Elasticsearch实现原理分析-2
介绍
第1部分分析了Elasticsearch基本的读、写、更新、存储等方面的实现原理,本文档主要介绍Elasticsearch如何实现分布式系统的三个特性(consensus, concurrency和consistency),以及分片的内部概念,例如:translog(Write Ahead Log - WAL)和Lucene segments。
本章主要包括以下内容:
- Consensus: 脑裂(split-brain)和quorum机制
- Concurrency(并发)
- Consistency(一致性):确保一致的写入和读取
- Translog (Write Ahead Log — WAL)
- Lucene segments
Consensus(脑裂和quorum机制)
Consensus是一个分布式系统的基本挑战。它要求分布式系统中的所有的进程/节点,对给定的数据的值/状态达成一致。有很多Consensus的算法,如Raft,Paxos等。这些算法在数学上被证明是有效的,但Elasticsearch实现了它自己的consensus系统(zen discovery),是因为Shay Banon(Elasticsearch的创建者)所描述的原因。
zen discovery模块有两个部分:
- Ping:执行该过程的节点,用来发现对方。
- Unicast:该模块包含一个主机名列表,用于控制要ping哪个节点。
Elasticsearch是一种点对点(peer-to-peer)系统,其中所有节点彼此通信,并且只有一个活动的主节点,该节点可以更新和控制群集状态和操作。新的Elasticsearch集群将会进行一次选举,该选举作为ping进程的一部分在节点中运行。在所有有资格选举的节点中,其中有一个节点被选举为主节点(master node),其他节点加入该主节点。
默认的ping_interval为1秒,ping_timeout为3秒。当节点加入时,他们会发生一个join的请求给master主机,该请求有一个join_timeout时间,默认是参数ping_timeout的20倍。
若主节点失败,集群中的几点再次开始ping,开始另一次新的选举。如果节点意外地认为主节点发生故障,并且通过其他节点发现主节点,则该ping过程也将有所帮助。
注意:默认情况下,客户端(client)和数据节点不会对选举过程做出贡献。可以通过改变以下参数的设置,这些参数在elasticsearch.yml 文件中:
discovery.zen.master_election.filter_client:False
discovery.zen.master_election.filter_data: False故障检测的过程是这样的:主节点ping所有的节点来检查这些节点是否存活,而所有的节点回ping主节点来汇报他们是存活的。
若使用默认配置,Elasticsearch会遇到脑裂的问题,如果是网络分区,则节点可以认为主节点已经死机,并将其自身选为主节点,从而导致集群具有多个主节点。这样可能导致数据丢失,可能无法正确合并数据。这种情况可以通过将以下属性设置为主合格节点的法定数量来避免:
discovery.zen.minimum_master_nodes = int(# of master eligible nodes/2)+1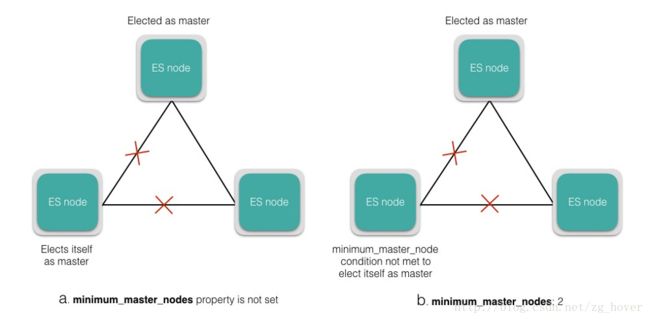
该参数要求法定数量的可参加选举的节点加入新的选举过程来完成新的选举过程,并接受新节点作为新的master节点。这是确保集群稳定性的极其重要的参数,如果集群大小发生变化,可以进行动态更新。图a和b分别显示了在minimum_master_nodes属性被设置,和未被设置的两种情况。
注意:对于生产环境的集群,建议有3个专用主节点,在任何给定的时间点只有一个处于活动状态,其他的节点不服务任何客户请求。
Concurrency(并发控制)
Elasticsearch是一个分布式系统,支持并发请求。当创建/更新/删除请求命中主分片时,它同时发送到副本分片,但是这些请求到达的顺序是不确定的。在这种情况下,Elasticsearch使用乐观并发控制(optimistic concurrency control)来确保文档的较新版本不会被旧版本覆盖。
