如何监控ES的性能
作者:石文
时间:2018-07-03
本部分来自一篇外文文章,这篇外文文章包括如下四部分。
Part1:如何监控ES的性能
What is Elasticsearch?
*
什么是Elasticsearch?*
Elasticsearch is an open source distributed document store and search engine that stores and retrieves data structures in near real-time. Developed by Shay Banon and released in 2010, it relies heavily on Apache Lucene, a full-text search engine written in Java.
Elasticsearch是一种开源分布式文档存储和搜索引擎,可以(近实时)存储和检索数据结构。由Shay Banon开发,2010年进行了第一次发布。ES依赖于Apache Lucene,用Java编写的全文搜索引擎。
Elasticsearch represents data in the form of structured JSON documents, and makes full-text search accessible via RESTful API and web clients for languages like PHP, Python, and Ruby. It’s also elastic in the sense that it’s easy to scale horizontally—simply add more nodes to distribute the load. Today, many companies, including Wikipedia, eBay, GitHub, and Datadog, use it to store, search, and analyze large amounts of data on the fly.
Elasticsearch以JSON形式的结构化文档显示数据,通过RESTful API和web客户端的方式实现可以使用PHP、Python和Ruby等语言的行全文搜索。它可以容易的进行弹性扩展——只需添加更多的节点来分配负载。如今,许多公司——包括维基百科、eBay、GitHub和Datadog,都使用它进行动态地存储、搜索和分析数据。
The elements of Elasticsearch
ES的组成
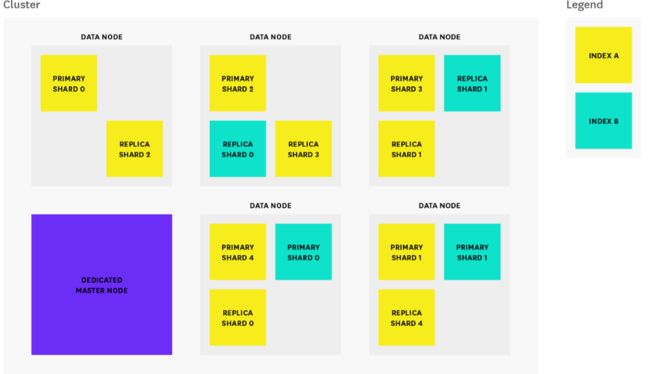
Before we start exploring performance metrics, let’s examine what makes Elasticsearch work. In Elasticsearch, a cluster is made up of one or more nodes, as illustrated below:
在研究ES的性能指标之前,我们来看一下ES是如何工作的。ES集群由一个或多个节点组成,如下图所示:
Each node is a single running instance of Elasticsearch, and its elasticsearch.yml configuration file designates which cluster it belongs to (cluster.name) and what type of node it can be. Any property (including cluster name) set in the configuration file can also be specified via command line argument. The cluster in the diagram above consists of one dedicated master node and five data nodes.
每个节点都是ES的一个实例(node),每个节点的elasticsearch.yml配置文件指定属于哪个集群(cluster.name配置项),以及这个节点是什么类型的节点。配置文件中设置的任何属性(包括cluster.name)也可以通过命令行参数指定。上图中的ES集群由一个专用master节点和五个data节点组成。
The three most common types of nodes in Elasticsearch are:
ES的3个最主要的节点类型如下:
-
Master-eligible nodes : By default, every node is master-eligible unless otherwise specified. Each cluster automatically elects a master node from all of the master-eligible nodes. In the event that the current master node experiences a failure (such as a power outage, hardware failure, or an out-of-memory error), master-eligible nodes elect a new master. The master node is responsible for coordinating cluster tasks like distributing shards across nodes, and creating and deleting indices. Any master-eligible node is also able to function as a data node. However, in larger clusters, users may launch dedicated master-eligible nodes that do not store any data (by adding node.data: false to the config file), in order to improve reliability. In high-usage environments, moving the master role away from data nodes helps ensure that there will always be enough resources allocated to tasks that only master-eligible nodes can handle.
-
Master候选节点:默认情况下,每个节点都可以是master候选节点,除非在配置文件中进行限制。每个集群自动地从master候选节点中选择一个master节点。如果当前master节点出现故障(例如:断电、硬件故障或内存不足等),其他的master候选节点将选择一个新的master节点。master节点负责协调集群任务,如跨节点分发分片、创建和删除索引。任何master候选节点也可以作为data节点。但是,在较大集群中,用户可以p配置专门的master候选节点以提高集群可靠性,这些节点不存储任何数据(通过在配置文件中配置node.data:false)。在高可用的环境中,将master角色从data节点中独立出来有助于确保足够的资源分配给master节点以便能够快速的处理集群任务。
-
Data nodes : By default, every node is a data node that stores data in the form of shards (more about that in the section below) and performs actions related to indexing, searching, and aggregating data. In larger clusters, you may choose to create dedicated data nodes by adding node.master: false to the config file, ensuring that these nodes have enough resources to handle data-related requests without the additional workload of cluster-related administrative tasks.
