使用kaist数据集训练tf-faster-rcnn
使用kaist数据集训练tf-faster-rcnn
首先是修改pascal_voc.py,新建自己的kaist_rgb.py
pacal_voc的数据格式很麻烦,annotation是xml格式,自己的数据一般都是txt,所以,不会像读取pascal_voc数据那么复杂。下面是前人在pascal_voc.py 基础上写的kaist Dataset的接口:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
#import datasets.caltech
import os
from datasets.imdb import imdb
import xml.dom.minidom as minidom
import numpy as np
import scipy.sparse
import scipy.io as sio
import utils.cython_bbox
import pickle
import subprocess
from model.config import cfg
class kaist_rgb(imdb):
def __init__(self, image_set):
imdb.__init__(self, 'kaist_' + image_set) # image_set: train04 or test
self._image_set = image_set
self._devkit_path = self._get_default_path()
self._data_path = self._get_default_path()
self._classes = ('__background__', 'pedestrian')
self._class_to_ind = dict(zip(self.classes, range(self.num_classes)))
# self._class_to_ind = {'__background__': 0, 'pedestrian': 1}
self._image_ext = '.jpg'
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.selective_search_roidb
# PASCAL specific config options
self.config = {'cleanup': True,
'use_salt': True,
'use_diff': False,
'matlab_eval': False,
'rpn_file': None,
'min_size': 2}
assert os.path.exists(self._devkit_path), 'VOCdevkit path does not exist: {}'.format(self._devkit_path)
assert os.path.exists(self._data_path), 'Path does not exist: {}'.format(self._data_path)
def image_path_at(self, i):
"""
Return the absolute path to image i in the image sequence.
"""
return self.image_path_from_index(self._image_index[i])
def image_path_from_index(self, index):
"""
Construct an image path from the image's "index" identifier.
"""
# image_path = os.path.join(self._data_path, self._image_set, 'images', index + self._image_ext)
image_path = os.path.join(self._data_path, self._image_set, 'images', index[:-6] + 'visible/' + index[-6:] + self._image_ext)
assert os.path.exists(image_path), 'Path does not exist: {}'.format(image_path)
return image_path
def _load_image_set_index(self):
"""
Load the indexes listed in this dataset's image set file.
"""
# Example path to image set file:
# self._devkit_path + /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt
image_set_file = os.path.join(self._data_path, self._image_set, self._image_set + '.txt')
assert os.path.exists(image_set_file), 'Path does not exist: {}'.format(image_set_file)
with open(image_set_file) as f:
image_index = [x.strip() for x in f.readlines()]
return image_index
def _get_default_path(self):
"""
Return the default path where kaist dataset is expected to be installed.
"""
return os.path.join(cfg.DATA_DIR, 'kaist')
def gt_roidb(self):
"""
Return the database of ground-truth regions of interest.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
try:
roidb = pickle.load(fid)
except:
roidb = pickle.load(fid, encoding='bytes')
print ('{} gt roidb loaded from {}'.format(self.name, cache_file))
#print (roidb)
#for dic in roidb:
# print (dic['gt_overlaps'])
return roidb
gt_roidb = [self._load_revised_annotation(index)
for index in self.image_index]
#print (gt_roidb)
with open(cache_file, 'wb') as fid:
pickle.dump(gt_roidb, fid, pickle.HIGHEST_PROTOCOL)
print ('wrote gt roidb to {}'.format(cache_file))
return gt_roidb
def selective_search_roidb(self):
"""
Return the database of selective search regions of interest.
Ground-truth ROIs are also included.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path,
self.name + '_selective_search_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = pickle.load(fid)
print ('{} ss roidb loaded from {}'.format(self.name, cache_file))
return roidb
if self._image_set != 'test-all':
gt_roidb = self.gt_roidb()
ss_roidb = self._load_selective_search_roidb(gt_roidb)
roidb = imdb.merge_roidbs(gt_roidb, ss_roidb)
else:
roidb = self._load_selective_search_roidb(None)
with open(cache_file, 'wb') as fid:
pickle.dump(roidb, fid, pickle.HIGHEST_PROTOCOL)
print('wrote ss roidb to {}'.format(cache_file))
return roidb
def _load_selective_search_roidb(self, gt_roidb):
filename = os.path.abspath(os.path.join(self.cache_path, '..',
'selective_search_data',
self.name + '.mat'))
assert os.path.exists(filename), 'Selective search data not found at: {}'.format(filename)
raw_data = sio.loadmat(filename)['boxes'].ravel()
box_list = []
for i in xrange(raw_data.shape[0]):
box_list.append(raw_data[i][:, :] - 1)
return self.create_roidb_from_box_list(box_list, gt_roidb)
def selective_search_IJCV_roidb(self):
"""
Return the database of selective search regions of interest.
