辨率图像的任务,作者设计了一个单流式(single-stream)生成器,在生成器的不同阶段对生成结果通过判别器进行判别,这种一个生成器加多个判别器的结构被称为级联式对抗网络。实验证明,该方法在 3 个公开数据集上取得当前最佳结果。

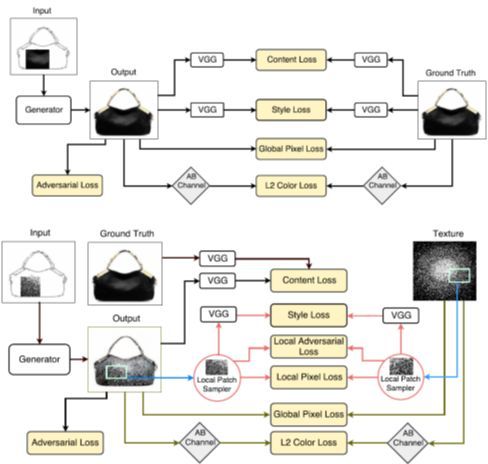
1.5 TextureGAN: Controlling Deep Image Synthesis with Texture Patches
该工作由佐治亚理工学院、Adobe Research、加利福尼亚大学伯克利分校和 Argo AI 共同完成。主要研究的是给定一个简笔画和一个带纹理的图块,对简笔画进行纹理生成。作者提出了一个局部纹理损失和内容损失进行生成网络的训练,实验结果证明该方法生成了合理的图像。上图为有基本真值的预训练阶段,下图为微调阶段。
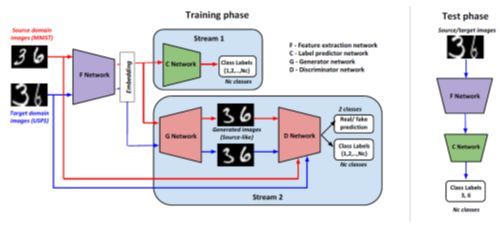
1.6 Generate To Adapt: Aligning Domains using Generative Adversarial Networks
该工作由马里兰大学帕克分校完成。主要研究的是如何对迁移学习里面的源域和目标域进行对齐的问题。具体地,作者通过一个两路的 F-C-G-D 网络完成该任务。其中 F 网络进行特征提取,C 网络对源域的样本进行分类,G 网络作为生成网络生成跟源域类似的样本,D 网络同时进行真/假的二分类判别任务和多分类任务。通过实验环节的 3 个任务,作者证明了该方法的有效性。
1.7 Disentangled Person Image Generation
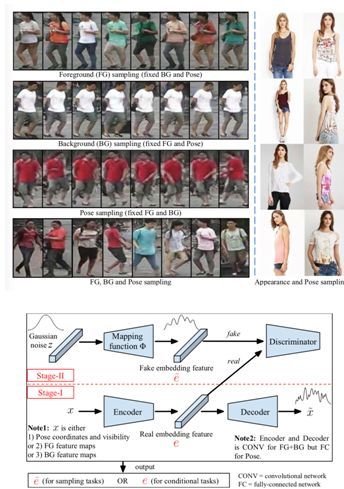
本文由丰田汽车欧洲公司、苏黎世联邦理工学院、MPII合作完成,是 CVPR 2018 的 spotlight 文章。 在基于 GAN 的人脸图像生成技术趋于成熟后,人们将注意力转向了基于 GAN 的人像生成。本文将人像信息拆解为三个部分:前景、背景和姿态。本文提出了一种两阶段的全身人像重建方法,将前景、背景和姿态三部分的嵌入特征(embedding feature)解耦。在第一阶段,一个多分支的重建网络被用于编码生成上述三部分的嵌入特征,然后将这三部分的嵌入特征被组合到一起用于重建输入图像,相当于一个中间具有多分支的自动编码器(auto-encoder)。第一阶段的自编解码器用真实图像进行训练,可以提取真实图像的嵌入特征。在第二阶段,用对抗的方式训练一个转码器和判别器。转码器学习如何将Gaussian噪声映射成与真实图像相近的伪嵌入特征。判别器学习如何区分真实嵌入特征和伪嵌入特征。针对前景、背景、姿态三部分,需要分别训练三组转码器和判别器。利用该两阶段方法,可以独立地操纵其中任意一部分的特征,保持其它部分的特征不变,完成更换背景、更换前景、更换姿态等应用。本文在 Market-1501 和 Deepfashion 数据集上进行了训练和测试,能够生成较为真实的人像,且能够独立操纵前景、背景和姿态等因子。
1.8 Super-FAN: Integrated facial landmark localization and super-resolution of real-world low-resolution faces in arbitrary poses with GANs
本文由诺丁汉大学完成,是 CVPR 2018的 spotlight 文章。本文提出了一种称为 Super-FAN 的方法,能够同时完成人脸关键点定位和超分辨率两个任务。本文通过对抗的方式训练了一个生成器和两个判别器。生成器用于完成人脸超分辨率的任务。一个判别器用于判断生成器的超分辨率结果是否为真实的人脸,另一个判别器用于在生成器的超分辨率结果上完成关键点定位。使用本文提出的方法,能够同时在人脸超分辨率和人脸关键点定位两个任务上都取得提升。实验证明这种联合训练方式优于先训练一个超分辨率网络完成人脸超分辨率再在超分辨率结果上做独立的人脸关键点定位的工作。本文的方法对其它受低分辨率输入困扰的检测任务具有借鉴意义。

1.9 Attentive Generative Adversarial Network for Raindrop Removal from A Single Image
本文由北京大学、新加坡国立大学和耶鲁-新加坡国立大学学院完成,是 CVPR 2018 的 spotlight 文章。 积聚在镜头上的雨滴会严重损害照片的视觉效果。本文提出了一种照片去雨滴的方法,能够有效地将照片中的雨滴去除。为了完成这一任务,本文提出了一种注意力生成模型——在对抗式训练的过程中,将注意力模块加入到生成器和判别器中。注意力模块学习了如何定位雨滴出现的位置,能够更好地指导生成器和判别器关注雨滴出现的局部区域。本方法的结果较之前方法的结果有较为明显的提升。

1.10 Multistage Adversarial Losses for Pose-Based Human Image Synthesis
本文由中国科学院大学完成,是 CVPR2018 的 spotlight文章。本文关注的是给定一幅人像,如何生成指定的另一个视角的人像。生成新视角的相关工作已经有很多,但主要关注的都是刚性物体,如椅子、楼房、汽车等。相对于刚性物体而言,人体是非刚性的,姿态更为多样,因此生成新视角的人像是一个极具挑战性的问题。本文以多视角姿态估计为辅助,使用了多阶段对抗损失函数训练了一个多阶段的转换网络。本文的方法分为三个阶段。第一阶段,先使用已有的方法估计输入图像的 2D 姿态估计结果,然后训练一个网络来生成指定视角的 2D 姿态估计结果。第二阶段,使用已有的方法将人从图像中分割出来,然后以原始 2D 姿态和目标 2D 姿态作为辅助输入,训练一个前景转换网络完成目标新视角前景的生成。第三阶段,输入第二阶段的新视角前景和原始图像,训练一个背景转换网络完成目标新视角背景的生成。本文在 Human3.6M 数据集上进行了测试,能够在保持姿态不变的情况下,生成较为逼真的新视角人像。

1.11 Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs
本文由台湾大学完成,是 CVPR 2018 的 spotlight 文章。图像美化一直是计算机视觉领域的重要主题,在诸多图片编辑软件和拍摄软件中具有广泛应用。本文提出了一种双路的对抗生成网络,与 CycleGAN 类似。为了改善效果,本论文提出了多方面的优化。其一,生成器在传统 UNet 结构的基础之上,加入了全局特征使得网络能够同时捕捉全局和局部信息。其二,使用了一个自适应的权重赋值方案来提升 WGAN 的效果,能够更快更好地收敛,而且相对 WGAN-GP 而言对参数更加不敏感。其三,在生成器中使用了个体批规范化(individual batch normalization),使得生成器更适应于输入的分布。这些细节的改动使得本文的方法在图像美化这一应用上取得了不错的效果。

