C与C++总结
int a=10;
int b=20;
1.在C语言中
(a *(a 2.在C++中 (a 3.C++中的const 修饰声明的变量放在符号表(key value)中,当对其中的key取地址时会单独的分配内存空间 4.C++中的const常量约等于宏定义 #defind c 3 ≈ const a=3 5.C++中#define可用undef限定作用域,而const 则是有作用域的 6C++中普通引用必须初始化 7.C++中引用的本质还是指针(int * const a) 8.内联函数在编译时直接将函数体插入函数调用的地方 9.C++中形参前面有默认参数,后面必须是默认参数(编译器会自动处理); 10.占位参数为以后的扩展提供线索 11.类的成员属性是不能在类的内部实现的,但可以调用构造函数(与类名相同,无返回值)进行初始化 12.C++中写了构造函数就一定要调用 13.C++中的拷贝构造函数可以解决深拷贝、浅拷贝的问题 14C++中=号也涉及到深拷贝和浅拷贝,可用操作符重载解决 15.C++中类B嵌套A要用初始化列表,按照定义的顺序进行初始化(private里的顺序),先组合组合函数 CMyClass::CMyClass(int x, int y) : m_y(y), m_x(m_y) 16.类里的const int a 也要进行初始化 17.匿名对象产生的生命周期关键看怎么接 18.静态成员变量是类所定义的对象共享的,且必须用类名作用符进行定义;而静态成员函数的调用方法可是:类名:方法; 静态成员方法能调用静态成员变量,但是不能调用普通的变量,因为分不清楚调用哪一个对象。 19. 20. 21. 22. 参数表代表了 左操作数和右操作数 23. 24. 25.Complex operator++(Complex &c1,int) //可用占位操作进行操作数重载 26.ostream& operator<<(ostream &cout, Complex &c1) //这里只能用全局函数实现,因为不能调用ostream 271、返回值为引用型(int& )的时候,返回的是地址,因为这里用的是 int& a=mymay.at(); ,所以a和m_data_指的是同一块地址(由寄存器eax传回的5879712)。 28. 返回的是一个内存块 29.protected用于家族内部交流 30.C++中父子兼容性原则,父类指针可以指向子类,子类就是一种特殊的父类。。。。。。 31.多态是同一个行为具有多个不同表现形式或形态的能力 32. 33.不写virtual关键字是静态联编,加了动态联编 动态联编是指联编在程序运行时动态地进行,根据当时的情况来确定调用哪个同名函数,实际上是在运行时虚函数的实现。这种联编又称为晚期联编,或动态束定。动态联编对成员函数的选择是基于对象的类型,针对不同的对象类型将做出不同的编译结果。C++中一般情况下的联编是静态联编,但是当涉及到多态性和虚函数时应该使用动态联编。动态联编的优点是灵活性强,但效率低。 34.当我们使用关键字new在堆上动态创建一个对象时,它实际上做了三件事:获得一块内存空间、调用构造函数、返回正确的指针 35. 36. 37.重定义就是非虚函数重写 子类会覆盖父类 38. 根据this指针找虚拟指针vptr 找虚函数表 39. 子类的虚指针是分布初始的 40. 41. 42 43. 44. 45. 46. 调用函数模板将严格进行类型匹配,不会进行类型转化;而普通类型可以进行隐式类型转换 47. 48. 49子模板继承时需要知道父类的具体模板,因为要分配内存 50.friend ostream& operator << template 原因是C++编译器生成的函数头不一样 51. 52.在C++中.h和.cpp分开来的模板函数和类要加上头文件#include “.cpp” 53. 53. 54.const_cast 将只读属性改成普通属性 55. 56.异常是跨函数的 57. 58. 59. /*栈解旋*/ //意思就是在throw之前不断压栈的数据,在throw之后会依次进行析构 //异常被抛出后,从进入try块起,到异常被抛掷前,这期间在栈上的构造的所有对象,都会被自动析构。析构的顺序与构造的顺序相反 60. 61. 62.cin.getline()可以接受输入空格 63.ignore()函数用于输入流。它读入字符,直到已经读了num 个字符(默认为1)或是直到字符delim 被读入(默认为EOF).简单来说就是忽略前面n个字符 64.C++distance求数组下标的值 64.cin.putback()先从缓冲区拿数据在吐回去 65. 一种就是和put()对应的形式:ifstream &get(char &ch);功能是从流中读取一个字符,结果保存在引用ch中,如果到文件尾,返回空字符 66.在调用push_back时,每次执行push_back操作,相当于底层的数组实现要重新分配大小;这种实现体现到vector实现就是每当push_back一个元素,都要重新分配一个大一个元素的存储,然后将原来的元素拷贝到新的存储,之后在拷贝push_back的元素,最后要析构原有的vector并释放原有的内存。 67 erase函数的原型如下: 68. 逆向迭代器reverse_iterator 并且it1++; 69. 70.distance主要是用来求两个迭代器之间的元素个数。 71. 72. 左闭右开删除前面的指针。。 73.仿函数(functor),就是使一个类的使用看上去象一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了。 template class display { public: void operator()(const T &x) { cout< } }; 74.pair是将2个数据组合成一个数据,当需要这样的需求时就可以使用pair,如stl中的map就是将key和value放在一起来保存。另一个应用是,当一个函数需要返回2个数据的时候,可以选择pair。 pair的实现是一个结构体,主要的两个成员变量是first second 因为是使用struct不是class,所以可以直接使用pair的成员变量。 75.pair 76. 77. 78. 79. 80. 81. 82. 83. 84. 85 86. 87 transform函数要有返回值 88. 89. template 90. 91. 92. 92 93. temp =(Teacher *) LinkList_Get(list, i); //头部LinkListNode node代表结构体的首地址,转换够可以变成完全结构体 94.循环链表异常处理 95. 96 97. 98. 括号匹配算法思想分析 99. 100. 101 102. 103.树转换成二叉树(左为尊,长兄为父) 104. 105. 106.1.递归方法:分别计算出左子树、右子树的深度,最后取较大者+1即是二叉树深度。 107. 非递归中序遍历 108.插入排序:①元素拿出来②符合条件的元素后移 109. void InsertSort(int *array,int len) for (i=1;i } 110. 选择排序和冒泡排序的区别:看是否是相邻元素比较,如果是则是冒泡 111. //冒泡排序,相邻元素进行比较 for (i=0;i 112. //希尔排序,分组进行 void Shell_Sort(int *array,int len) do //两个for循环算作一轮 for (i=increment;i } 113.快速排序 int partion(int *array, int low, int high) //开始划分左右子区间 void Q_Sort(int *array,int low,int high) //对子序列1进行排序 //对子序列2进行排序 } void PrintArray(const int *array, int len) 思想:①首先要找出基准点 ②以基准点划分左右区间 ③在进行递归的左右区间的排序  {
{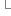 }
}


