一文读懂python 中的正则表达式以及re模块的常用方法
写在开始
本篇博文是我在B站学习了别人的视频教程后,写出的个人总结,以供自己日后复习翻阅。若有谬误,还望各位看官不吝指教!
为了避免有打广告的嫌疑,原视频地址就不放上来了。如有侵权请通知删除。
表达式定义
正则表达式就是将一系列规则按照特定的语法抽象组合成的一个字符串
语法
-
自身匹配自身—— 这个就不用解释了
-
常用元字符表
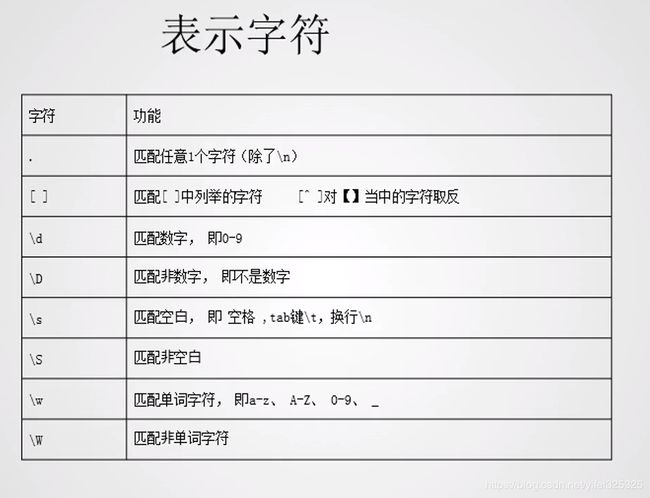
举例说明:
首先这里介绍一个在python中,正则表达式的包,
re. 里面的函数match(arg1,arg2)
match函数的两个参数解释:
arg1, 表示要填入的正则表达式;
arg2,表示要进行匹配的字符串;
匹配时按照正则表达式的语法从左往右对字符串中的字符一个个进行匹配,如果匹配成功,则返回一个Match对象,若匹配失败,则返回None。Match对象有一个函数叫group(),返回匹配出来的字符串。
下面详细举例说明- 元字符
.
import re result = re.match('.','hello') print(result) print(result.group()) ################## 结果输出 ################## <_sre.SRE_Match object; span=(0, 1), match='h'> h元字符
.因为匹配任意字符,所以从左开始就匹配到了h- []
匹配括号中列举的字符,比如[ab]则匹配a或b,[abc]`则匹配a或b或c
import re result = re.match('[ab]','hello') print(result) result2 = re.match('[ahb]','hello') print(result2) print(result2.group()) ################## 结果输出 ################## None <_sre.SRE_Match object; span=(0, 1), match='h'> h第2行的表达式中a或b 匹配h 肯定匹配失败,则第9行返回
None
第5行的 表达式中a或b或h匹配h ,匹配成功,第10行则返回Match对象,Match对象的group方法返回匹配出来的结果h- \d
,\s,\w` 介绍\d匹配所有数字,等价于[0-9]\s匹配空格,制表符,换行符\w匹配所有英文字母和数字以及下划线_,等价于[a-zA-Z0-9_]
import re result = re.match(r'\d','apple55hello') print(result) ################## 结果输出 ################## None首先后面的字符串第一个字符不是数字,所以匹配失败。
import re result = re.match(r'\d','4apple55hello') print(result) print(result.group) ################## 结果输出 ################## <_sre.SRE_Match object; span=(0, 1), match='4'> 4这个字符串首字符是4,所以就匹配成功了
剩下的就不用演示了,都比较好理解
\D,\S,\W
这个比较好理解,和前面的对照记忆,对前面对应的表达式取反即可
- 元字符
-
数量词表
常用数量表如下图:

*表示匹配前一个字符出现0或者无限次,即可有可无
import re
result = re.match(r'[a-z]*','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
<_sre.SRE_Match object; span=(0, 5), match='apple'>
apple
[a-z]*表示匹配小写英文字母0个或多个,所以结果就匹配了apple
+表示匹配前一个字符出现1或者无限次,即至少出现1次
import re
result = re.match(r'[a-z]+','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
<_sre.SRE_Match object; span=(0, 5), match='apple'>
apple
[a-z]+表示匹配小写英文字母1个或多个,所以结果就匹配了apple
?表示匹配前一个字符出现1次或者0次,即要么有1次,要么没有
import re
result = re.match(r'[a-z]?','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
<_sre.SRE_Match object; span=(0, 5), match='a'>
a
[a-z]?表示匹配小写英文字母1个或0个,所以结果就匹配了a
{m}表示匹配前一个字符出现m次
import re
result = re.match(r'[a-z]{3}','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
<_sre.SRE_Match object; span=(0, 3), match='app'>
app
[a-z]{3}表示匹配小写英文字母1个或0个,所以结果就匹配了app
同理,{m,n} 即代表从m到n次闭区间。{m,} 即代表从m到无限次左闭右开区间
注意,前面几个匹配0次的结果,如果匹配了零次,那么Match.group()方法的返回值就是一个空字符串
-
表示边界
表示边界的字符如下表

举例说明
- 例1.