1.12 StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
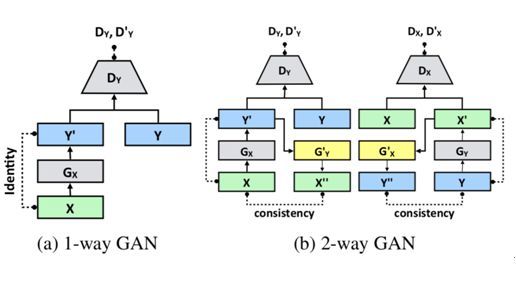
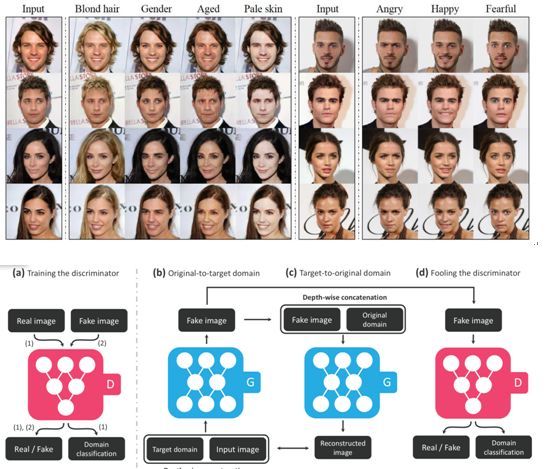
本文由高丽大学、NAVER、新泽西学院、香港科技大学合作完成 ,是 CVPR 2018 的 oral 文章。近期图像间翻译问题已经在两个域的情况下取得了很大的进展。然而,现有方法的可扩展性和鲁棒性都不足以完成两个域以上的图像间翻译问题。针对多个域的问题,最直接的做法是每两个域之间都单独训练一个转换模型,然而这种做法是十分冗余的,而且在数据有限的情况下很难取得出色的结果。为了解决这个问题,本文提出了一种 StarGAN 结构,使用多个域之间的图像翻译训练数据完成对抗训练,能够使用一个模型完成多个域之间的图像间翻译问题。具体地,在训练生成器的过程中,除了给定输入图像还会给定目标域的标签;同时还训练判别器在判别真假的同时判别生成结果所处的域,相当于是一种条件对抗生成网络。训练过程中会混合使用多个域之间的图像对,使得同一个生成器能够完成多个域之间的转换问题。
1.13 High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
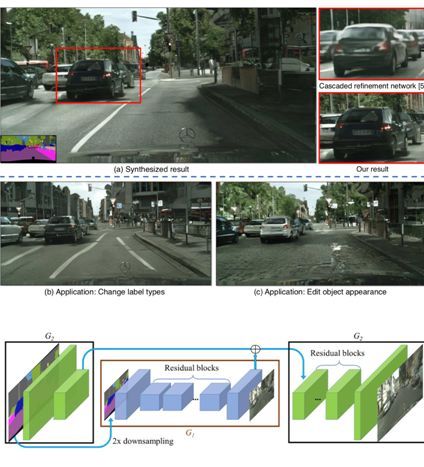
本文由英伟达和加利福尼亚大学伯克利分校合作完成,是 CVPR 2018 的 oral 文章。本文提出了一种基于条件生成对抗网络(Conditional GAN)的图像生成方法,能够将语义分割标签图转换成高分辨率的真实图像。已有的条件生成对抗网络虽然能完成类似的任务,但是只局限在低分辨的图像上。本文生成的结果分辨率高达 2048x1024,而且拥有极高的真实感。为了达到这样的效果,本文提出了一种新的对抗损失函数以及多尺度的生成器和判别器结构。具体地,本文将生成器拆分成 G1 和 G2 两个子网络。其中 G1 生成低分辨率的转换结果;G2 在 G1 的基础之上进一步优化结果的精细度,生成更高分辨率的结果。另一方面,本文训练了三个判别器来判断不同尺度的结果是否为真实图像,从而提供三种不同尺度的对抗损失来指导生成器的训练。此外,本文还展示了如何利用条件生成对抗网络完成交互式的图像编辑应用,如删除和增加物体、更换物体的外表等。
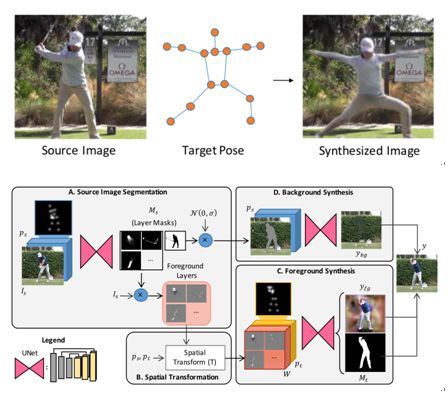
1.14 Synthesizing Images of Humans in Unseen Poses
本文由麻省理工学院完成,是 CVPR 2018 的 oral 文章。本文研究的是如何生成具有目标姿态的人像照片的问题。本文以对抗的方式训练了一个生成器,该生成器对人体的不同部位分别完成转换,再组合成新的前景。具体地,首先为每个部位生成单独的掩码(mask),然后利用掩码将每个部位单独提取出来,通过空域转换模型(Spatial Transformer)完成变形,再组合成具有新姿态的完整全身人像作为前景。新背景则由原来的背景抠除人之后利用神经网络进行填补得来。本文主要在三种动作上进行了测试,包括打高尔夫球、健身和网球。使用本文的方法还能够在给定一幅输入图像和一组目标姿态序列的情况下,生成一个符合目标姿态序列的视频。但目前方法仍然局限于瑜伽、网球、高尔夫三种动作。
第二部分:视频分析与理解
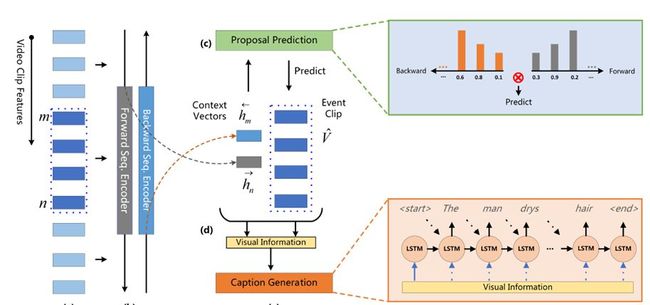
2.1 Bidirectional Attentive Fusion With Context Gating for Dense Video Captioning
本文由腾讯 AI Lab 与华南理工大学合作完成,是今年 CVPR 2018 的 spotlight 文章。密集视频描述是一个时下刚兴起的课题,旨在同时定位并用自然语言描述一个长视频中发生的所有事件或行为。在这个任务中,本文明确并解决了两个挑战,即:(1)如何利用好过去和未来的信息以便更精确地定位出事件,(2)如何给解码器输入有效的视觉信息,以便更准确地生成针对该事件的自然语言描述。第一,过去的工作集中在从正向(视频从开头往结尾的方向)生成事件候选区间,而忽视了同样关键的未来信息。作者引入了一种双向提取事件候选区间的方法,同时利用了过去和未来的信息,从而更有效地进行事件定位。第二,过去的方法无法区分结束时间相近的事件,即给出的描述是相同的。为了解决这个问题,作者通过注意力机制将事件定位模块中的隐状态与视频原始内容(例如,视频 C3D 特征)结合起来表征当前的事件。进一步地,作者提出一种新颖的上下文门控机制来平衡当前事件内容和它的上下文对生成文字描述的贡献。作者通过大量的实验证明,相比于单独地使用隐状态或视频内容的表征方式,新提出的注意力融合的事件表征方式表现更好。通过将事件定位模块和事件描述模块统一到一个框架中,本文的方法在 ActivityNet Captions 数据库上超过了之前最好的方法,相对性能提升 100%(Meteor 分数从 4.82 到 9.65)。
2.2 End-to-End Learning of Motion Representation for Video Understanding
本文由腾讯 AI Lab、清华大学、MIT-Watson 实验室、斯坦福大学合作完成,是 CVPR 2018 的 spotlight 文章。尽管端到端的特征学习已经取得了重要的进展,但是人工设计的光流特征仍然被广泛用于各类视频分析任务中。为了弥补这个不足,作者创造性地提出了一个能从数据中学习出类光流特征并且能进行端到端训练的神经网络:TVNet。当前,TV-L1 方法通过优化方法来求解光流,是最常用的方法之一。作者发现,把 TV-L1 的每一步迭代通过特定设计翻译成神经网络的某一层,就能得到 TVNet 的初始版本。因此,TVNet 能无需训练就能被直接使用。更重要的是,TVNet 能被嫁接到任何分类神经网络来构建从数据端到任务端的统一结构,从而避免了传统多阶段方法中需要预计算、预存储光流的需要。最后,TVNet 的某些参数是可以被通过端到端训练来进一步优化,这有助于 TVNet 学习出更丰富以及与任务更相关的特征而不仅仅是光流。在两个动作识别的标准数据集 HMDB51 和 UCF101 上,该方法取得了比同类方法更好的分类结果。与 TV-L1 相比,TVNet 在节省光流提取时间和存储空间的基础上,明显提高了识别精度。

