wide & Deep 和 Deep & Cross 及tensorflow实现
前言
最近读了下Google的两篇文章《Wide&Deep Learning》和《Deep&Cross Network》,趁着热乎比较下,顺道写个demo,免得后面用的时候瞎搞。
前者是用来给用户推荐潜在喜欢的APP;后者是用来预测用户可能点击的广告排序。基于用户基本信息和行为日志来做个性化的推荐,是商业化的重要一步,做得好,用户使用起来甚是满意,广告商支付更多费用;做得差,大家只能喝喝西风,吃点咸菜。
Why Deep-Network ?
关于推荐,前面博文FTRL系列讲过,那是种基于基本特征和二维组合特征的线性推荐模型。其优点:模型简单明白,工程实现快捷,badcase调整方便。缺点也很明显:对更高维抽象特征无法表示,高维组合特征不全。而Deep-Network能够表达高维抽象特征,刚好可以弥补了线性模型这方面的缺点。
Why Cross-Network ?
组合特征,为什么止步于两维组合?多维组合,不单说手挑组合特征费时费力,假设特征都组合起来,特征的数量非得彪上天不可。但是Cross-Network(参考5)则可以很好地解决组合特征的数量飙升的问题。所以说,并不是问题真难以解决,只不过牛人还没有解它而已。
结构比较
啥都不如图明白,直接上图,左侧 Wide and Deep Network 右侧 Deep and Cross Network
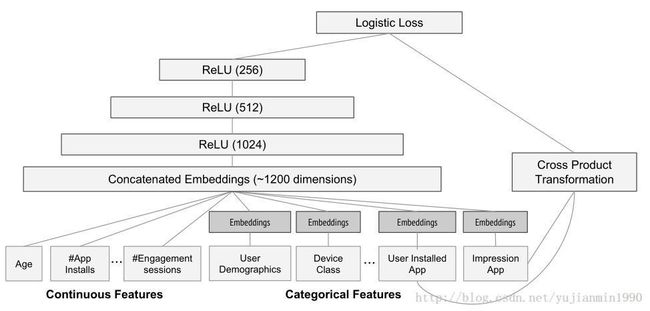
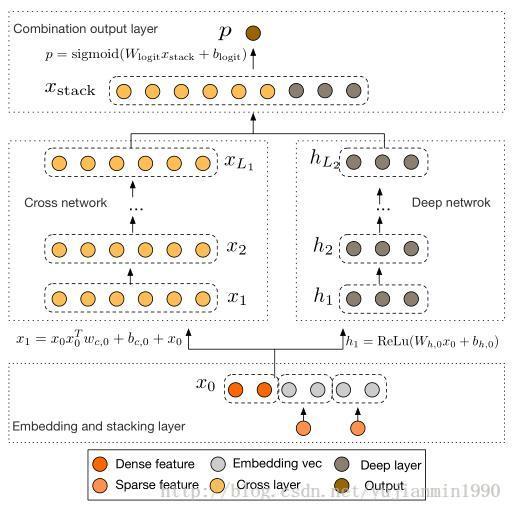
上面两个图清晰地表示了两种方法的框架结构。
特征输入
1)W&D的特征包括三方面:
User-Feature:contry, language, demographics.
Contextual-Feature:device, hour of the day, day of the week.
Impression-Feature:app age, historical statistics of an app.
1.1)Wide部分的输入特征:
raw input features and transformed features [手挑的交叉特征].
notice: W&D这里的cross-product transformation:
只在离散特征之间做组合,不管是文本策略型的,还是离散值的;没有连续值特征的啥事,至少在W&D的paper里面是这样使用的。
1.2)Deep部分的输入特征: raw input+embeding处理
对非连续值之外的特征做embedding处理,这里都是策略特征,就是乘以个embedding-matrix。在TensorFlow里面的接口是:tf.feature_column.embedding_column,默认trainable=True.