import re
# 以小写字母开头至少1个,中间是数字至少1个,然后是2个小写字母。结果:apple55he
result = re.match(r'^[a-z]+\d+[a-z]{2}','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
<_sre.SRE_Match object; span=(0, 9), match='apple55he'>
apple55he
- 例2.
import re
# 以小写字母开头至少1个,中间是数字至少1个,然后是2个小写字母.结果: 报错
result = re.match(r'[a-z]+\d+[a-z]{2}$','apple55hello')
print(result)
print(result.group())
################## 结果输出 ##################
报错
从例2 就可以看出,正则的匹配是从左往右的,例2的匹配规则虽然没有^,但是还是表示要从小写字母开头至少1位开始匹配,所以个人觉得这个^ 在 re.match()这里可有可无。
\b和\B这两个边界符一般用处不大,这里不做介绍。
-
分组
在正则表达式中还有一组规则就是分组,详情见下表

-
|匹配左右任意一个表达式
例:
# 匹配1-100之间的数字(包括1和100两个边界) import re result1 = re.match(r'[1-9]+[0-9]?$|100$','99') print(result1.group()) result2 = re.match(r'[1-9]+[0-9]?$|100$','100') print(result2.group()) ################## 结果输出 ################## 99 100竖线左半边的表达式匹配到1-99的数字,右边直接用100本身匹配,相当于或的关系
-
()将括号中的字符作为一个分组
例1:
import re result = re.match(r'(^0[1-9]\d{1,2})-([^0]\d{7}$)','0755-12568971') print(result.groups())第一个括号匹配区号,必须以0开头,第2位1-9,第三位任意数字1-2位
第二个括号匹配电话,不能以0开头,后面是任意7位数字
注意这里用到了**
groups()** 是因为分组以后,返回的结果就是一个元组如果要是用**
group()** 的话,就需要传入参数,第1个分组就传入1,第2个分组就传入2.以此类推。那么大家可能会问,既然返回的是一个元组,为什么第一个参数不是传入0而是1呢?因为正则表达式其实有一个默认的分组0,就是整个表达式本身,所以,如果传入了0参数,就相当于取了整个表达式所匹配出来的结果。例2:
下面来看看分组的第二种用法,匹配
html语言中的标签import re result = re.match(r'<([a-zA-Z]+[0-9]*)>.+','hello world 2020
') print(result.group(0)) ################## 结果输出 ################## <h1>hello world 2020 </h1>这个例子的正则其实很好理解,确实结果是能匹配出来,但是我们看前后两个分组,都匹配的是
\w+,这样就造成一个问题:如果前后标签不相同,也是可以匹配的。如下例:import re result = re.match(r'(<[a-zA-Z]+[0-9]*)>.+','hello world 2020 '
) print(result.group(0)) ################## 结果输出 ################## <h1>hello world 2020 </a>这样的结果显然是错误的。那么这时候我们就需要分组了。
请看下例:
import re result = re.match(r'<([a-zA-Z]+[0-9]*)>.+','hello world 2020
') print(result.group(0)) ################## 结果输出 ################## <h1>hello world 2020 </h1>我们直接将后面整个小括号以及里面的内容用
\1来替代了。这个表达式的意思是:\1的位置和前面第一个分组需要匹配完全相同的内容。当然如果有多个分组,这个\1就需要\n来替代了。n 代表不同的分组组别。例:
import re result = re.match(r'<([a-zA-Z]+[0-9]*)><([a-zA-Z]+[0-9]*)>.+','hello world 2020
') print(result.group(0)) ################## 结果输出 ################## <body><h1>hello world 2020 </h1></body>根据这个例子就能很明显的看到,
html标签在匹配时,外层和里层的关系,以及分组的顺序问题。 -
(?P和) (?P=NAME)上一个例子我们知道了可以用
\n的方式来代表区别不同分组,但是这样区别不够直观,我们需要见名知意,所以(?P就出现了。具体使用方法请见下方举例:) import re result = re.match(r'<(?P[a-zA-Z]+[0-9]*)><(?P ,'[a-zA-Z]+[0-9]*)>.+' hello world 2020
') print(result.group(0)) ################## 结果输出 ################## <body><h1>hello world 2020 </h1></body>首先在第一个分组里,我们使用
?P<***>来给第一个分组起别名叫first_name, 同样的,第二个分组起名叫second_name。在后面使用的时候就使用语法(?P=first_name)和(?P=second_name)来代替。注意:这里的P必须是大写,而且还要注意小括号的位置
-
re模块的其他常用方法
-
re.seach(pattern,string,flags)搜索符合特征的字符串,返回的是Match对象pattern: 要匹配的正则表达式