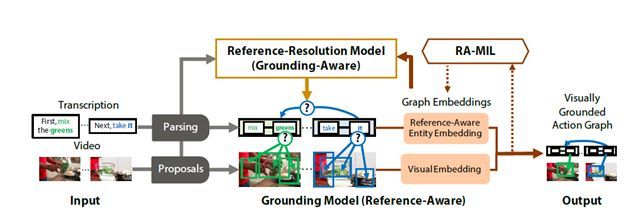
2.3 Finding "It": Weakly-Supervised Reference-Aware Visual Grounding in Instructional Videos
本文由斯坦福大学完成,是 CVPR 2018 的 oral 文章。将文本短语对应视觉内容是一项具有挑战性的任务。当我们考虑教学视频中的 grounding 问题,这个问题变得更加的复杂。教学视频的潜在时间结构违背了独立性假设,并且需要上下文理解来解决模糊的视觉语言指代信息。此外,密集的注释和视频数据规模意味着基于监督的方法的成本过高。在这项工作中,作者通过弱监督框架在教学视频中进行参照感知式 grouding 任务。其中只有文本描述和视频片段之间的对应关系可用于监督信号。文中介绍了视觉上 grounding 的动作图,这是一种捕获视频 grounding 和参照之间潜在依赖关系的结构化表示。文中提出了一种新的参照感知式多实例学习(RA-MIL)目标,用于对视频中的grounding进行弱监督。在 YouCookII 和 RoboWatch 的视频集合上评估了提出的方法,实验证明提出的方法能提升针对教学视频中的 grounding 问题。
2.4 Actor and Action Video Segmentation From a Sentence
本文由荷兰阿姆斯特丹大学完成,是 CVPR 2018 的 oral 文章。本文针对人物及其在视频内容中的动作进行像素级分割。 与现有的工作不同,本文的方法从自然语言输入句子中推断出相应的分词。因此,这种方法可以区分同一超类别中的细粒度人物信息,标识人物和动作实例,以及分割词汇表之外的人物与工作的片段对。 本文使用针对视频进行优化的编码器-解码器架构提出了像素级人物和动作分割的全卷积模型。为了展示来自句子的人物和动作视频分割的潜力,本文扩展了两个拥有 7500 多种自然语言描述的人物和动作数据集。 实验进一步展示了句子引导分割的质量,提出的模型的泛化能力,以及与传统人物和动作分割相比的先进的优势。
2.5 Compressed Video Action Recognition
本文由德克萨斯大学奥斯汀分校、卡耐基梅隆大学、南加利福尼亚大学、亚马逊的 A9 和亚马逊合作完成,是 CVPR 2018 的 oral 文章。训练鲁棒的深度视频表示比学习深度图像表示更具挑战性。这部分是由于原始视频流的巨大数据量和高时间冗余; 真正有用的信号经常被淹没在太多不相关的数据中。 由于视频压缩(使用 H.264、HEVC 等),多余的信息可以减少多达两个数量级,因此本文提出直接在压缩视频上训练深层网络。 这种表示具有更高的信息密度,实验证明训练也会更加容易。另外,压缩视频中的信号提供直接的但包含很大噪声的运动信息。 本文提出新的技术来有效地使用它们。 提出的方法比 Res3D 快 4.6 倍,比 ResNet-152 快 2.7 倍。 在动作识别的任务上,本文的方法优于 UCF-101、HMDB-51 和 Charades 数据集上对应的其它方法。

2.6 What Makes a Video a Video: Analyzing Temporal Information in Video Understanding Models and Datasets
本文由斯坦福大学、Facebook、达特茅斯学院合作完成,是 CVPR 2018 的 spotlight 文章。捕捉时间信息的能力对视频理解模型的发展至关重要。尽管在视频中对运动建模进行了大量尝试,但仍缺少时间信息对视频理解效果的明确分析。本文旨在弥合这一差距,并提出以下问题:视频中的动作对于识别动作有多重要?为此,本文提出了两种新颖的框架:(i)类别不可知的时序产生器和(ii)运动不变帧选择器,以减少/消除运动信息进行分析而不引入其他人为因素。这将视频的运动信息与其他方面的运动隔离开来。与我们的分析中的基线相比,所提出的框架对运动的影响提供了更加精确的估计(UCF101 的 25% 到 6%,Kinetics 的 15% 到 5%)。本文的分析提供了有关 C3D 等现有模型的重要见解,以及如何使用更稀疏视频帧实现一致性的结果。

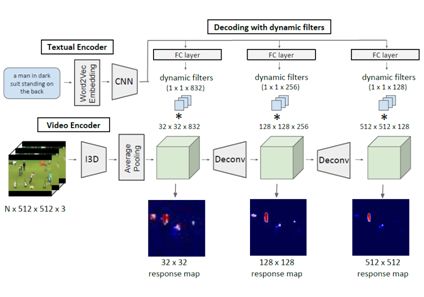
2.7 Fine-Grained Video Captioning for Sports Narrative
本文由上海交通大学完成,是 CVPR 2018 的 spotlight 文章。对于视频,如何生成细致的视频描述还远未解决,例如自动体育解说。为此,这项工作做出以下贡献。首先,为了促进对细粒度视频标题的新颖研究,本文收集了一个称为细粒度体育解说数据集(FSN)的新数据集,其中包含来自 YouTube.com 的含有真实性解说的 2K 体育视频。其次,本文开发了一个名为细粒度描述评估(FCE)的新型的评估指标来评估这项新任务。作为被广泛使用的 METEOR 的扩展,它不仅测量语言表现,而且测量动作细节及其时间顺序是否被正确描述。第三,本文提出了一个新的精细体育解说任务的模型框架。该网络具有三个分支:1)时空实体定位和角色发现子网络;2)局部骨骼运动描述的细粒度动作建模子网络;3)群组关系建模子网络以模拟运动员之间的交互。本文进一步融合这些特征,并通过分层递归结构将它们解码为长篇解说。 FSN 数据集上的大量实验证明了所提出的细粒度视频字幕框架的有效性。
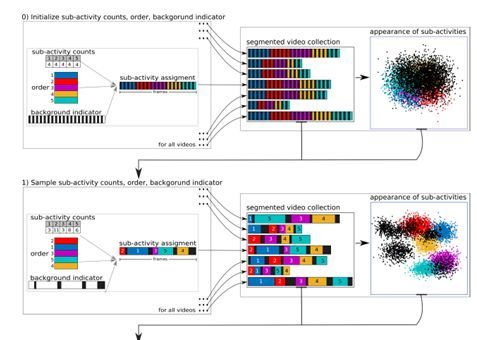
2.8 Unsupervised Learning and Segmentation of Complex Activities from Video
本文由德国波恩大学完成,是 CVPR 2018 的 spotlight 文章。本文提出了一种无监督地将视频复杂活动分成多个步骤或子活动的新方法,没有任何文本输入。 本文提出了一种迭代判别生成方法。该方法交替学习从视频的视觉特征学习子活动的外观,以及通过广义 Mallows 模型学习子活动的时间结构信息。另外,本文引入了背景模型来标注与实际活动无关的视频帧。 本文的方法在具有挑战性的Breakfast Actions和Inria Instructional Videos数据集上得到验证,并且超过了已有的无监督和弱监督模型。
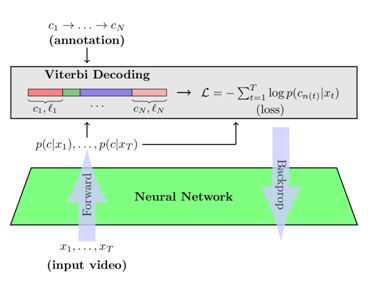
2.9 NeuralNetwork-Viterbi: A Framework for Weakly Supervised Video Learning
本文由德国波恩大学完成,是 CVPR 2018 的 spotlight 文章。视频学习是计算机视觉领域的一项重要任务,近年来越来越受到关注。 由于即使少量视频也容易包含数百万帧,因此不依赖帧级标注的方法特别重要。 在这项工作中,作者提出了一种基于 Viterbi 损失的新型学习算法,允许在线和增量学习弱标注视频数据。 此外显式的上下文和长度建模可以帮助视频分割和标签任务方面取得巨大提升。在几个行为分割基准数据集上,与当前最先进的方法相比,作者的方法获得了高达 10% 的提高。
2.10 Actor and Observer: Joint Modeling of First and Third-Person Videos
本文由卡耐基梅隆大学、Inria 和艾伦人工智能研究所合作完成,是 CVPR 2018 的 spotlight 文章。认知神经科学中的几种理论认为,当人们与世界互动或者模拟互动时,他们从第一人称的自我中心角度出发,并且在第三人(观察者)和第一人称(演员)之间无缝地传递知识。尽管如此,由于缺乏数据,学习这样的模型来识别人类行为并不可行。在本文中,作者创建了一个新的数据集 Charades-Ego。它是一个配对的第一人称视频和第三人视频的大型数据集,涉及 112 人,拥有 4000 对配对视频。这使得学习演员和观察者两者之间的联系。因此,本文解决了自我中心视觉研究的最大瓶颈之一,它提供了从第一人称到第三人称数据的联系。本文利用这些数据来学习了弱监督条件下的第一人称视频和第三人视频的联合表示,并表明了其将知识从第三人转移到第一人称领域的有效性。

2.11 Now You Shake Me: Towards Automatic 4D Cinema
本文由多伦多大学和 Vector Institute 合作完成,是 CVPR 2018 的 spotlight 文章。本文通过自动解析电影中的某些特殊效果来使 4D 影院自动化,这些效果包括溅起的水、光和震动。作者构建了一个新的数据集,称作 Movie4D,这个数据集标注了 63 个电影中的 9000 个特效。为了检测和分类特效,作者提出了建立在神经网络之上的 CRF 模型。这个模型利用了电影中的视频、音频、人的轨迹以及特效和角色、电影之间相关性。本文方便了 4D 电影进入家庭。

