吴恩达【深度学习工程师】学习笔记(四)
吴恩达【深度学习工程师】专项课程包含以下五门课程:
1、神经网络和深度学习;
2、改善深层神经网络:超参数调试、正则化以及优化;
3、结构化机器学习项目;
4、卷积神经网络;
5、序列模型。
今天介绍《神经网络与深度学习》系列第四讲:浅层(shallow)神经网络。
主要内容:1、描述神经网络的结构;
2、以计算图的方式推导神经网络的前向传播;
3、详细介绍了不同的激活函数;
4、介绍了神经网络的反向传播过程以及各个参数的求导细节;
5、介绍了权重初始化。
1、神经网络概述
仅含一个隐藏层的神经网络就是浅层神经网络。
神经网络的结构与逻辑回归类似,稍微不同的是,浅层神经网络比逻辑回归多了一层,其中,中间那层被称为隐藏层。因此,前向传播过程分为两层,第一层是输入层到隐藏层,用上标[1]来表示:
第二层是隐藏层到输出层,用上标[2]来表示:
ps:方括号上标[i]表示当前所处的层数,圆括号上标(i)表示第i个样本。
反向传播过程也分成两层,第一层是输出层到隐藏层,第二层是隐藏层到输入层。
结构上分成三层:输入层(Input layer),隐藏层(Hidden layer)和输出层(Output layer)。
2、计算神经网络的输出
逻辑回归的正向计算可以分解成计算z和a的两部分:
对于两层神经网络,从输入层到隐藏层对应一次逻辑回归运算;从隐藏层到输出层对应一次逻辑回归运算。
从隐藏层到输出层的计算公式为:
其中a[1]为:
引入向量化运算后,上述表达式变为:
ps:W[1]的维度是(4,3),b[1]的维度是(4,1),W[2]的维度是(1,4),b[2]的维度是(1,1)。
对于m个训练样本,我们使用向量化的方式来运算:
ps:Z[1]的维度是(4,m),A[1]的维度是(4,m),Z[2]的维度是(1,m), A [2] 的维度是(1,m)。
矩阵的行表示神经元个数,矩阵的列表示样本数目m。
3、激活函数
以下是几个常用的激活函数:
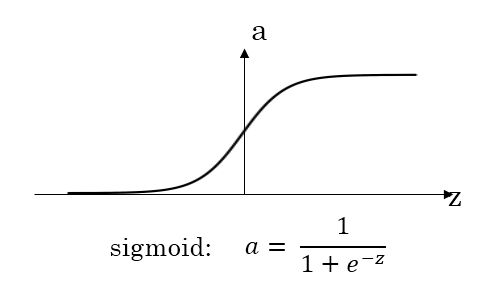
- sigmoid函数
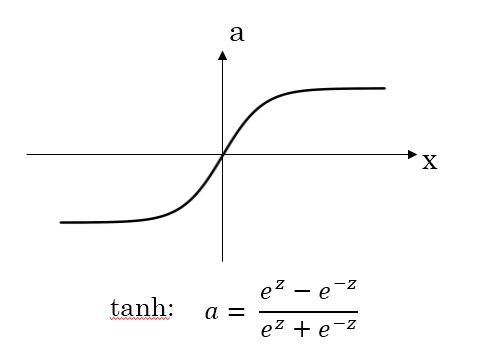
- tanh函数
- ReLU函数
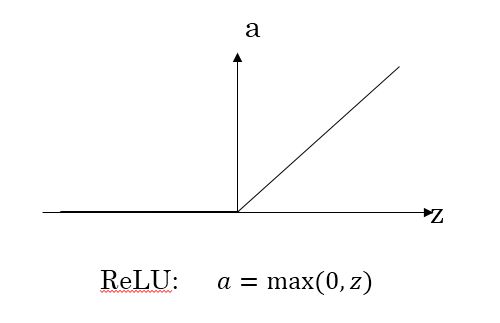
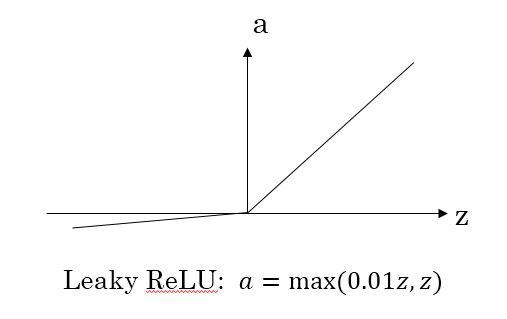
- Leaky ReLU函数
比较sigmoid函数和tanh函数:
1)、对于隐藏层的激活函数,tanh函数要比sigmoid函数表现更好一些。因为tanh函数的取值范围在[-1, 1]之间,隐藏层的输出被限定在[-1, 1]之间,可以看成是在0值附近分布,均值为0。这样从隐藏层到输出层,数据起到了归一化(均值为0)的效果;
2)、对于输出层的激活函数,因为二分类问题的输出取值为{0, 1},所以一般会选择sigmoid作为激活函数。
sigmoid函数和tanh函数都有一个问题,就是当|z|很大的时候,激活函数的梯度接近0。因此,在这个区域内,梯度下降算法会运行得比较慢。