Ground-truth ROIs are also included.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path,
'{:s}_selective_search_IJCV_top_{:d}_roidb.pkl'.
format(self.name, self.config['top_k']))
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = pickle.load(fid)
print ('{} ss roidb loaded from {}'.format(self.name, cache_file))
gt_roidb = self.gt_roidb()
ss_roidb = self._load_selective_search_IJCV_roidb(gt_roidb)
roidb = imdb.merge_roidbs(gt_roidb, ss_roidb)
with open(cache_file, 'wb') as fid:
pickle.dump(roidb, fid, pickle.HIGHEST_PROTOCOL)
print ('wrote ss roidb to {}'.format(cache_file))
return roidb
def rpn_roidb(self):
if self._image_set != 'test-all':
gt_roidb = self.gt_roidb()
rpn_roidb = self._load_rpn_roidb(gt_roidb)
roidb = imdb.merge_roidbs(gt_roidb, rpn_roidb)
else:
roidb = self._load_rpn_roidb(None)
return roidb
def _load_rpn_roidb(self, gt_roidb):
filename = self.config['rpn_file']
print ('loading {}'.format(filename))
assert os.path.exists(filename), 'rpn data not found at: {}'.format(filename)
with open(filename, 'rb') as f:
box_list = pickle.load(f)
return self.create_roidb_from_box_list(box_list, gt_roidb)
def _load_selective_search_IJCV_roidb(self, gt_roidb):
IJCV_path = os.path.abspath(os.path.join(self.cache_path, '..',
'selective_search_IJCV_data',
'voc_' + self._year))
assert os.path.exists(IJCV_path), 'Selective search IJCV data not found at: {}'.format(IJCV_path)
top_k = self.config['top_k']
box_list = []
for i in xrange(self.num_images):
filename = os.path.join(IJCV_path, self.image_index[i] + '.mat')
raw_data = sio.loadmat(filename)
box_list.append((raw_data['boxes'][:top_k, :] - 1).astype(np.uint16))
return self.create_roidb_from_box_list(box_list, gt_roidb)
def _load_revised_annotation(self, index):
"""
Load image and bounding boxes info from text file in the kaist dataset format.
"""
filename = os.path.join(self._data_path, self._image_set, 'annotations', index + '.txt')
# print ('Loading: {}'.format(filename))
with open(filename) as f:
lines = f.readlines()[1:]
num_objs = len(lines)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
seg_areas = np.zeros((num_objs), dtype=np.float32)
# Load object bounding boxes into a data frame.
ix = 0
for obj in lines:
# Make pixel indexes 0-based
info = obj.split()
# jam
if self._image_set.find("train") != -1:
if info[0] == "person":
x1 = float(info[1])
y1 = float(info[2])
x2 = x1 + float(info[3])
y2 = y1 + float(info[4])
assert(x2 >= x1)
assert(y2 >= y1)
cls = self._class_to_ind['pedestrian']
boxes[ix, :] = [max(x1 - 1, 0), max(y1 - 1, 0), min(x2 - 1, 639), min(y2 - 1, 479)]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)
ix = ix + 1
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes': boxes,
'gt_classes': gt_classes,
'gt_overlaps': overlaps,
'flipped': False,
'seg_areas': seg_areas}
def _write_voc_results_file(self, all_boxes):
use_salt = self.config['use_salt']
comp_id = 'comp4'
if use_salt:
comp_id += '-{}'.format(os.getpid())
# VOCdevkit/results/VOC2007/Main/comp4-44503_det_test_aeroplane.txt
path = os.path.join(self._devkit_path, 'results', 'VOC', 'Main', comp_id + '_')
for cls_ind, cls in enumerate(self.classes):
if cls == '__background__':
continue
print ('Writing {} VOC results file'.format(cls))
filename = path + 'det_' + self._image_set + '_' + cls + '.txt'
with open(filename, 'wt') as f:
for im_ind, index in enumerate(self.image_index):
dets = all_boxes[cls_ind][im_ind]
if dets == []:
continue
# the VOCdevkit expects 1-based indices
for k in xrange(dets.shape[0]):
f.write('{:s} {:.3f} {:.1f} {:.1f} {:.1f} {:.1f}\n'.