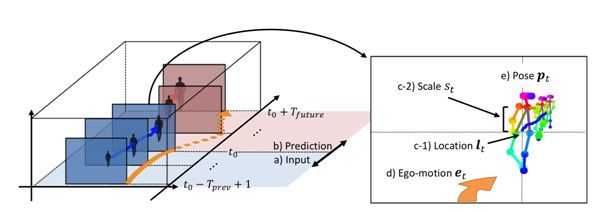
2.12 Future Person Localization in First-Person Videos
本文由东京大学与 IIT 合作完成,是 CVPR 2018 的 spotlight 文章。在本文中,作者提出了一项新任务,预测未来在第一人称视频中观看的人的位置。考虑由可佩戴相机连续记录的第一人视频流。给定一个从整个视频流中提取的人的短片,我们的目标是在未来的帧中预测该人的位置。为了促进未来人的定位能力,作者做出以下三个关键观察:a)第一人称视频通常涉及显着的自我运动,这极大地影响了未来帧中目标人的位置; b)目标人的大小作为一个突出提示,可以用于估计第一人称视频中的透视效果; c)第一人称视频经常捕捉人物靠近,使得更容易利用目标姿势(例如,当前位置)来预测他们未来的位置。作者将这三种观察结合到具有多流卷积–反卷积结构的预测框架中。实验结果表明作者提出的方法在新数据集以及公开的社交互动数据集上是有效的。
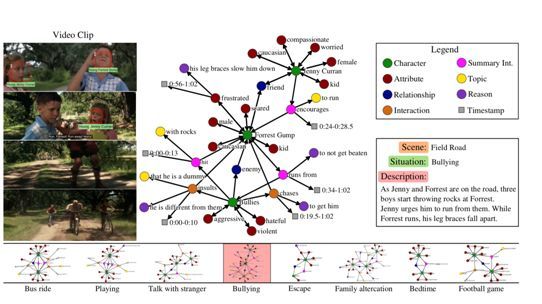
2.13 MovieGraphs: Towards Understanding Human-Centric Situations From Videos
本文由多伦多大学、Vector Institute 和 Montreal Institute of Learning Algorithms 合作完成,是 CVPR 2018 的 spotlight 文章。通过人工智能构建社会智能机器人要求机器有能力“阅读”人们的情绪、动机和其它影响行为的因素。为了实现这一目标,作者引入了一个名为 MovieGraphs 的新数据集,它提供了详细的基于图的电影剪辑描述的社交情景注释。每张图包含几种类型的节点,可以捕捉剪辑中出现的人、他们的情绪和身体属性、他们的关系(即父母/子女)以及他们之间的交互。大多数互动与提供额外细节的主题以及为动作提供动机的原因相关。另外,大多数互动和许多属性都基于视频。作者对新数据集进行了仔细的分析,显示了场景的不同方面之间的相关性方面以及跨越时间的相关性。作者提出了一种用图来查询视频和文本的方法,并且显示:1)图包含丰富和充足的信息来总结和定位每个场景; 2)子图可以描述抽象层次的情境并检索多个语义相关的情况。作者还通过排序和推理理解提出了交互理解的方法。 MovieGraphs 是第一个关注以人为中心的推断属性的基准数据集,为社交智能 AI 打开了一扇新的大门。
2.14 Action Sets: Weakly Supervised Action Segmentation Without Ordering Constraints
本文由德国波恩大学完成,是 CVPR 2018 的 spotlight 文章。视频中的动作检测和时序分割是研究人员越来越感兴趣的话题。虽然完全有监督系统近来倍受关注,但对视频内的每个操作进行全面标注对于大量视频数据来说代价昂贵且不切合实际。因此,弱监督行为检测和时序分割方法是非常重要的。尽管大多数人在这方面的工作都是假设给定的是有序的行为序列,但作者的方法只使用行为的集合。这样的行为集提供的监督信息少得多,因为行为顺序和行为次数都是未知的。但是它们可以很容易地从元标签中获得,而有序序列仍然需要人工标注。作者引入了一个自动学习的系统,可以在视频中学习时序分段和标注动作,其中唯一使用的监督信息是动作集。在三个数据集上的评估表明,尽管使用的监督信息明显少于其他相关方法,但作者的方法仍然取得了良好的结果。

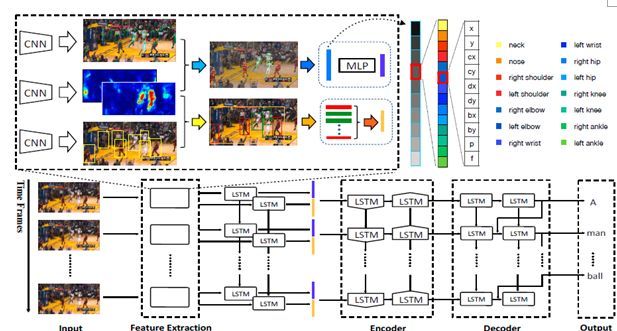
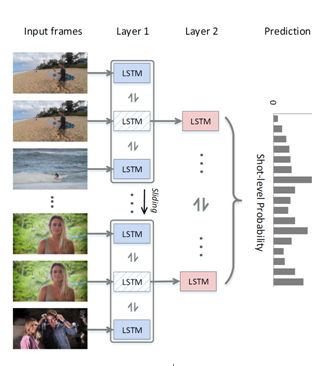
2.15 HAS-RNN: Hierarchical Structure-Adaptive RNN for Video Summarization
本文由西北工业大学和中国科学院西安光学精密机械研究所联合完成,是 CVPR 2018 的 spotlight 文章。其主要出发点在于,视频是由多个镜头(slot)按照序列组成的。在以往的视频缩略任务中,往往需要先进行镜头的预切割。人工进行镜头预分割十分耗时,但自动分割往往效果不佳。这样就限制了视频缩略方法的直接运用。为解决这一难题,该工作提出将镜头分割和视频缩略融入到一个模型中。如下图所示,该工作提出了一个两层双向 LSTM 模型,第一层负责镜头边缘的检测(也即镜头分割),然后将分割后的镜头输入到第二层模型,进行视频的缩略。该工作实现了从视频到缩略的一站式解决方案,省去了预处理过程,具有很高的现实价值。
2.16 Viewpoint-aware Video Summarization
本文由东京大学、RIKEN 研究所、苏黎世联邦理工学院和荷语天主教鲁汶大学联合完成,是 CVPR 2018 的 spotlight 文章。该工作提出同一段视频可以有多种不同的缩略结果,取决于用户的需求或者关注点。作者将这种关注点称为视角(viewpoint)。如下图所示,作者展示了两种视角,视频拍摄的地点和视频拍摄的事件。两种视角下产生的缩略显然不同。为了定义视角,作者提出了视频组缩略,而不是对单个视频进行独立的缩略。同组中的视频具有同样的视角,而不同组视频的视角则有所不同,但是具有一定的相关性。该工作借鉴 Fisher 判别准则,提出以下缩略准则:单视频的缩略要与该视频内容相关,同组视频的缩略要相近(体现出相同的视角),不同组视频的缩略要不同(体现出不同的视角)。为了展现视角在视频缩略中的合理性,该工作还给出了一个新的数据集。该工作的主要意义在于,拓展了视频缩略的涵义,从单个视频拓展到视频组的缩略,从单一的缩略拓展到不同视角的缩略。