ReLU激活函数在z大于零时梯度始终为1,在z小于零时梯度始终为0。z等于零时的梯度可以当成1也可以当成0,实际应用中并不影响。对于隐藏层,选择ReLU作为激活函数能够保证z大于零时梯度始终为1,从而提高神经网络梯度下降算法运算速度。但当z小于零时,存在梯度为0的问题,在实际应用中,这个影响不是很大。
为了避免这个问题,出现了Leaky ReLU激活函数,能够保证z小于零是梯度不为0。
激活函数不能全部使用线性函数,原因是:
假设所有的激活函数都是线性的,为了简化计算,我们直接令激活函数g(z)=z,即a=z。那么,浅层神经网络的各层输出为:
我们对上式中a[2]进行化简计算:
经过推导我们发现a[2]仍是输入变量x的线性组合。
这表明,使用神经网络与直接使用线性模型的效果并没有什么两样。隐藏层的作用就消失了。
sigmoid函数的导数:
tanh函数的导数:
ReLU函数的导数:
Leaky ReLU函数的导数:
4、梯度计算
神经网络中如何进行梯度计算?
上面这个浅层神经网络,包含的参数为W[1],b[1],W[2],b[2]。令输入层的特征向量个数nx=n[0],隐藏层神经元个数为n[1],输出层神经元个数为n[2]=1。则W[1]的维度为(n[1],n[0]),b[1]的维度为(n[1],1),W[2]的维度为(n[2],n[1]),b[2]的维度为(n[2],1)。
该神经网络前向传播过程为:
其中,g(⋅)表示激活函数。
反向传播是计算导数(梯度)的过程,这里先列出来Cost function对各个参数的梯度:
我们使用计算图的方式来推导反向传播过程:
含一个隐藏层神经网络中,m个样本的前向传播和反向传播过程分别包含了6个表达式,其向量化形式如下图所示:

5、随机初始化
神经网络模型中的参数权重W是不能全部初始化为零的。
举个简单的例子,一个浅层神经网络包含两个输入,隐藏层包含两个神经元。如果权重W[1]和W[2]都初始化为零,即:
这样使得隐藏层第一个神经元的输出等于第二个神经元的输出,即a[1]1=a[1]2。经过推导得到dz[1]1=dz[1]2,以及dW[1]1=dW[1]2。因此,这样的结果是隐藏层两个神经元对应的权重行向量W[1]1和W[1]2每次迭代更新都会得到完全相同的结果,W[1]1始终等于W[1]2,完全对称。这样隐藏层设置多个神经元就没有任何意义了。
因此我们将W进行随机初始化(b可初始化为零)。
python里可以使用如下语句进行W和b的初始化:
W_1 = np.random.randn((2,2))*0.01
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0- 1
- 2
- 3
- 4
这里将W[1]1和W[1]2乘以0.01的目的是使得权重W初始化比较小的值。因为使用sigmoid函数或者tanh函数作为激活函数的时候,W比较小,得到的|z|也比较小,导致该区域梯度比较大,从而加速梯度下降算法 。