-
数据节点:默认情况下,每个节点都可以存储数据shard作为数据节点(更多的信息在如下小节中),并执行索引、搜索和聚合数据的相关操作。在较大集群中,我们可以在配置文件中添加node.master:fale来创建专门的数据节点,以确保这些节点拥有足够的资源来处理与数据相关的请求,而无需处理与集群相关的管理任务而增加工作负载。
-
Client nodes : If you set node.master and node.data to false, you will end up with a client node, which is designed to act as a load balancer that helps route indexing and search requests. Client nodes help shoulder some of the search workload so that data and master-eligible nodes can focus on their core tasks. Depending on your use case, client nodes may not be necessary because data nodes are able to handle request routing on their own. However, adding client nodes to your cluster makes sense if your search/index workload is heavy enough to benefit from having dedicated client nodes to help route requests.
-
协调节点 :如果将node.master和node.data设置为false,最终会得到一个客户端节点,该节点被设计为负载均衡器用于帮助路由索引和搜索请求。客户端节点帮助集群分担一些搜索工作负载,以便数据节点和master节点可以集中资源处理其核心的任务。根据业务的不同,客户端节点也可能不需要,因为数据节点本身能够处理客户端请求。但是,如果集群的搜索和索引工作负载足够大,使用专用的client节点来处理路由请求是很有意义的。
How Elasticsearch organizes data
ES如何组织数据的
In Elasticsearch, related data is often stored in the same index, which can be thought of as the equivalent of a logical wrapper of configuration. Each index contains a set of related documents in JSON format. Elasticsearch’s secret sauce for full-text search is Lucene’s inverted index. When a document is indexed, Elasticsearch automatically creates an inverted index for each field; the inverted index maps terms to the documents that contain those terms.
在ES中,相关数据通常要存储在同一个索引中,这种方式等价于按照逻辑关系进行配置索引。每个索引包含一系列JSON格式的文档,逻辑上相关。ES的秘密武器是基于Lucene的反向索引。当一个文档被写入某个索引时,ES会自动为每个字段创建一个反向索引;反向索引将字段映射到包含这些术语的文档中。
An index is stored across one or more primary shards, and zero or more replica shards, and each shard is a complete instance of Lucene, like a mini search engine.
索引存储在一个或多个主分片中,并且为了保证数据的完整性,可以通过配置设置分片可以存储在零个或多个副本中。对于每个分片来说,它都是Lucene的一个完整实例,就像一个迷你的搜索引擎一样。
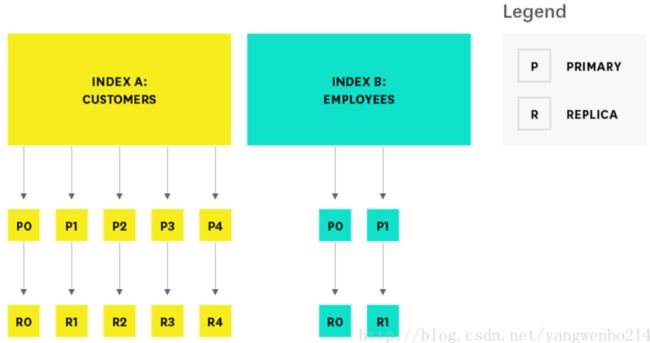
When creating an index, you can specify the number of primary shards, as well as the number of replicas per primary. The defaults are five primary shards per index, and one replica per primary. The number of primary shards cannot be changed once an index has been created, so choose carefully, or you will likely need to reindex later on. The number of replicas can be updated later on as needed. To protect against data loss, the master node ensures that each replica shard is not allocated to the same node as its primary shard.
用户创建索引可以指定主分片数量和副本数量。默认值为每个索引5个主分片,每个主分片一个副本。索引创建完成后,主分片数量不能更改,所以请谨慎选择,否则可能需要在后期重新建立此索引(reindex)。副本的数量可以根据需要随时更改。为了防止数据丢失,ES确保副本分片不会与它的主分片在相同的节点上。
Key Elasticsearch performance metrics to monitor
ES的核心性能指标的监控
Elasticsearch provides plenty of metrics that can help you detect signs of trouble and take action when you’re faced with problems like unreliable nodes, out-of-memory errors, and long garbage collection times. A few key areas to monitor are:
ES提供了许多指标来帮助你发现集群的的问题来采取行动,比如说发现集群中不可用的节点、内存不足的节点和垃圾收集超时等问题的节点。给出的需要监测的几个关键领域如下:
-
Search and indexing performance
-
Memory and garbage collection
-
Host-level system and network metrics
-
Cluster health and node availability
-
Resource saturation and errors
-
查询和索引性能
-
内存和垃圾收集
-
机器级别的系统和网络性能
-
集群监控和节点可用性
-
资源饱和度和错误
This article references metric terminology from our Monitoring 101 series, which provides a framework for metric collection and alerting.