第三部分:三维视觉
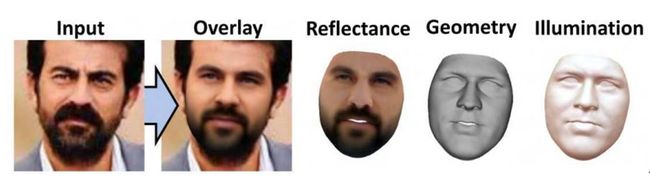
3.1 Self-Supervised Multi-level Face Model Learning for Monocular Reconstruction at Over 250 Hz
本文由马克斯-普朗克研究所和斯坦福大学等机构合作完成,是 CVPR 2018 的 oral 文章。为了提升单张图片重建 3D 脸部模型的效果,该论文采用了多层次的脸部结构重建方法,作者把传统的基于参数化 3D 可变形模型(3DMM)作为基础模型,在此之上引入纠正模型来增加模型的表达能力。实验表明纠正模型使得 3D 脸部重建效果更接近原图,而且能重建出更多细节。
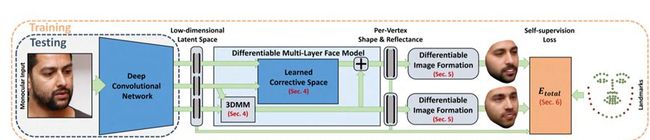
基础模型与纠正模型均为线性模型,其中基础模型的基向量通过对训练样本做 PCA 得到(即 3DMM 模型),而纠正模型的基向量由神经网络直接学习得到。脸部的形状与纹理通过基础模型加上纠正模型来拟合。算法使用编码器来学习基础模型和纠正模型的组合参数。随后整合两个模型的结果,通过解码器得到渲染的 3D 脸部模型。然后,算法把 3D 模型成像,对比成像结果与输入图片的差异,目标是使差异变小,因此该方法是自监督的方式进行训练。此外,算法还限制了成像结果与输入图的脸部特征点要对齐。注意该方法中只有编码器是可学习的,而解码器和渲染器都是手工设计的可导层,不是可学习的。为了让模型更加鲁棒和训练过程更加稳定,作者在损失函数上加入额外调节项,用于提升纠正模型的平滑性、纹理的稀疏性和整体一致性。
3.2 Extreme 3D Face Reconstruction: Seeing Through Occlusions
本文由美国南加州大学和以色列公开大学合作完成,是 CVPR 2018 的 spotlight 文章。现有的基于单视角图像的 3D 人脸重建算法大多以接近正脸且没有遮挡的图片为输入。本论文提出了一种基于凹凸映射(bump mapping)的新算法,可用于解决被遮挡图像的 3D 人脸重建问题。该算法把脸部的重建分成两部分,一部分是基于 3DMM 的人脸基础形状和表情的重建,另一部分是局部细节纹理的重建。算法首先利用 BFM 的线性模型对全局形状和表情进行重建,对视角的估计采用了作者之前的工作 FasePoseNet。对于脸部细节的描述,作者使用了 CNN 来学习图片到凹凸图的转换,训练数据采用传统的 Shape from Shading 的方法计算得到。为了复现被遮挡住的细节,作者把非脸部区域看作丢失的信息并采用图像修复算法来填补。而成像角度而形成的自遮挡问题则通过软对称的机制完成。经过上述一系列步骤之后,算法可以获得细节逼真的结果且可以处理遮挡情况下的重建。
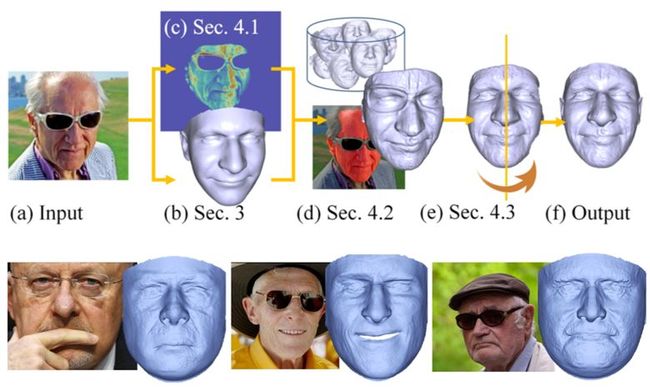
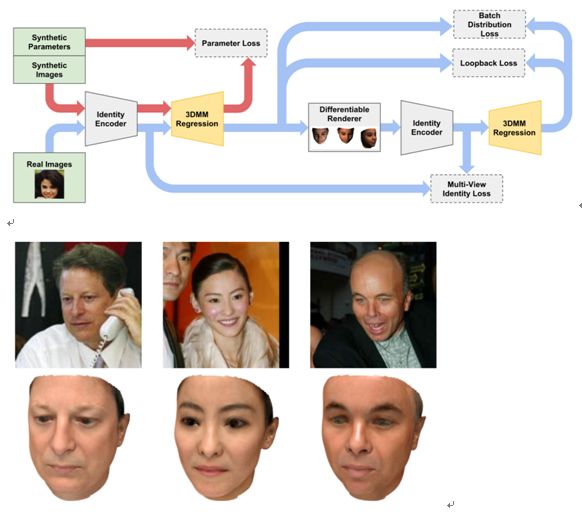
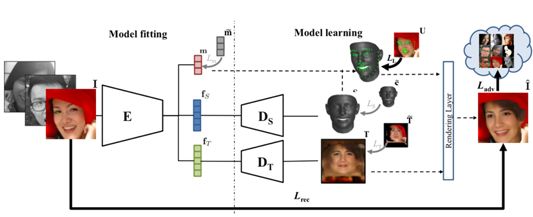
3.3 Unsupervised Training for 3D Morphable Model Regression
本文由普林斯顿大学、谷歌和麻省理工学院合作完成,是 CVPR 2018 的 spotlight 文章。使用无监督训练的方法基于 3DMM 进行人脸三维重建。论文基于编码器和解码器模型,创新性地将人脸识别网络引入训练的损失函数,使得生成的 3D 人脸能很好地保留了输入图片的人脸个体特征。该模型旨在拟合形状和纹理,并没有学习姿态表情和光照。算法的编码器接受图像作为输入,输出用于 3DMM 模型的参数。解码器接受参数后合成 3D 人脸。为了使网络不仅能保持个体信息,还能生成自然真实的人脸,作者提出了 3 个新的损失函数,即批分布损失(batch distribution loss)、回环损失(loopback loss)和多视角身份损失(multi-view identity loss)。批分布损失可使每个批的统计量与 3DMM 的统计量一致。回环损失可保证生成的 3D 人脸模型的2D成像图片重新进入编码器得到的参数和原图的参数尽量一致。多视角身份损失能使得模型学习到独立于观察角度的个体特征。实验结果说明,模型不仅仅可以生成与输入图像高度相似的 3D 人脸,而且生成的人脸独立于输入的表情和姿态,甚至被遮挡的人脸也可以达到不错的生成效果。
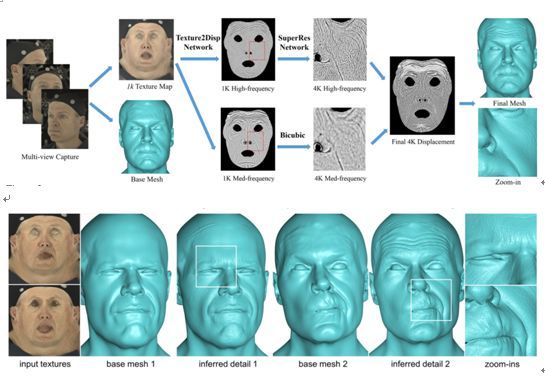
3.4 Mesoscopic Facial Geometry Inference Using Deep Neural Networks
本文由南加州大学、谷歌和 Pinscreen 联合完成,是 CVPR 2018 的 spotlight 文章。本文提出了一个由散射人脸纹理图(diffusely-lit facial texture maps)合成 3D 人脸的算法。该算法结合了图像到图像的转换网络和超分辨率网络。其中图像到图像的转换网络分成两个子网络,分别学习高频和中频信息,使得模型可以捕捉更多细节。基于一系列不同角度拍摄的图像,算法首先计算出基础 mesh 和 1k 分辨率的纹理图。随后通过条件对抗生成网络把输入的纹理图转换成高频和中频两种位移图。高频的位移图通过超分辨率网络提升到 4k 分辨率,而中频的位移图通过升采样提升到 4k 分辨率。这两种频率的位移图整合结束后,把信息重新加到 mesh 上,得到最后的输出。
3.5 Modeling Facial Geometry Using Compositional VAEs
本文由瑞士洛桑联邦理工学院与 Facebook 联合完成,是 CVPR 2018 的 spotlight 文章。对人脸建模而言,保证鲁棒性是一个难点,抓住表情是另一个难点。为了解决这两个难点,该论文提出了基于多层次变分自编码器(compositional VAE)的深度神经网络模型。这个算法只需要少量样本就可以训练出一个可以推广到新个体和任意表情的模型。
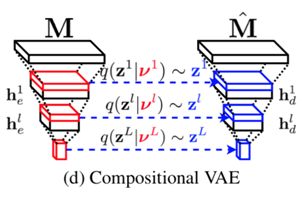
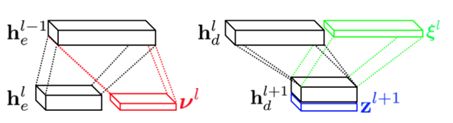
现存的人脸建模算法大部分基于线性模型,而线性的假设限制了模型的表达能力。为了增加模型的表达能力,该算法使用神经网络对人脸进行非线性建模。它充分利用卷积神经网络对人脸进行整体和局部的多层次建模,其中高层网络抓住整体和低频信息,底层网络抓住局部和高频信息。模型采用了编码器和解码器结合的结构,并将 VAE 的思想融入 U-net 的跳转连接,使模型更具有鲁棒性。编码器的每层输出分成两部分,一部分作为下一层的输入,另一部分为该层隐变量后验分布的参数。解码器的每层输入包括了上一层的输出,以及由该层先验分布抽样得到的隐变量;它的输出包括了下一层的输入和下一册隐变量的先验分布参数。此外,为了更好地使用这个框架,论文提出了一种新的 mesh 表示方法,使二维图片上的近邻像素和三维拓扑的近邻保持一致。作者表示这个框架可以应用于很多具体任务,包括3D mesh 的对应、2D 的标志性特征拟合、深度图的重建等等。下图为算法对带噪声的深度图进行重建的结果,而训练数据只包括 16 个人。

3.6 Nonlinear 3D Face Morphable Model
本文由密西根州立大学完成,是 CVPR 2018 的 spotlight 文章。现有的基于 3DMM 的人脸重建方法大多是线性模型,线性模型的基向量通过对训练数据做 PCA 得到。由于计算基向量的样本量少,且线性模型的表达能力有限,所以生成效果提升会遇到瓶颈。本文提出了一个非线性人脸可变形模型,不需要采用事先已知的 3D Mesh 基向量,而是通过神经网络来将 3DMM 参数解码出 3D Mesh。
该工作基于编码器-解码器模型。其中编码器通过输入图片学习投影参数以及形状和纹理参数。解码器通过形状和纹理参数直接学习 3D 的形状和纹理,因此可以看做是一种 3D 人脸的非线性可变形模型。随后,基于 z-buffer 算法,渲染层使用投影参数以及 3D 形状和纹理把 3D 模型渲染成一张 2D 图片。模型的目标是最小化 3D 人脸的 2D 投影与输入图片的像素级差异。为了让生成的人脸更加真实,作者引入了 patchGAN 来学习高质量的纹理和局部特征,还利用与特征标志对齐相关的损失函数来调节编码器。实验结果表示,解码器作为一种非线性变形模型有更强大的表示能力,可以重建出更多的人脸细节。