对连续值特征的处理是:将其按照累积分布函数P(X≤x),压缩至[0,1]内。
notice: Wide部分用FTRL+L1来训练;Deep部分用AdaGrad来训练。
Wide&Deep在TensorFlow里面的API接口为:tf.estimator.DNNLinearCombinedClassifier
2)D&C的输入特征及处理:
所有输入统一处理,不再区分是给Deep部分还是Cross部分。
对高维的输入(一个特征有非常多的可能性),加embeding matrix,降低维度表示,dense维度估算: 6∗(category−cardinality)1/4 6 ∗ ( c a t e g o r y − c a r d i n a l i t y ) 1 / 4 。
notice:W&D和D&C里的embedding不是语言模型中常说的Word2Vec(根据上下文学习词的低维表示),而是仅仅通过矩阵W,将离散化且非常稀疏的one-hot形式词,降低维度而已。参数矩阵的学习方法是正常的梯度下降。
对连续值的,则用log做压缩转换。
stack上述特征,分别做deep-network和Cross-network的输入。
cross解释
cross-network在引用5中有详细介绍,但是在D&C里面是修改之后的cross-network。
单样本下大小为: x0=[d×1] x 0 = [ d × 1 ] ; xl=[d×1] x l = [ d × 1 ] ; wembedding=[d×1] w e m b e d d i n g = [ d × 1 ] ; b=[d×1] b = [ d × 1 ] ,注意 w是共享的,对这一层交叉特征而言,为啥共享呢,目测一方面为了节约空间,还一个可能原因是收敛困难(待定)。
tf实现D&C的注意事项
1)mult-hot的特征表示问题
tf.feature_column.indicator_column来表示。
注意,_IndicatorColumn不支持叠加_EmbeddingColumn操作。
2)embedding问题
tf.feature_column.embedding_column来表示,默认trainable=True
特征间共享embed: tf.contrib.layers.shared_embedding_columns
3)数据读入的问题
dataset流解析函数要在input_fn内部。
tf.cast 与 tf.string_to_number。
4)tf.estimator.Estimator问题
自定义的model_fn的参数params项,是显式地传递。
注意,estimator本身带有异步更新的机制,SycOpt。
5)cross-network的实现
借助广播来计算。
验证,tile是不影响原始参数梯度计算的。
6)不定长特征的embedding
tf.feature_column + estimator
是不支持不定长特征的处理的,仅支持定长的。
只能用tf.nn.embedding_lookup_sparse来处理不定长特征。
对字符串离散不定长特征的示例代码附在后面。
非用tf.feature_column处理不定长特征,会有报错
convert Sparse Tensor to Tensor的维度错误,但是不知道内部哪里的错。
tf_debug
因为是用tf.estimator写的模型,无法使用print查看内部变量,调试就成了大问题。tf.estimator在设计的时候,考虑到了这种情况,将其设计为可接收外部定义的hook,支持tf_debug。详细代码见下面的mult.py。
hook的样式,params[‘hooks’] =
[tf_debug.LocalCLIDebugHook()],
然后传递到estimator内部,给train或者evaluate使用。
用tf_debug查看内部变量,举个栗子,想看下
tf.feature_column.embedding_column的combiner=sum是怎么个操作。
某特征输入:
1)State-gov|human 2)Self-emp-not-inc|human 3)State-gov|human
为了方便,初始化embedding-matrix=ones.

debug下运行,得到embedding-mat变量如下:
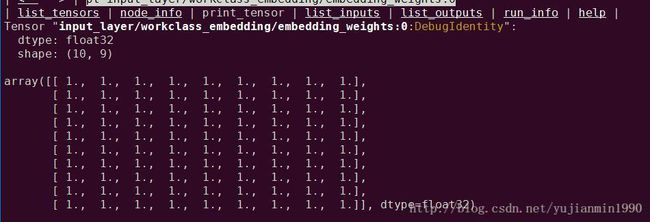
对特征的处理结果:编码表示和index值(embedding输入侧的的索引值)


发现embedding-vec如下:

发现:其中的combiner=sum是依照index找到embedding-vec,然后对embedding_vec加和得到embedding结果的。自行替换成随机初始化的embedding-matrix,得到同样的验证结果。
github 源码
利用tf.feature_column + dataset + tf.estimator 实现Deep and Cross。
数据集是census income dataset。
D&C 测试 demo : https://github.com/jxyyjm/tensorflow_test/blob/master/src/deep_and_cross.py
tf_debug 测试 demo : https://github.com/jxyyjm/tensorflow_test/blob/master/src/multi.py
下面给出cross_计算在tf里面的多种实现,对tf.matmul /tf.tensordot的应用是核心,简洁高效是重要的。
#!/usr/bin/python
# -*- coding:utf-8 -*-
import tensorflow as tf
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def cross_op(x0, x, w, b):
## absolute the defination 计算速度最慢,低效 ##
x0 = tf.expand_dims(x0, axis=2) # mxdx1
x = tf.expand_dims(x, axis=2) # mxdx1
multiple = w.get_shape().as_list()[0]
x0_broad_horizon = tf.tile(x0, [1,1,multiple]) # mxdx1 -> mxdxd #
x_broad_vertical = tf.transpose(tf.tile(x, [1,1,multiple]), [0,2,1]) # mxdx1 -> mxdxd #
w_broad_horizon = tf.tile(w, [1,multiple]) # dx1 -> dxd #
mid_res = tf.multiply(tf.multiply(x0_broad_horizon, x_broad_vertical), tf.transpose(w_broad_horizon)) # mxdxd # here use broadcast compute #
res = tf.reduce_sum(mid_res, axis=2) # mxd #
res = res + tf.transpose(b) # mxd + 1xd # here also use broadcast compute #a
