1. 引言
统计一天内交易成功的商品中, 它们的城区分布是怎样的, 然后绘制一天内交易成功的商品中, 各城区交易量的饼图.
2. 分析
- 查找某天发布的物品当天就完成交易的
- 按区域统计筛选出的结果, 并按交易量从高到低排序
- 用函数生成图表数据
3. 实现代码
In [1] :
from pymongo import MongoClient
import charts
Server running in the folder /home/wjh at 127.0.0.1:35042
In [2] :
client = MongoClient('10.66.17.17', 27017)
database = client['ganji']
item_info = database['item_info']
In [3] :
# 查看源数据格式
[i for i in item_into.find().limit(3)
Out [3] :
[{'_id': ObjectId('5698f524a98063dbe9e91ca8'),
'area': ['朝阳', '高碑店'],
'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手冰柜'],
'look': '-',
'price': 450,
'pub_date': '2016.01.12',
'time': 0,
'title': '【图】95成新小冰柜转让 - 朝阳高碑店二手家电 - 北京58同城',
'url': 'http://bj.58.com/jiadian/24541664530488x.shtml'},
{'_id': ObjectId('5698f525a98063dbe4e91ca8'),
'area': ['朝阳', '定福庄'],
'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手洗衣机'],
'look': '-',
'price': 1500,
'pub_date': '2016.01.14',
'time': 2,
'title': '【图】洗衣机,小冰箱,小冰柜,冷饮机 - 朝阳定福庄二手家电 - 北京58同城',
'url': 'http://bj.58.com/jiadian/24349380911041x.shtml'},
{'_id': ObjectId('5698f525a98063dbe7e91ca8'),
'area': ['朝阳', '望京'],
'cates': ['北京58同城', '北京二手市场', '北京二手台式机/配件'],
'look': '-',
'price': 1500,
'pub_date': '2015.12.27',
'time': 3,
'title': '【图】三星 A5 白色 没有打开过 - 朝阳望京台式机/配件 - 北京58同城',
'url': 'http://bj.58.com/diannao/24475337853109x.shtml'}]
In [4] :
# 定义函数方便快速生成图表数据
def data_gen(date, time):
# 定义管道模型
pipeline = [
# 筛选匹配数据
{'$match': {'$and': [{'pub_date': date}, {'time': time}]}},
# 以区域列表中的第一个元素分组并统计数量
{'$group': {'_id': {'$slice': ['$area', 1]}, 'counts': {'$sum': 1}}},
# 按数量从高到低排序
{'$sort': {'counts': -1}}
]
# 生成所有数据
for item in item_info.aggregate(pipeline):
yield [item['_id'][0], item['counts']]
# 输出看下结果
[i for i in data_gen('2015.12.22', 1)]
Out [4] :
[['朝阳', 35],
['不明', 18],
['海淀', 18],
['大兴', 8],
['通州', 8],
['丰台', 7],
['昌平', 6],
['西城', 6],
['房山', 2],
['东城', 2],
['顺义', 2],
['石景山', 2],
['崇文', 1],
['怀柔', 1],
['北京周边', 1],
['门头沟', 1],
['平谷', 1]]
In [5] :
# 图表参数
options = {
'char': {'zoomType': 'xy'},
'title': {'text': '北京城区某日二手物品发帖量区域分布'},
'subtitle': {'text': '图表展示二手物品区域分布发帖量'},
}
# 图表数据
serises = {
'name': 'one_day',
'type': 'pie',
'data': [i for i in data_gen('2015.12.30', 1)],
}
charts.plot(serises, show='inline', options=options)
Out [5] :
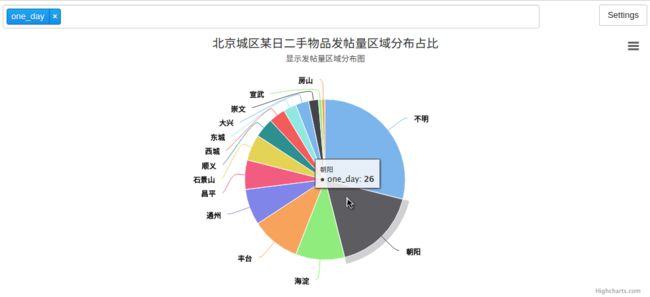
Paste_Image.png
4. 总结
- 数据可以经过层层筛选得出最终想要的结果
- 这些过滤管道, 每一个都是字典的结构
- charts图表数据结构可以从
highcharts官网中得到