3.7 Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies
本文由卡内基梅隆大学和 Facebook 联合完成,获得了 CVPR 2018 的最佳学生论文奖(Best Student Paper Award)。本文提出了一个统一的变形模型,可在无标志物(Marker)的情况下捕获多个尺度的人体运动,包括大尺度的躯体动作以及微妙的脸部和手部动作。在没有标志物的情况下,此前还没有系统可以同时捕获躯体、面部、手部的运动,主要挑战在于人体不同部分的尺度差距较大,比如在一张含有多个人的图像中,面部和手指所占的分辨率通常很小,造成难以捕获其运动。为了解决此问题,作者提出了一种统一的变形模型,可以表达人体每个主要部分的运动情况。具体而言,通过将人体各个部分模型缝合到一个骨架层次结构中,形成初始的 Frank 模型,此单一模型可以完整地表达人体各个部位的运动,包括面部和手部。通过使用多摄像头的捕捉系统大规模采集穿着日常服装的人,进一步优化初始模型得到 Adam 模型。Adam 是一个经过校准的参数化模型,与初始模型享有相同的骨架层次结构,同样包括躯体、面部、手部的模型,另外还可以表达头发和服装的几何形状。Adam 模型可以像其它 3D 可变形模型(例如 SMPL 人体模型、BFM 人脸模型等)一样用于基于单摄像头的整个人体的参数化 3D 重建。
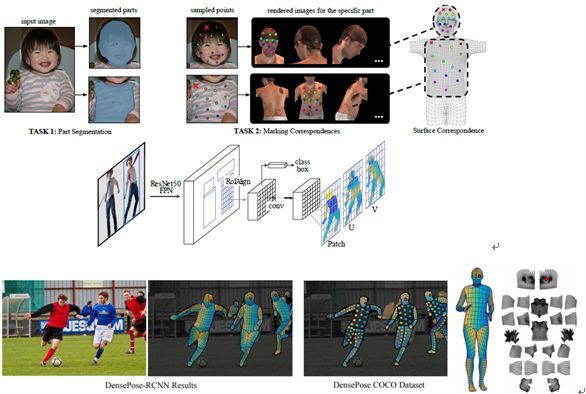
3.8 DensePose: Dense Human Pose Estimation in the Wild
本文由法国国家信息与自动化研究所(INRIA)和Facebook AI 研究中心(FAIR)合作完成,是 CVPR 2018 的 oral 文章。本文提出了一个新的任务,提出密集人体姿态估计 ,并发布了一个人工标注的由 RGB 图像到 3D 模型密集对应的数据集 DensePose-COCO。传统的人体姿态估计主要基于少量的人体关节点,比如手腕等。本文通过将人体表面切分成多个部分,然后在每个部分标注区域关键点的方法,将人体表面关键点扩展到 100-150 个。基于该数据集,本文尝试了基于全卷积网络和基于 Mask-RCNN 的方法,发现基于 Mask-RCNN 的方法表现最优。该方法是在 Mask-RCNN 的基础上,在最后连接一个分类器和回归函数。分类器用于将每一个点分类到属于人体哪个部位,回归函数输出每一个点在各部位表面的 UV 坐标。本文展示的实验结果表明,提出的基于 Mask-RCNN 的方法可以成功学习到由 RGB 图像到 3D 模型的密集对应。
3.9 DoubleFusion: Real-Time Capture of Human Performances with Inner Body Shapes From a Single Depth Sensor
本文由清华大学、北京航空航天大学等机构合作完成,是 CVPR 2018 的 oral 文章。本文研究的问题是单个深度摄像头实时三维人体重建。此前最新的工作 BodyFusion 已经证明利用人体的骨架可以更好地重建三维人体模型。但是,BodyFusion 在跟踪环节只利用了体表信息,并且骨架信息在初始化后是固定的。一旦骨架信息的初始化没有做好,BodyFusion 的效果就会受很大影响。本文提出了一种动态利用骨架信息来约束三维人体模型重建的方法。将传统的 DynamicFusion 的方法作为外部层(outer surface layer),利用 SMPL 来建模内部骨架层(inner body layer),内部层也是通过融合的方法来不断迭代更新,因此该方法称作 DoubleFusion。本文还提出一种利用现有的信息来更新初始化 SMPL 参数的优化方法。实验结果表明:1)本文提出的内部骨架层可以有效改善快速移动下的三维人体模型重建;2)更新初始化 SMPL 参数的优化方法可以有效提高三维重建的精度
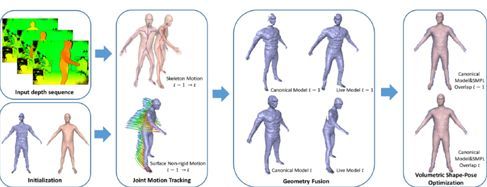
3.10 Video Based Reconstruction of 3D People Models
本文由马克斯-普朗克研究所和德国布伦瑞克工业大学合作完成,是 CVPR 2018 的 spotlight 文章。给定单个含有一个运动人体(此人从各个角度可见)的单目视频,本文提出的方法首次实现了从中获得精确的三维人体模型,包括头发、衣服及表面纹理。标准的视觉外形方法(visual hull methods)从多个视图捕获静态形状,但是视频中的人体姿态是变化的,本文的核心是将视觉外形方法推广到含有运动人体的单目视频中,即将视频中动态的身体姿势转化为规范的参照系。作者通过对动态人体轮廓对应的轮廓锥进行变换以“消除”人体动态姿势,从而获得公共参照系中的视觉外形,这使得能够有效使用大量帧估计一个共同的人体三维形状。为了对衣服和其他细节进行建模,本文在估计 SMPL 模型参数的基础上增加一项三维位移的优化参数。在多个三维数据集上的实验结果表明,此方法可以达到 4.5mm 的三维人体重建精度。
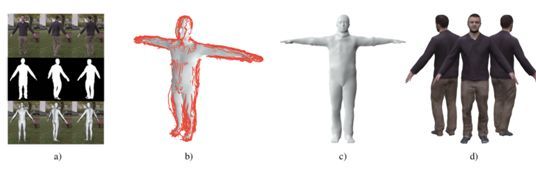
3.11 End-to-End Recovery of Human Shape and Pose
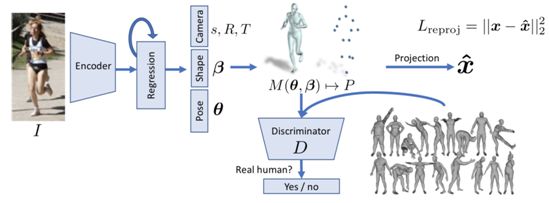
本文由加州大学伯克利分校、马克斯-普朗克研究所和马里兰大学合作完成,提出了一种根据单张彩色图像端到端恢复人体三维模型的方法。目前大多数方法使用多步骤的方式估计三维人体姿态,首先估计二维关节点位置,然后基于此估计三维关节或者三维模型参数。本文提出的框架如下图所示,不依赖中间二维关键点检测,直接从单张图片编码特征并回归三维模型参数,借助 SMPL 模型输出人体三维网格。本文根据关键点投影构造损失函数,使得三维关键点投影后与真实二维关键点距离尽可能小。由于同一个二维投影面可以由多个三维模型经过投影得到,为了解决这种不确定性,作者还使用了一个判别器联合监督训练,判断生成的参数是否是真实的人体。通过引入这种条件 GAN 的方式,使得可以在没有任何成对的二维和三维数据的情况下进行训练,为从大规模二维数据学习三维信息提供了可能。此方法在估计三维关节精度方面超过了以前方法,并且在给定图片中人体边框的情况下可以实时运行。
3.12 Learning to Estimate 3D Human Pose and Shape from a Single Color Image
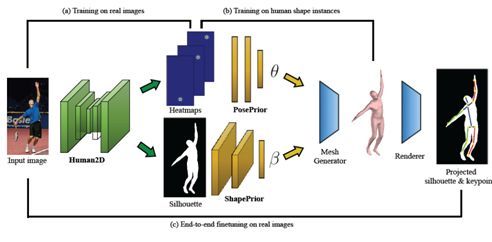
本文由宾夕法尼亚大学、北京大学和浙江大学共同合作完成。本文同样提出了一种基于 SMPL 模型的端到端神经网络模型,可从单张彩色图像恢复人体三维模型。该模型首先由 RGB 图片得到 2D 关键点和轮廓,然后利用 2D 关键点和轮廓信息来分别估计 SMPL 中的 3D 姿态(pose)参数和形态(shape)参数。不同于上述前一篇文章(End-to-End Recovery of Human Shape and Pose)中由图像来直接估计 SMPL 中的参数,本文是通过 2D 关键点和轮廓来估计。对于 2D 关键点和轮廓,已有大量公开的数据集和成熟的模型;对于 SMPL 参数的估计,可以通过公开的运动捕捉数据和人体扫描数据来获取三维模型数据,并且映射到 2D 图像来获取 2D 关键点和轮廓。实验结果表明该方法在三个公开数据集上取得很好的结果。根据论文中在 Human3.6M 数据集上的性能,之前的方法SMPLify的重建误差是 82.3,本文的结果是 75.9,而前一篇文章能达到 56.8(注意重建误差的数字是越小越好)。
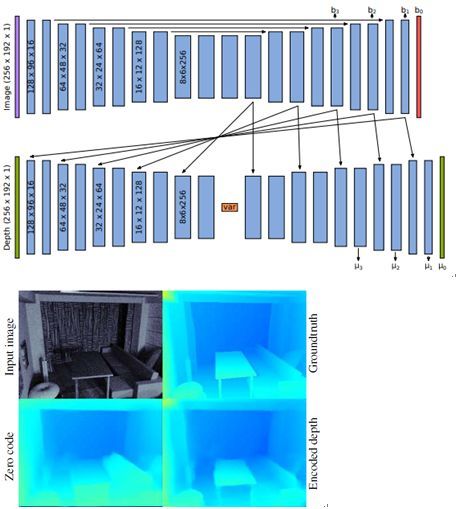
3.13 CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM
本文由帝国理工学院 Andrew Davison 组完成,是CVPR 2018 荣誉提名奖(Honorable Mention Award)论文,主要关注场景几何信息的紧凑表示方法。场景几何信息的表示方式一直是三维视觉实时系统至关重要的研究问题。传统的密集地图的表示方式虽然可以描述完整的场景几何信息并加上语义标志,但其缺点是密集地图计算复杂高和存储代价大,不利于进行严格的概率推理。相反,稀疏地图的表示方式没有这样的问题,但其仅仅描述了稀疏的场景几何信息,这些信息一般主要用于相机的定位。为了获得密集地图的优点和稀疏地图的优点,本文提出了一种新的紧凑的密集地图表示方法。作者从图像中学习深度图和自编解码器这些方法中获得启发,提出了一种场景几何信息的紧凑表示方法,这种方法可以通过将紧凑编码与原始图像一起送进一个 CNN 解码器中得到场景的密集深度图。在基于关键帧的 SLAM 系统中,可以通过一起优化该编码和相机的位姿来恢复场景的几何信息和相机的运动信息。作者在文章中解释了如何学习得到这个编码,以及这个编码在单目 SLAM 系统中的优点。
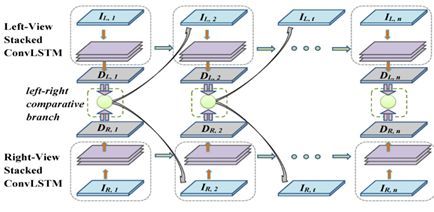
3.14 Left-Right Comparative Recurrent Model for Stereo Matching
本文由腾讯 AI Lab 和新加坡国立大学等机构合作完成,是 CVPR 2018 的 oral 文章。在立体视觉匹配问题中,充分利用左右双目的视差信息对于视差估计问题非常关键。左右一致性检测是通过参考对侧信息来提高视差估计质量的有效方法。然而,传统的左右一致性检测是孤立的后处理过程,而且重度依赖人工设计。作者提出了一种全新的左右双目对比的递归神经网络模型,同时实现左右一致性检测和视差估计。在每个递归步上,模型同时为双目预测视差结果,然后进行在线左右双目对比并识别出很可能预测错误的左右不匹配区域。作者提出了一种“软注意力机制”更好地利用学习到的误差图来指导模型在下一步预测中有针对性地修正更新低置信度的区域。通过这种左右对比的递归模型,生成的视差图质量能够不断提高。在 KITTI 2015、Scene Flow 和 Middlebury 标准库上的实验验证了本方法的有效性,并显示本方法能取得很高的立体匹配视差估计性能。
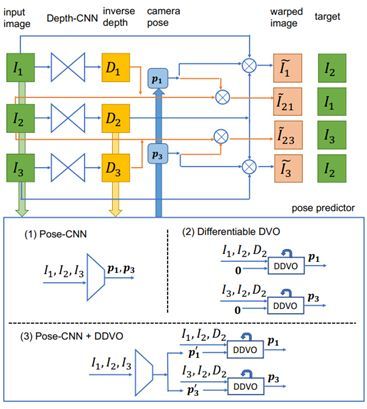
3.15 Learning Depth from Monocular Videos Using Direct Methods
本文主要由卡内基·梅隆大学完成,提出了一种利用直接法进行无监督训练的单目图像预测深度图方法。作者受到了最近的直接法视觉里程计(DVO)的启发,认为深度图 CNN 可以在没有相机姿态 CNN 的情况下学习得到。具体来讲,由于深度估计和相机姿态估计是紧密联系在一起的问题,本文提出利用 CNN 预测深度图和利用一种可求导的 DVO 计算相机姿态的方法来计算训练损失,从而达到无监督式训练。借助一种有效的深度归一化策略,本文的方法可以使得在单目数据训练中的性能有很大的提升。
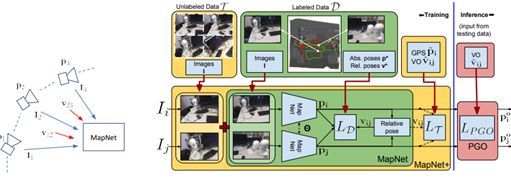
3.16 Geometry-Aware Learning of Maps for Camera Localization
本文由美国佐治亚理工学院和英伟达合作完成,是 CVPR 2018 的 spotlight 文章。该论文提出了一种叫 MapNet 的方法来进行单目 SLAM 的相机 6DOF 定位。 MapNet 跟之前的工作 PoseNet 类似,也是通过卷积神经网络直接预测相机的 6DOF 位姿,不同之处是在训练的时候,除了像 PoseNet 一样用相机位姿的基本真值计算损失之外,引入了两帧图像之间的相对位姿计算损失。在此基础上的 MapNet+ 方法可以利用无基本真值的数据进行训练,方法是利用已有的视觉里程计例如 SVO 和 DSO 方法计算得到相对位姿作为训练的基本真值位姿来计算损失。同时,IMU 或 GPS 等数据也可以作为额外的数据来加入训练。另外,本文还提出使用 SLAM 常用的位姿图优化(PGO/Pose Graph Optimization)技术作为后处理来进一步提高位姿估计的精度。本文的另一个创新点是提出用对数域的单位四元数来做位姿中旋转的参数化,作者指出这种参数化方法更有利于深度学习。
3.17 Learning Less Is More - 6D Camera Localization via 3D Surface Regression
本文由德国海德堡大学完成,跟上面介绍的 MapNet 一样,也是研究从单张图像恢复相机 6DOF 位姿的问题。在目前主流的基于深度学习进行相机 6DOF 定位的方法中,一般都采用端到端地学习整个相机定位的过程或者用学习相机定位的大部分流程。这篇文章与其它方法不太一样,作者认为,其实只需要学习相机定位中的一个模块便足够做到精准的定位。基于作者之前的 CVPR 2017 的可导 RANSAC 方法,作者提出了一种用全连接神经网络来稠密拟合“场景坐标”的方法,建立输入彩色图像和三维场景空间的联系。“场景坐标”是指将图像中的局部块映射到三维空间中三维点,从而得到局部块的坐标。由于局部块具有相对比较稳定的外观,即对视角变化不太敏感,使得对齐图像和三维模型比较容易。作者提出的这种方法具有高效、精确、训练鲁棒、泛化能力强等优点,其在室内和室外的数据集上都一致地比当前领先的技术要好。最后值得一提的是,这种方法在训练的时候不需要利用一个已知的三维场景模型,因为训练的时候可以自动地从单目视觉约束中学习到这个三维场景的几何信息。从论文中描述的在 7Scenes 数据集上的性能来看,本篇论文的方法的精度比上面介绍的 MapNet 方法的精度要高出不少。
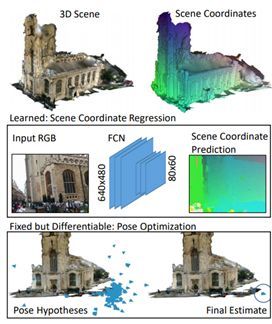
3.18 Semantic Visual Localization
本文由苏黎世联邦理工学院、MPI Tubingen 和微软合作完成,主要研究在大范围的视角变化下的相机定位问题。问题的设定是,假设系统中有一些已知图像及其深度图和相机位姿,给定一个未见过的查询图像,求出其相机的 6DOF 位姿。处理这个困难的问题不仅有挑战性,而且非常实用。例如,增强现实和自动驾驶的长期定位都需要面对这个问题。作者提出了一种新的基于三维几何和语义的定位方法,这种方法可以克服过去方法失败的情况。作者利用了一个新的生成模型来进行描述子学习。训练描述子时,用一个语义场景补全任务作为辅助训练任务。训练得到的三维描述子对观察不全的情况很鲁棒,因为训练的时候把高维的三维几何和语义信息编码进去了。作者在几个有挑战性的大型定位数据集上表明了其方法在超大视角变化、光照变化和几何变化的情况下的可靠定位性能。