return res
def cross_op2(x0, x, w, b):
## 充分利用了广播计算 来实现cross,也很低效 ##
x0 = tf.expand_dims(x0, axis=2) # mxdx1
x = tf.expand_dims(x, axis=2) # mxdx1
dot = tf.matmul(x0, tf.transpose(x, [0, 2, 1]))
mid_res = tf.multiply(dot, tf.transpose(w))
res = tf.reduce_sum(mid_res, axis=2) + tf.transpose(b) # mxd + 1xd # here also use broadcast compute #
return res
def cross_op_single_data(x0, x, w, b):
## 最简洁的cross_实现方法,单条样本 ##
## all para size is [d, 1] ##
dot = tf.matmul(x0, tf.transpose(x)) # dxd
cros= tf.tensordot(dot, w, [[1], [0]]) + b ## dot的某行 dot w的某列 ##
return cros
def cross_op_batch_data(x0, x, w, b):
## x0 and x size is [batch, d],与后面的方法一致,计算高效 ##
## w and b size is [d, 1]
x0 = tf.expand_dims(x0, 2) # [batch, d, 1]
x = tf.expand_dims(x, 2) # [batch, d, 1]
dot= tf.matmul(x0, tf.transpose(x, [0, 2, 1])) # [batch, d, d] = batch x {[dx1]x[1xd]
#cros = tf.tensordot(dot, w, [[1], [0]) + b # [batch, d, 1] this is wrong
cros = tf.tensordot(dot, w, 1) + b ## 这种写法来源与maxnet ## 很奇妙 ##
return tf.squeeze(cros, 2)
def cross_op_None_batch(x0, x, w, b):
## x0 and x size is [None, d] ## 借助了keras.backend.batch_dot ##
## w and b size is [d, 1]
x0 = tf.expand_dims(x0, 2) # [batch, d, 1]
x = tf.expand_dims(x, 2) # [batch, d, 1]
dot= tf.contrib.keras.backend.batch_dot(x0, tf.transpose(x, [0,2,1]), [2, 1])
#cros = tf.tensordot(dot, w, [[1], [0]]) + b # this is wrong
cros = tf.tensordot(dot, w, 1) + b
return tf.squeeze(cros, 2)
Reference
- 《2016-Wide & Deep Learning for Recommender Systems》
- 《2017-Deep & Cross Network for Ad Click Predictions》
- https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html (google research blog)
- https://github.com/tensorflow/models/tree/master/official/wide_deep (wide&deep github code)
- 《2016-Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features》
附:tf.nn.embedding_lookup_sparse如何处理不定长的字符串的embedding问题。
输入数据如下:
csv = [
"1,oscars|brad-pitt|awards",
"2,oscars|film|reviews",
"3,matt-damon|bourne",
]
第二列是不定长的特征。处理如下:
import tensorflow as tf
# Purposefully omitting "bourne" to demonstrate OOV mappings.
TAG_SET = ["oscars", "brad-pitt", "awards", "film", "reviews", "matt-damon"]
NUM_OOV = 1
def sparse_from_csv(csv):
ids, post_tags_str = tf.decode_csv(csv, [[-1], [""]])
table = tf.contrib.lookup.index_table_from_tensor(
mapping=TAG_SET, num_oov_buckets=NUM_OOV, default_value=-1) ## 这里构造了个查找表 ##
split_tags = tf.string_split(post_tags_str, "|")
return ids, tf.SparseTensor(
indices=split_tags.indices,
values=table.lookup(split_tags.values), ## 这里给出了不同值通过表查到的index ##
dense_shape=split_tags.dense_shape)
# Optionally create an embedding for this.
TAG_EMBEDDING_DIM = 3
ids, tags = sparse_from_csv(csv)
embedding_params = tf.Variable(tf.truncated_normal([len(TAG_SET) + NUM_OOV, TAG_EMBEDDING_DIM]))
embedded_tags = tf.nn.embedding_lookup_sparse(embedding_params, sp_ids=tags, sp_weights=None)
# Test it out
with tf.Session() as s:
s.run([tf.global_variables_initializer(), tf.tables_initializer()])
print(s.run([ids, embedded_tags]))1) 这样就可以处理非定长的特征了,坏处是无法纳入到tf.feature_column + tf.estimator模型框架里,模型输入和整体结构都暴露在外面,丑~
2)改写成共享embedding也非常容易。
据说最新的tf 1.5里新增 Add support for sparse multidimensional feature columns.【鼓掌】抽空看看