本文引用了监视101系列中的度量术语,该文章为指标收集和报警提供了一个框架。
All of these metrics are accessible via Elasticsearch’s API as well as single-purpose monitoring tools like Elastic’s Marvel and universal monitoring services like Datadog. For details on how to collect these metrics using all of these methods, see Part 2 of this series.
以上指标都可以通过ES的API以及ES专用监控工具(如:ES的Marvel)和通用监控服务(如Datadog)来获取。有关如何使用所有这些方法收集这些度量的详细信息,请参见本系列的第2部分。
Search performance metrics
查询性能指标
Search requests are one of the two main request types in Elasticsearch, along with index requests. These requests are somewhat akin to read and write requests, respectively, in a traditional database system. Elasticsearch provides metrics that correspond to the two main phases of the search process (query and fetch). The diagrams below illustrate the path of a search request from start to finish.
查询请求是ES的两个主要请求类型之一,另一个是索引请求。在传统的数据库系统中,这些请求在某种程度上类似于读写。ES提供了与查询过程有关的两个主要阶段(查询和获取)的相对应的指标。下面的图表说明了查询请求从开始到结束的数据流向。
1.客户端向Node2发送查询请求
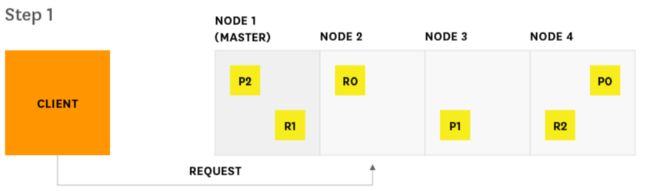
2.Node2(客串client节点)将查询请求发送到索引中的每个分片(包括分片副本)
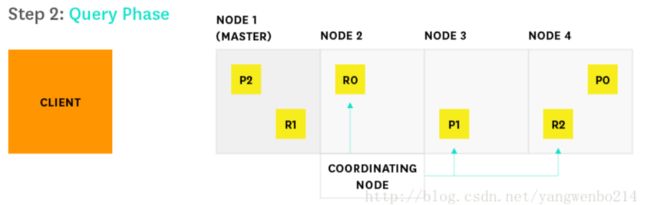
3…每个分片在本地执行查询并将结果返回给Node 2
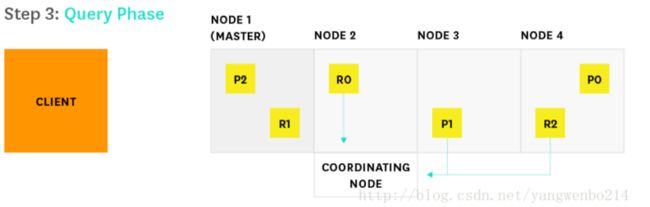
4…Node 2发现需要获取哪些文档,并向相关的分片发送多个GET请求
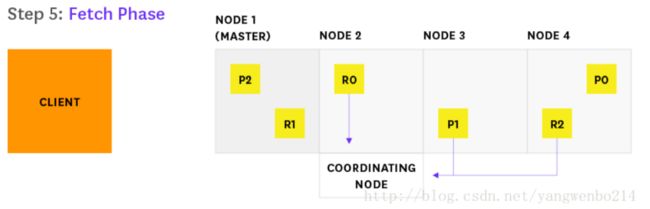
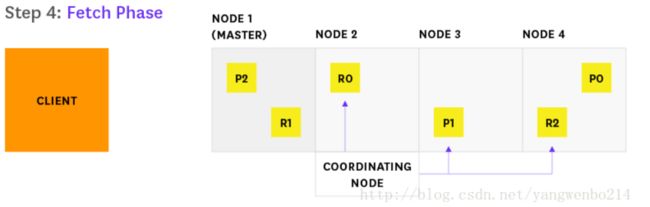
5.Node 2发现需要获取哪些文档,并向相关的分片发送多个GET请求
6.Node 2将搜索结果交付给客户端
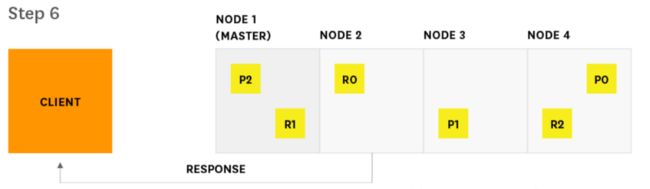
If you are using Elasticsearch mainly for search, or if search is a customer-facing feature that is key to your organization, you should monitor query latency and take action if it surpasses a threshold. It’s important to monitor relevant metrics about queries and fetches that can help you determine how your searches perform over time. For example, you may want to track spikes and long-term increases in query requests, so that you can be prepared to tweak your configuration to optimize for better performance and reliability.