![]()


Complex operator++(Complex &c1,int) //可用占位操作进行操作数重载
{
Complex tmp = c1;
c1.m_a++;
c1.m_b++;
return tmp; //先使用后++
}
{
cout << c1.m_a << c1.m_b;
return cout;
}


![]()








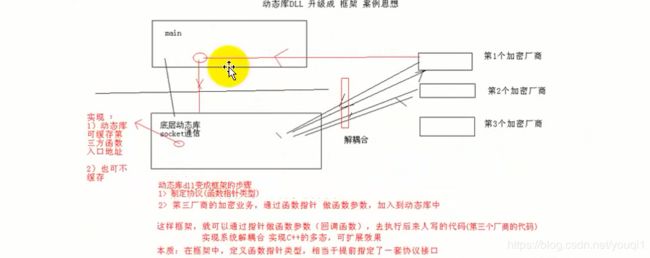



ostream& operator << (ostream &out, const Complex
{
out << "a:"<
}







![]() .
.(1)string& erase ( size_t pos = 0, size_t n = npos );
(2)iterator erase ( iterator position );
(3)iterator erase ( iterator first, iterator last );
也就是说有三种用法:
(1)erase(pos,n); 删除从pos开始的n个字符,比如erase(0,1)就是删除第一个字符
(2)erase(position);删除position处的一个字符(position是个string类型的迭代器)
(3)erase(first,last);删除从first到last之间的字符(first和last都是迭代器)
下面给你一个例子:


![]()










![]()


typename iterator_traits<_InIt>::difference_type
count_if(_InIt _First, _InIt _Last, _Pr _Pred);
前两个参数是iterator(迭代器),表示查找半闭合区间的前后两个位置,第三个参数为一个用户定义的predicate function object,而predicate意思就是说是一个返回值是bool型的仿函数(function object,也称functor)。





 用链表实现链表栈
用链表实现链表栈









{
int i = 0;
int j = 0;
int k = 0;
int temp = 0;
k = i;
temp = array[k]; //选出元素
for (j=i-1;j>=0&&(temp
array[j+1] = array[j]; //元素后移
k = j; //需要插入元素的位置
}
array[k] = temp ;
}
void BubbleSort(int *array,int len)
{
int i = 0;
int j = 0;
int temp = 0;
int Tag = 1; //标记是否排好序 1为没有排序好 0为排好了
Tag = 0;
for (j=i;j
if (array[j]>array[j+1])
{
temp = array[j+1];
array[j + 1] = array[j];
array[j] = temp;
Tag = 1;
}
}
}
}
{
int i = 0;
int j = 0;
int k = -1;
int temp = -1;
int increment = len;
{
increment = increment / 3 + 1;
k = i;
temp = array[k];
for (j=i-increment;j>=0&&(temp
array[j+increment] = array[j];
k = j;
}
array[k]=temp;
}
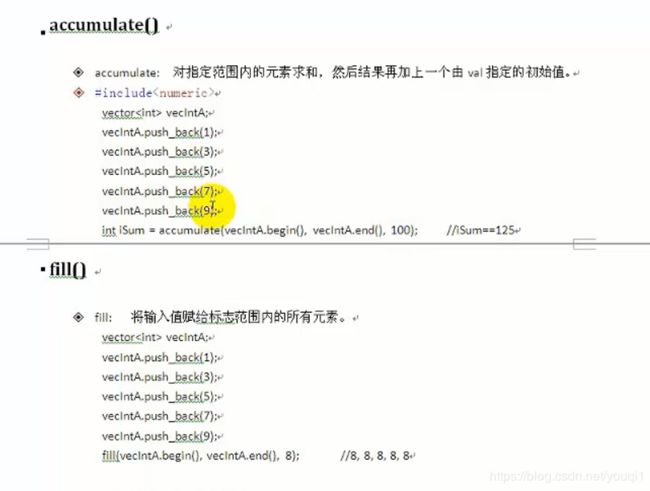
} while (increment>1); //先执行后循环
{
int pv = array[low];
while (low
while (low
{
high--; //比基准大,本来就在右边,所以向前移
}
Swap(array, low, high);
while (low
low++; //比基准大,本来就在左边,所以向后移
}
Swap(array, low, high);
}
return low;
}
{
if (low
//选择一个pv值进行划分
int pivot=partion(array, low, high);
Q_Sort(array, low, pivot - 1);
Q_Sort(array, pivot + 1, high);
}
{
for (int i = 0;i < len;i++)
{
printf(" %d ", *(i + array));
}
printf("\n");
}