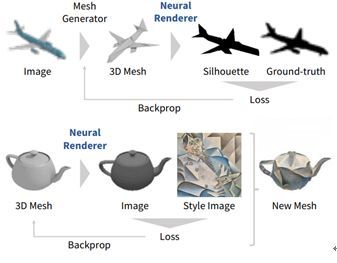
3.19 Neural 3D Mesh Renderer
本文由东京大学完成,是 CVPR 2018 的 spotlight 论文。该论文提出了一种将三维 Mesh 渲染成二维图像的近似可求导模块,可以用于神经网络的反向传递中。如果用传统方法直接将三维 Mesh 渲染成二维图像,会涉及一个光栅化的离散操作。这个操作是不能反向传播的,也就是说,不能用于常用的神经网络中。为了解决这个问题,这篇文章提出了一种近似的光栅化梯度,使其可用于神经网络的渲染模块。作者使用这个方法展示了由单幅图像带轮廓图像监督的三维 Mesh 重建,其性能优于目前的基于体素(Voxel)的方法。除此之外,作者在二维图像的监督下实现了基于梯度的三维网格编辑操作,例如二维到三维的风格转换,三维的 DeepDream 等。这些应用表明了作者提出的这个网络渲染器在神经网络的潜在应用和有效性。
3.20 Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene
本文由加州伯克利大学完成。文章旨在提供一种从单张 2D 图像,通过预测立体场景的三个要素来重建场景 3D 结构的方法。其中三个要素包括:场景布局(layout, 墙面和地板)、物体的形状(shape)以及姿态(pose)。文章首先提出基于三要素的场景 3D 结构表示方法,并展示了对比与两种主要场景三维表示方法(深度图像和体素)的优势。随后作者给出了基于深度学习的场景重建网络结构(如下图)。网络输入为 2D 场景图片和物体边框,输出为作者定义的三要素。
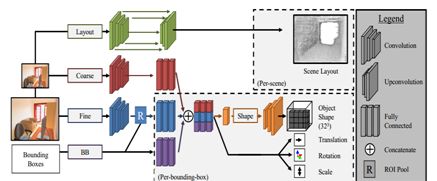
作者在合成数据集上进行了训练,并证实了模型在合成数据和真实数据上都具有良好的表现。部分真实图片的预测结果如下所示。本文方法的预测结果为场景 3D 结构理解提供了更好的解释性。

