HashTable和ConcurrentHashMap是如何实现线程安全的?
在说HashTable和ConcurrentHashMap线程安全问题之前我们先看一段代码:
public class Safe {
private int count = 0;
private void add(){
for(int i=0 ; i<100 ; i++){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
}
}
public static void main(String[] args) throws InterruptedException {
Safe safe = new Safe();
new Thread(()->safe.add()).start();
new Thread(()->safe.add()).start();
Thread.sleep(1000);
System.out.println(safe.count);
}
}
类Safe中仅有一个count的成员变量初始值为0,现在两个线程访问这个Safe对象,对count的值进行各累加100次。按照正常情况算出的结果应该为200,但是实际执行的结果却并不是:



可以看到执行的结果很不稳定,有的时候和预期值一样,有的时候却会不一样,这就是多线程下成员变量的线程不安全问题。
那么,我们再将该代码改变一下如下:
public class Safe {
private int count = 0;
private synchronized void add(){
for(int i=0 ; i<100 ; i++){
count++;
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Safe safe = new Safe();
new Thread(()->safe.add()).start();
new Thread(()->safe.add()).start();
Thread.sleep(1000);
System.out.println(safe.count);
}
}
执行结果


在add方法上添加synchronized关键字,将该方法体设为线程同步块,方法体每次只能有一个线程执行,这样就有效的解决了线程安全的问题。
1、HashTable如何实现线程安全
这里我们看一下HashTable在对数据操作的各个方法的源码
1)size()方法

2)isEmpty()方法

3) keys()方法

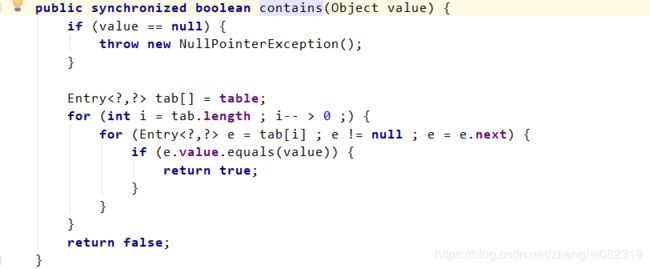
4)contains()方法
5)get(key) 方法

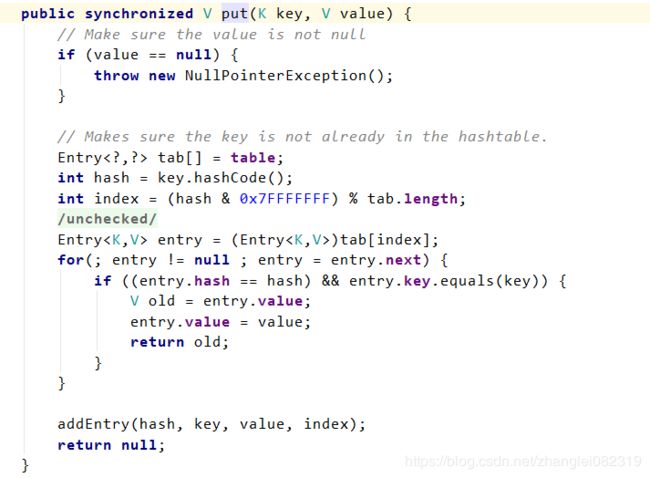
6)put方法
7)clear方法
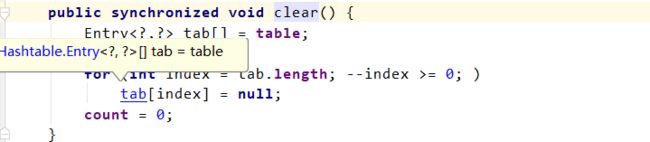
从这些方法中,我们可以看到这些对容器中数据进行操作的方法都被synchronized关键字修饰,和最开始的案例一样,这种jdk自带的内置锁可以使得被synchronized关键字修饰的方法体和代码块一次只能被一个线程执行,也就保证了线程安全的问题。
但是为什么Jdk还会添加ConcurrentHashMap这个线程安全的类呢?
让我们看看HashTable,HashTable本身是个容器,这也就说明了HashTable本身可以不断的放大,试想一下,HashTable如果本身如果存在1000个元素,那么在get()方法中就会将这1000个元素完全锁住,期间其他任何线程都得等待。这样就会造成容器越大,对容器数据操作的效率将越低。
那么,让我们来看看ConcurrentHashMap是如何实现线程安全的,它能实现高效率的线程安全吗?
这里我们就不看ConcurrentHashMap的源码了,简单说说线程安全的原理,其实ConcurrentHashMap实现线程安全也是通过synchronized关键字来控制代码同步来实现的,不同于HashTable的是ConcurrentHashMap在线程同步上更加细分化,它不会像HashTable那样一把包揽的将所有数据都锁住。
采用分段锁思路
我们都知道ConcurrentHashMap的底层数据结构实现原理其实和HashMap没什么两样,都是数组+链表+红黑树。那么我们就从HashMap入手,来理解。
具体HashMap的实现原理剖析请看个人博客:https://blog.csdn.net/zhanglei082319/article/details/87872156
怎么将HashMap数据结构使用分段锁的思想进行细分化。在jdk1.7及以前,是这样实现的:
比如容器HashMap中存在1000个元素,各个元素都放置到HashMap数组的链表或者红黑数中,最后得到的数组大小可能只有128,ConcurrentHashMap会根据这128个数组,对其分段,比如以16个数组为一段,可以分为8段。在实际获取元素,添加元素时,会根据元素的索引(如何获取元素在HashMap数组中的索引请看https://blog.csdn.net/zhanglei082319/article/details/87872156)找到该元素所处的段位,然后只将该段位锁住,并不影响其他段位的数据操作。这样如果按照HashTable的效率为基本单位来计算,ConcurrentHashMap在jdk1.7及以前的效率会提高8倍,当然数据量越大,提高的效率将越多。 
jdk1.8后,ConcurrentHashMap依旧使用分段锁的思想来实现线程安全,不同于jdk1.7及以前,jdk1.8将锁的粒度更加细分化,以每个数组索引为锁来进行实现。比如HashMap数组中长度有128,那么就会存在128个锁将每个索引锁住。这样相比于jdk1.7之前在效率上有了很大的改进。
总结一下
HashTable和ConcurrentHashMap都是线程安全的容器。
HashTable: 线程安全,效率和容器的大小成正比。容器数据量越大,效率越慢
ConcurrentHashMap: 线程安全,效率相对于不如HashMap,但是和HashTable相比,效率得到很大的提升。
综合考虑,如果使用线程安全容器,推荐使用ConcurrentHashMap