每个被索引的文档都会有一个版本号,每次文档改变时,该版本号就会增加。使用版本号可以确保对文档的改变是顺序进行的。为确保我们的应用程序中的更新不会导致数据丢失,Elasticsearch的API允许您指定,更改应该应用到目前哪一个版本号。如果请求中指定的版本号,早于分片中存在的版本号,则请求失败,这意味着该文档已被其他进程更新。
如何处理失败的请求?可以在应用程序级别进行控制。还有其他锁定选项可用,您可以在这里阅读。
当我们向Elasticsearch发送并发请求时,下一个问题是 - 我们如何使这些请求保持一致?现在要回答 CAP原则,还不是太清晰,这是接下来要讨论的问题。
但是,我们将回顾如何使用Elasticsearch实现一致的写入和读取。
Consistency (确保一致的写和读)
对于写操作,Elasticsearch支持与大多数其他数据库不同的一致性级别,它允许初步检查以查看有多少个分片可用于允许写入。可用的选项是:quorum的可设置的值为:one和all。默认情况下,它被设置为:quorum,这意味着只有当大多数分片可用时,才允许写入操作。在大部分分片可用的情况下,由于某种原因,写入复制副本分片失败仍然可能发生,在这种情况下,副本被认为是错误的,该分片将在不同的节点上进行重建。
对于读操作,新文档在刷新间隔时间后才能用于搜索。为了确保搜索结果来自最新版本的文档,可以将复制(replication)设置为sync(默认值),当在主分片和副本分片的写操作都完成后,写操作才返回。在这种情况下,来自任何分片的搜索请求将从文档的最新版本返回结果。
即使你的应用程序为了更快的indexing而设置:replication=async,也可以使用_preference参数,可以为了搜素请求把它设置为primary。这样,查询主要分片就是搜索请求,并确保结果将来自最新版本的文档。
当我们了解Elasticsearch如何处理consensus,并发性和一致性时,我们来看看分片内部的一些重要概念,这些概念导致了Elasticsearch作为分布式搜索引擎的某些特征。
Translog
自从开发关系数据库以来,数据库世界中一直存在着write ahead log(WAL)或事务日志(translog)的概念。Translog在发生故障的情况下确保数据的完整性,其基本原则是,在数据的实际更改提交到磁盘之前必须先记录并提交预期的更改。
当新文档被索引或旧文档被更新时,Lucene索引会更改,这些更改将被提交到磁盘以进行持久化。每次写请求之后进行持久化操作是一个非常消耗性能的操作,它通过一次持久化多个修改到磁盘的方式运行(译注:也就是批量写入)。正如我们在之前的一篇博客中描述的那样,默认情况下每30分钟执行一次flush操作(Lucene commit),或者当translog变得太大(默认为512MB)时)。在这种情况下,有可能失去两次Lucene提交之间的所有变化。为了避免这个问题,Elasticsearch使用translog。所有的索引/删除/更新操作都先被写入translog,并且在每个索引/删除/更新操作之后(或者每默认默认为5秒),translog都被fsync’s,以确保更改被持久化。在主文件和副本分片上的translog被fsync’ed后,客户端都会收到写入确认。
在两次Lucene提交或重新启动之间出现硬件故障的情况下,会在最后一次Lucene提交之前重播Translog以从任何丢失的更改中恢复,并将所有更改应用于索引。
建议在重新启动Elasticsearch实例之前显式刷新translog,因为启动将更快,因为要重播的translog将为空。POST / _all / _flush命令可用于刷新集群中的所有索引。
使用translog刷新操作,文件系统缓存中的段将提交到磁盘,以使索引持续更改。
现在我们来看看Lucene segment:
Lucene Segments
Lucene索引由多个片段(segment)组成,片段本身是完全功能的倒排索引。片段是不可变的,这允许Lucene增量地向索引添加新文档,而无需从头开始重建索引。对于每个搜索请求,搜所有段都会被搜素,每个段消耗CPU周期,文件句柄和内存。这意味着分段数越多,搜索性能就越低。
为了解决这个问题,Elasticsearch将小段合并成一个更大的段(如下图所示),将新的合并段提交到磁盘,并删除旧的较小的段。

合并操作将会自动发生在后台,而不会中断索引或搜索。由于分段合并可能会浪费资源并影响搜索性能,因此Elasticsearch会限制合并过程的资源使用,以获得足够的资源进行搜索。
参考文档
- Anatomy of an Elasticsearch Cluster: Part II