3.21 Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net
本文由 Uber 公司与多伦多大学合作完成,是 CVPR 2018 的 oral 文章。作者首先指出自动驾驶任务通常被分割成四个步骤: 物体检测、物体追踪、运动预测和路径规划。四个步骤通常独立学习。这样造成了后续步骤中的错误信息无法反馈给之前的步骤并且运行时间长。 在本文中, 作者提出了一种名为 FaF(Fast and Furious,速度与激情)的端到端全卷积网络方法。该方法利用 3D 传感器提供的时空数据,可同时完成 3D 检测,追踪和运动预测。该方法不仅能在作者采集的大数据上取得最优结果,还可以实时(30ms 内)完成所有任务。值得注意的是,在对单帧点云数据体素化之后,作者并未采用复杂的 3D 卷积操作,而是把高度量化后作为通道信息,在宽度和深度上使用 2D 卷积。这样既保证了网络的高效, 又可以让网络学习准确的高度信息。对于时间信息,作者提供了早期融合(early fusion)和延迟融合(later fusion)两种模型(如下图)。其中早期融合模型运行速度更快,延迟融合准确率更高。
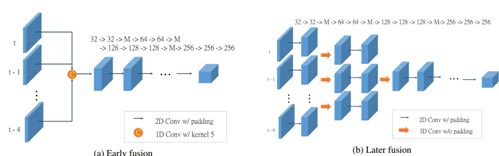
在作者采集激光雷达数据集上,该方法在三个任务上表现优异。作者通过消融研究证实了三个任务同时学习的必要性。
3.22 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
本文由 FAIR 与牛津大学联合完成,是 CVPR 2018 的 spotlight 文章。该论文提出的方法及其上一版本(A spatially-sparse convolutional neural network)已经在多个视觉任务比赛中名列前茅,如 2017 年 shapeNet 3D 物体语义分割比赛第一名和 2015 年 Kaggle 举办的糖尿病视网膜病变检测第一名等。 本文在利用三维稀疏结构的基础上强调卷积操作不应减少原有稀疏特性(图1)。为不改变 3D 数据稀疏特性(图2),作者提出了子流形稀疏卷积操作子(SSC,Submanifold Sparse Convolution operator)。具体来说,首先对输入的边缘进行 0 值扩增,以保持操作后输出与输入同尺寸。然后只在以输入样本的激活像素为中心点的区域(图 2,绿色像素)进行卷积操作。这样就保证了卷积操作不改变特征的稀疏结构。

图 1 左图为原始输入。中图为一次卷积操作后结果。右图为两次卷积后结果。常规卷积运算减少了特征的稀疏特性。特征发生“膨胀(dilation)”

图 2 SSC感受视野在不同位置示意图。绿色为激活像素,红色为忽略像素。输出激活区域的模式与输入保持不变。
在SSC的基础上,作者又定义了对应的激活函数,批归一化和池化函数用以高效的搭建不同的深度学习网络。实验表明,该方法计算高效且准确率高。
3.23 SPLATNet: Sparse Lattice Networks for Point Cloud Processing
本文由马塞诸塞州大学、加州大学美熹德分校和英伟达公司共同完成,获得本届 CVPR 最佳论文荣誉提名奖(Best Paper Honorable Mention Award)。自动驾驶和机器人应用中, 通常需要对激光雷达等 3D 传感器获得的不规则数据(如点云(point cloud)和表面(mesh)),进行处理和分析。点云数据的稀疏和无序特性给直接运用卷积神经网络带来了困难。为解决上述问题,本文通过引入双边卷积层(BCL/Bilateral Convolution layer), 构建了一种适用于点云数据的通用灵活的神经网络结构——稀疏晶格网络(SPLATNet, SParse LAttice Network)。该网络的核心是双边卷积层,由以下三个步骤完成:
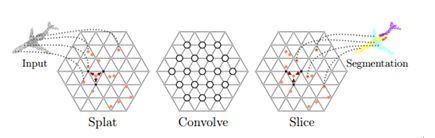
a)Splat
该步骤首先把特征从原空间(欧式空间)投影到Permutohedral Lattice 空间中。然后通过重心插值法(barycentric interpolation)将点特征整合到晶格顶点。这样就将不规则的点云信息表示在了规则的晶格顶点上。
b)Convolve
一旦将点云投影到规则的晶格上,卷积操作就和平坦空间卷积类似了。
c)Slice
该操作可视为 Splat 的反操作。它通过质心插值法,将特征映射回原空间。此时的输出点云可以和输入点云相同,也可以不相同。
在 BCL 的基础, 为解决语义分割问题,作者提供了 3D-3D 和 2D-3D 两种网络结构,如下图所示:
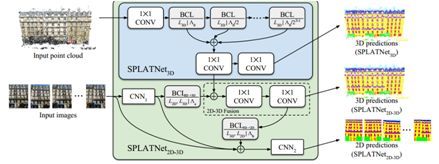
其实验结果如下:

3.24 Tangent Convolutions for Dense Prediction in 3D
本文由弗莱堡大学和英特尔实验室(Intel lab)共同完成,是 CVPR 2018 的 spotlight 文章。为在 3D 语义场景分析任务中使用深度卷积网络结构,作者提出一种新的卷积操作——切面卷积(Tangent Convolution)。作者首先提出了 3D 数据都是来源于局部欧式表面(locally Euclidean )采样的假设。 在此基础上,每个点的局部表面几何结构可以投影到该点周围的切平面上。 每个切面图像可以认为是支持平面卷积的二维规则图像。 所以对于 3D 数据,作者推导出如下切面卷积公式:
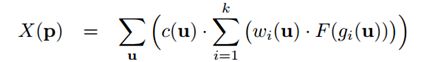
其中 P 为 3D 输入数据,u为该点在切平面的 K 近邻点,c 为卷积核,w 为 u 的插值函数,g 为近邻选择函数。 因为切平面图像只与输入几何结构有关,作者认为预计算切平面图像后,该方法可以适用于大规模点云数据。
在切面卷积基础上,作者搭建了如下全卷积 U 形网络 来进行 3D 场景理解。
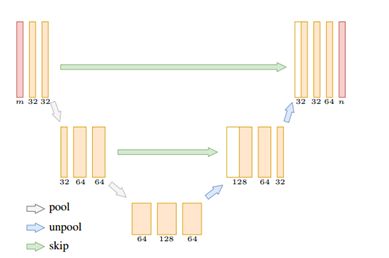
部分室内、室外对比实验结果如下所示:
3.25 3D-RCNN: Instance-Level 3D Object Reconstruction via Render-and-Compare
本文由佐治亚理工和卡耐基梅隆大学合作完成,是 CVPR 2018 的 oral 文章。该论文提出了一种用深度卷积网络从 2D 图像中重建 3D 物体实例的方法。文中,作者首先解决了 3D 形状(shape)和姿态(pose)如何表示的问题。 对于 3D 形状,作者通过对每一类物体的 CAD 模型进行 PCA 建模后,得到了该类物体的一组基向量。之后实例的 3D 形状就可以用一组参数表示为对应基向量的线性组合。对于姿态,作者认为物体为中心的表示方式(allocentric orientation)相比较于相机为中心的表示方式(egocentric oritation)更加适合学习,因为这种表示方式与物体为中心的 2D 图像感兴趣区域(RoI)的表示方式更加一致。在此基础上,作者给出了名为 3D-RCNN 的网络结构:
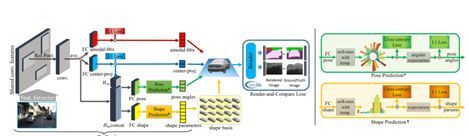
网络结构的解渲染部分(De-render)从 2D 图像中预测出上述 3D 表示。为利用更易获取的 2D 图像进行监督训练,作者设计了渲染与对比损失函数。 该部分将重建后的 3D 实例进行渲染得到对应 RoI 区域的分割掩膜和深度图像。在与真实结果对比后,利用有限差分法计算近似梯度进行训练。作者首先在合成数据集上进行了训练,然后在真实数据集上进行微调。该网络在真实图像上部分测试结果如下所示。