string:待检测的字符串
flags:默认可以不传,详细的解释如下:
re.I(re.IGNORECASE): 忽略大小写 re.M(MULTILINE): 多行模式,改变’^’和’$’的行为 re.S(DOTALL): 点任意匹配模式,改变’.’的行为 re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释例:
import re result = re.search(r'\d+',"评论数:999 点击数:888") print(result.group()) ################## 结果输出 ################## 999返回的是一个Match对象,同样适用group()就可以打印搜索结果,这里没有打印出888,是因为搜索时,从左往右找,找到999已经匹配了,就不往后找了。
-
re.findall(pattern,string,flags)搜索所有符合规则的字符串,返回结果是字符串列表findall()的参数定义和seach()方法完全相同例:
import re result = re.findall(r'\d+',"评论数:999 点击数:888") print(result) ################## 结果输出 ################## ['999', '888']这个就和
search()方法不同了, 它可以找出后面字符串中所有符合规则的字符串 -
re.sub(pattern,args1,string)在string中找到符合规则的字符串,并用args1替换,返回替换后的字符串import re result = re.sub(r'\d+','345', "评论数:999 点击数:888") print(result) ################## 结果输出 ################## 评论数:345 点击数:345通过匹配规则找到所有的数字,并把数字都替换成345
-
re.split(pattern,string)将string通过规则进行分割,返回分割后的字符串列表import re result = re.split(r'[,。;!]' ,'我是一个测;试字符串,我将会被分割。我有各种标点符合!') print(result) ################## 结果输出 ################## ['我是一个测', '试字符串', '我将会被分割', '我有各种标点符合', '']虽然字符串也有一个
split()方法,但是那个方法只能传入具体的字符,而不支持正则表达式,所以相对于re.split()方法简直是弱爆了。
-
-
贪婪模式和非贪婪模式
一般包含数量词(+?*{m,n})的匹配都会是默认的贪婪模式,即尽可能多的去匹配。而非贪婪模式则恰恰相反,只要有一个匹配结果,就不会再往后继续匹配了。请看下例:
import re result = re.match(r'(.+)(\d+)','number is 123456') print(result.groups()) ################## 结果输出 ################## ('number is 12345', '6')这种就是贪婪模式,因为
.匹配任意字符,它就会一直往后匹配,只给最后\d的规则留了一个6去匹配(而且还是因为\d+的规则是至少有一个数字,比如下例,把+改成*就全给前面的.匹配走了,后面只剩了一个空串。)import re result = re.match(r'(.+)(\d*)','number is 123456') print(result.groups()) ################## 结果输出 ################## ('number is 123456', '')这个时候我们就需要使用非贪婪模式,尽可能少的匹配
import re result = re.match(r'(.+?)(\d+)','number is 123456') print(result.groups()) ################## 结果输出 ################## ('number is ', '123456')在数量词后面加
?即可变成非贪婪匹配模式,当.去匹配时,看到后面的规则是至少1个数字的贪婪模式,所以它就只配了前面的所有字母和空格,后面的数字就留给了\d+去匹配。import re result = re.match(r'(.+?)(\d*)','number is 123456') print(result.groups()) ################## 结果输出 ################## ('n', '')如上例,如果将
\d+改成\d*那么当前面匹配时,发现后面分组数字部分可有可无时,那我第一个分组就直接最少匹配一个n,后面分组就直接是空串了。 -
练习
下面我们来开始练习写一些正则并分析一下
-
匹配大陆手机号
分析:
- 大陆手机号长度是11位纯数字
- 手机号以
1开头 - 第2位是在3-8 之间,没有0,1,2,9
- 第3位到第11位为任意0-9之间的数字
综上:我们可以写出正则表达式如下
import re result = re.match(r'^1[3-8]\d{9}$','17012345678') print(result.group())最后记得一定要有个
$结尾符,这样才能完全匹配 -
匹配邮箱
分析:
- 只能以字母或数字开头,并至少1位
- 包含
@ @符号后面是字母或数字,并至少1位- 再往后是
.+域名(字母或数字,并至少1位)
综上:表达式如下
import re result = re.match(r'[a-zA-Z0-9]+.*@[A-Za-z0-9]+.*[a-zA-Z0-9]+$','[email protected]') print(result.group())注意这个正则中间有个
.*的部分,因为有些人的邮箱名可能会有下划线或者.这个就都能匹配到了,另外对于多级域名的情况,使用了后半部分的.*也进行了匹配。同理最后要加上$结尾符,表示正则到此为止,如果后面还有字符就不能匹配了。
-
结束