format(index, dets[k, -1],
dets[k, 0] + 1, dets[k, 1] + 1,
dets[k, 2] + 1, dets[k, 3] + 1))
return comp_id
def _do_matlab_eval(self, comp_id, output_dir='output'):
rm_results = self.config['cleanup']
path = os.path.join(os.path.dirname(__file__),
'VOCdevkit-matlab-wrapper')
cmd = 'cd {} && '.format(path)
cmd += '{:s} -nodisplay -nodesktop '.format(datasets.MATLAB)
cmd += '-r "dbstop if error; '
cmd += 'voc_eval(\'{:s}\',\'{:s}\',\'{:s}\',\'{:s}\',{:d}); quit;"' \
.format(self._devkit_path, comp_id,
self._image_set, output_dir, int(rm_results))
print('Running:\n{}'.format(cmd))
status = subprocess.call(cmd, shell=True)
def evaluate_detections(self, all_boxes, output_dir):
comp_id = self._write_voc_results_file(all_boxes)
self._do_matlab_eval(comp_id, output_dir)
def competition_mode(self, on):
if on:
self.config['use_salt'] = False
self.config['cleanup'] = False
else:
self.config['use_salt'] = True
self.config['cleanup'] = True
if __name__ == '__main__':
d = datasets.kaist('train20')
res = d.roidb
from IPython import embed
embed()2018-09-06 13:11:49.699197: W tensorflow/core/framework/op_kernel.cc:1263] Invalid argument: ValueError: attempt to get argmax of an empty sequence
Traceback (most recent call last):
File "/home/ramsey/.local/lib/python3.5/site-packages/tensorflow/python/ops/script_ops.py", line 206, in __call__
ret = func(*args)
File "/home/ramsey/tf-faster-rcnn/tools/../lib/layer_utils/anchor_target_layer.py", line 57, in anchor_target_layer
argmax_overlaps = overlaps.argmax(axis=1)
ValueError: attempt to get argmax of an empty sequence这里附上数据文件的组织形式。
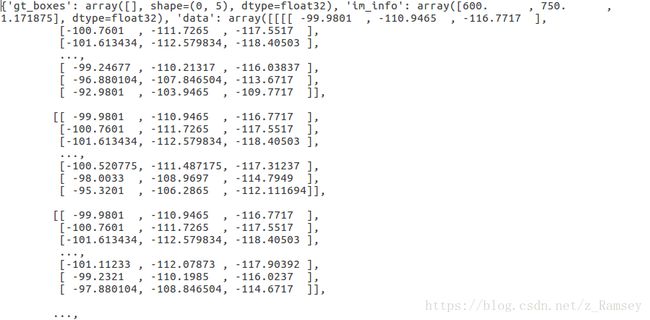
通过输出roidd的部分信息以及计算得到的overlaps,发现,validation roidb的gt_boxes是空的。·(如下图)
最开始没有找到原因,于是注释掉了lib/model/train_val.py中train_model方法的check validation data部分,想先跑通训练。(如下图)
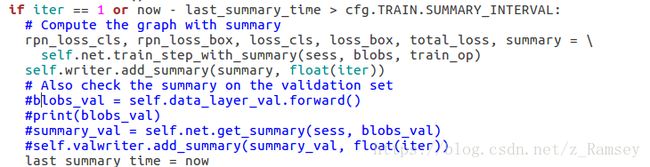
注释掉以后,成功跑通训练。单在迭代一定次数后,又出现了之前的问题:
2018-09-06 13:11:49.699197: W tensorflow/core/framework/op_kernel.cc:1263] Invalid argument: ValueError: attempt to get argmax of an empty sequence
Traceback (most recent call last):
File "/home/ramsey/.local/lib/python3.5/site-packages/tensorflow/python/ops/script_ops.py", line 206, in __call__
ret = func(*args)
File "/home/ramsey/tf-faster-rcnn/tools/../lib/layer_utils/anchor_target_layer.py", line 57, in anchor_target_layer
argmax_overlaps = overlaps.argmax(axis=1)
ValueError: attempt to get argmax of an empty sequence于是,尝试输出用于training的roidb(是filt 空gt box之后的roidb),发现存在部分roidb的gt_box的四个坐标是0。
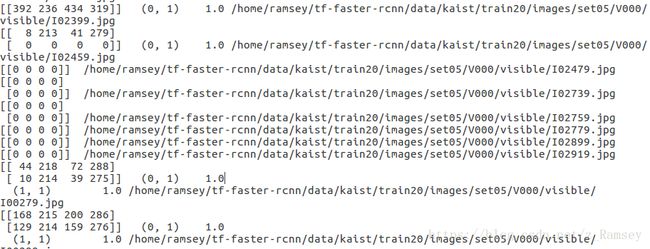
所以,从这里猜想,应该是数据出了问题。
根据输出日志,找到相应的数据例如,上面的I02759.jpg对应的annotation

这个标注很奇怪!因为其他正确的gt_box的annotation都是person.
