kubernetes初认识
kubernetes基本概念
Kubenetes是Google开源的容器集群管理系统,可以实现容器集群的自动化部署、更新、维护等。利用kubernetes可以快速部署和扩展应用,并且节省资源。
Kubernetes架构

Kubernetes集群架构
Kubernetes集群采用主从节点的方式,为了防止单点故障,提高运行效率,kubernetes集群一般会有多个master节点(2n+1个)和node节点,master节点主要负责控制和协调整个集群,提交任务等,工作组件有etcd,apiserver,controller,sheduler。node节点主要负责执行具体的任务,工作组件有docker,kube-proxy,kubelet。
Master节点中组件:
Etcd:是一个服务发现型的存储仓库,存储集群的状态,包括集群中各个单元的配置信息和状态信息等。
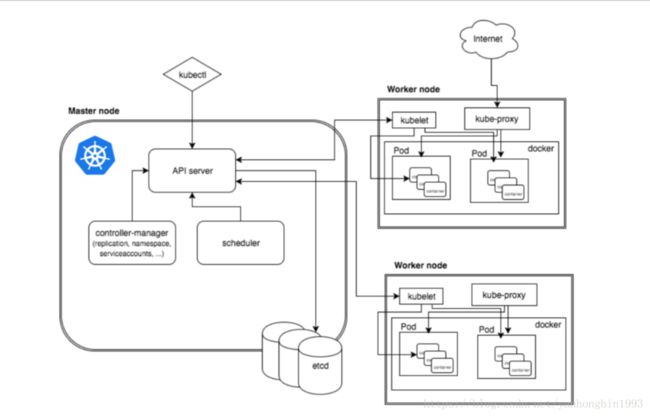
Kube-apiserver:提供集群的访问入口,而且由于apiserver对etcd进行了封装,所以为整个集群资源注册与发现的框架(各个组件通过apiserver在etcd注册资源状态或者发现资源的状态变化后作出调整),各个组件都通过与apiserver交互获取信息来实现各自的功能,比如kubelet和deploymentcontroller通过apiserver交互来实现工作节点的rolling update。Deploymentcontroller从apiserver获取用户的rolling update命令后,把新建RS和pod的信息通过apiserver(etcd)传递给kubelet去执行具体的创建工作。
Controller Manager:负责维护集群的状态,比如自动扩展、滚动更新等。Controller包括多个控制器,比如ReplicationController、ReplicaSetController、DeploymentController等,通过这些控制器来对集群中各种资源进行操作。比如DeploymentController通过感知各个节点的pod状态根据配置的replicas数量动态调整。
Scheduler:按照一定的调度策略把pod分配给各个工作节点。第一步先把能满足此pod需求的node节点列出来,然后对它进行优先级排序,每次把pod分配给优先级最高的node节点。
Node节点中的组件:
docker:因为每个node节点是运行容器应用,所以需要docker组件来负责创建和维护容器。包括下载镜像,创建镜像,运行容器等。
Kube-proxy:是service的具体实施组件,为service的服务发现和负载均衡提供支持。具体来说就是实现了本node内部的从pod到service和外部的从node port向service的访问。Proxy目前有两种实现方式userspace和iptables。userspace是最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过 iptables 转发到这个端口,然后在其内部负载均衡到实际的Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。iptables完全以iptables规则的方式来实现service 负载均衡。一直感觉kube-proxy和service理解的不太好。
Kubelet:负责维护容器的生命周期,定时从master节点的apiserver获取节点上pod等资源的新的配置状态,然后执行具体的调整工作。主要是负责把node节点的pod,container等资源的状态信息传递给master节点的apiserver,并从apiserver获取controller产生的信息去调用docker创建或者删除pod或容器等。
核心API对象
API对象是K8s集群中的管理操作单元。K8s集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的API对象,支持对该功能的管理操作。例如副本集Replica Set对应的API对象是RS。
Pod: Pod是在K8s集群中运行部署应用或服务的最小单元,一个pod里面可以运行多个容器。Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。一个服务还可以指定多个pod副本,来加快运行效率。可以把pod理解为小机器人,不同类型的业务就需要不同类型的小机器人去执行,一个业务可以派多个小机器人去执行。
Pod的五种状态:
Running pod已正常运行于某一节点上
Pending pod被k8s系统接受,但由于某种原因而未完全运行,如正在下载镜像文件
Succeeded pod里所有的containers均已正常终止
Failed pod里至少有一个container未正常终止
Unknown 由于未知原因无法获取pod状态,比如node无法连接
Service:service是kubernetes集群中一组pod的抽象,负责将请求发送给对应的pod。每个pod只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以新的ip和端口号提供服务,想要稳定地提供服务,需要服务发现(获取ip和port的过程)和负载均衡。服务发现完成的工作,是针对客户端访问的服务,在K8s集群中,客户端需要访问的服务就是Service对象。每个Service会对应一组pod的有效的虚拟IP,集群内部通过虚拟IP访问一个服务,service可以通过yaml(使用selector通过每个pod的label来识别它)访问这组pod中的每一个。Service的负载均衡是由kube-proxy实现的。
Service常用的三种类型:
- ClusterIP:默认类型,自动分配一个只有集群内部才可以访问的虚拟IP,可以通过先访问vip,然后根据它下面pod的label找到对应的pod。
- NodePort:最常用的类型,用来对集群外暴露Service,可以通过访问集群内的每个NodeIP:NodePort的方式,访问到对应Service后端的Endpoint。
- LoadBalancer:在NodePort的基础上,借助cloud provider提供的一个外部LB,将请求发送到NodeIP:NodePort。
Namespace:为集群提供虚拟的隔离作用,默认的namespace为defalut,不过一般为每个业务设置一个namespace,主要为了互不影响。
Replication Controller(RC): 通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动运行新的Pod副本;多于指定数目,RC就会杀死多余的Pod副本。是最早的副本控制器,只适用于长期伺服型的业务类型,比如web服务。
Replica Set(RS): RC的升级版,适用于更多的业务类型。
Deployment:现在最常用更新服务的控制器,用户利用它来创建、缩扩容、更新服务(pod)。一般通过deployment创建RS来管理pod。
Volume: 存储卷,每个pod中的存储卷由它内部的所有容器共享。
Job: 在有些场景下,是想要运行一些容器执行某种特定的任务,任务一旦执行完成,容器也就没有存在的必要了。在这种场景下,创建pod就显得不那么合适。于是就是了Job,Job指的就是那些一次性任务。通过Job运行一个容器,当其任务执行完以后,就自动退出,集群也不再重新将其唤醒。
cronJob:类似于linux中的crontab,可以定期去创建容器执行任务。