于是,找到KAIST DATASET的原论文(Multispectral Pedestrian Detection: Benchmark Dataset and Baseline)
其中有提到:”Obviously an individual pedestrian was labelled as a person. Not distinguishable individuals were labeled as people. People riding a two-wheeled vehicle were labeled as cyclist. In a highly cluttered scene, even human annotators sometimes cannot clearly determine whether a human shaped object is a pedestrian or not. This object is labeled as person? an it is ignored in the validation“
所以,KAIST 数据集的annotation不光只有person,还有cyclist, person? people。
而在kaist_rgb.py中,load_annotation函数,只读取了annotation是person的数据,但在创建box的numy的时候,又根据的是读取的数据的行数:boxes = np.zeros((num_objs, 4), dtype=np.uint16), 所以导致部分gt_boxes的存在但四个坐标都是0. 这样是为什么明明有filter_roidb函数,但仍然出错的原因。因为tf_faster_rcnn的filter_roidb(roidb)函数只能去掉gt_box为空的roidb,不能去掉gt_box的四个坐标都为0的roidb
def _load_revised_annotation(self, index):
"""
Load image and bounding boxes info from text file in the kaist dataset format.
"""
filename = os.path.join(self._data_path, self._image_set, 'annotations', index + '.txt')
# print ('Loading: {}'.format(filename))
with open(filename) as f:
lines = f.readlines()[1:]
num_objs = len(lines)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
seg_areas = np.zeros((num_objs), dtype=np.float32)
# Load object bounding boxes into a data frame.
ix = 0
for obj in lines:
# Make pixel indexes 0-based
info = obj.split()
# jam
if self._image_set.find("train") != -1:
if info[0] == "person":
x1 = float(info[1])
y1 = float(info[2])
x2 = x1 + float(info[3])
y2 = y1 + float(info[4])
assert(x2 >= x1)
assert(y2 >= y1)
cls = self._class_to_ind['pedestrian']
boxes[ix, :] = [max(x1 - 1, 0), max(y1 - 1, 0), min(x2 - 1, 639), min(y2 - 1, 479)]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)
ix = ix + 1
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes': boxes,
'gt_classes': gt_classes,
'gt_overlaps': overlaps,
'flipped': False,
'seg_areas': seg_areas}
所以,现在修改_load_revised_annotation(self, index)函数,下面是修改之后的,(就简单的把上述的person,person?people cyclist都认为是pedestrian)
def _load_revised_annotation(self, index):
"""
Load image and bounding boxes info from text file in the kaist dataset format.
"""
filename = os.path.join(self._data_path, self._image_set, 'annotations', index + '.txt')
# print ('Loading: {}'.format(filename))
with open(filename) as f:
lines = f.readlines()[1:]
num_objs = len(lines)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
seg_areas = np.zeros((num_objs), dtype=np.float32)
# Load object bounding boxes into a data frame.
ix = 0
for obj in lines:
# Make pixel indexes 0-based
info = obj.split()
# jam
#if self._image_set.find("train") != -1:
# if info[0] == "person":
x1 = float(info[1])
y1 = float(info[2])
x2 = x1 + float(info[3])
y2 = y1 + float(info[4])
assert(x2 >= x1)
assert(y2 >= y1)
cls = self._class_to_ind['pedestrian']
boxes[ix, :] = [max(x1 - 1, 0), max(y1 - 1, 0), min(x2 - 1, 639), min(y2 - 1, 479)]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)
ix = ix + 1
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes': boxes,
'gt_classes': gt_classes,
'gt_overlaps': overlaps,
'flipped': False,
'seg_areas': seg_areas}
注意,要删除原来生成的 cache里的文件
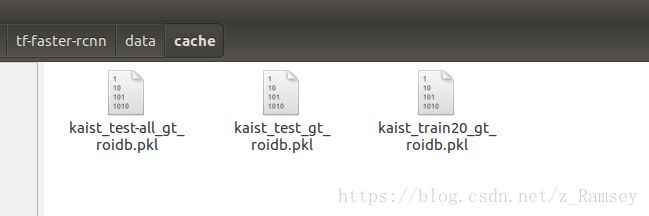
否则还是和之前一样。
这样就终于训练成功了。