如果你主要使用的是ES的搜索功能,或者是搜索主要是面向客户的,那么对你的ES来说,搜索指标是集群关键的指标,你应该监控查询的延迟,并在它超过阈值后采取必要的措施。监视搜索过程中查询和获取两个阶段的相关度量是非常重要的,这些指标可以帮助确定搜索命令的执行情况。例如,你可能希望跟踪查询请求的峰值和请求的长期增长来调整集群的配置,以便优化集群性能和可靠性。
| Metric description | Name | Metric type |
|---|---|---|
| Total number of queries | indices.search.query_total | Work: Throughput |
| Total time spent on queries | Total time spent on queries | Work: Throughput |
| Number of queries currently in progress | Total time spent on queries | Work: Throughput |
| Total number of fetches | indices.search.fetch_total | Work: Throughput |
| Total time spent on fetches | indices.search.fetch_time_in_millis | Work: Throughput |
| Number of fetches currently in progress | indices.search.fetch_current | Work: Throughput |
| 指标描述 | 指标 | 指标类型 |
|---|---|---|
| 查询总数量 | indices.search.query_total | Work: Throughput |
| 查询总时间 | Total time spent on queries | Work: Throughput |
| 正在查询的数量 | Total time spent on queries | Work: Throughput |
| 总得fatch的数量 | indices.search.fetch_total | Work: Throughput |
| fatch的总时间 | indices.search.fetch_time_in_millis | Work: Throughput |
| 正在进行fatch的数量 | indices.search.fetch_current | Work: Throughput |
Search performance metrics to watch
搜索性能指标
Query load : Monitoring the number of queries currently in progress can give you a rough idea of how many requests your cluster is dealing with at any particular moment in time. Consider alerting on unusual spikes or dips that may point to underlying problems. You may also want to monitor the size of the search thread pool queue, which we will explain in further detail later on in this post.
查询负载 :监控当前正在进行查询的数量可以让你了解集群在任何特定时刻处理请求的数量概况。为了发现潜在问题,我们需要配置阈值,在查询负载达到异常峰值或低谷时发出警报。我们还希望监视搜索线程池队列的大小,稍后我们将在本文中进一步做详细说明。
Query latency : Though Elasticsearch does not explicitly provide this metric, monitoring tools can help you use the available metrics to calculate the average query latency by sampling the total number of queries and the total elapsed time at regular intervals. Set an alert if latency exceeds a threshold, and if it fires, look for potential resource bottlenecks, or investigate whether you need to optimize your queries.
查询延迟 :虽然ES没有明确地提供这个指标,但是监视工具可以提供给你可用的指标来计算平均查询延迟,方法是定期抽样查询总数和总运行时间。通过设置延迟阈值设置一个警报,如果触发警报,则查找暴露出潜在资源瓶颈,或者我们需要优化搜索性能。
Fetch latency : The second part of the search process, the fetch phase, should typically take much less time than the query phase. If you notice this metric consistently increasing, this could indicate a problem with slow disks, enriching of documents (highlighting relevant text in search results, etc.), or requesting too many results.
获取延迟 :搜索过程的第二部分,即获取阶段,通常来说,这个过程的时间花费要显著小于查询阶段。如果你注意到这个指标在持续增加,这可能暴露了:磁盘速度慢、文档过多(在搜索结果中突出显示相关文本等)或请求过多等。
Indexing performance metrics
索引性能指标
Indexing requests are similar to write requests in a traditional database system. If your Elasticsearch workload is write-heavy, it’s important to monitor and analyze how effectively you are able to update indices with new information. Before we get to the metrics, let’s explore the process by which Elasticsearch updates an index. When new information is added to an index, or existing information is updated or deleted, each shard in the index is updated via two processes: refresh and flush.
索引请求类似于传统数据库系统中的写请求。如果您的ES索引工作量很大,那么监视和分析如何有效地更新索引是十分重要的。在讨论这个指标之前,我们先来研究一下ES更新索引的过程,当新的消息添加到索引中、更新或删除现有信息时,索引中的每个分片都会通过如下两个过程来进行索引的更新refresh 和 flush。
Index refresh
索引refresh
Newly indexed documents are not immediately made available for search. First they are written to an in-memory buffer where they await the next index refresh, which occurs once per second by default. The refresh process creates a new in-memory segment from the contents of the in-memory buffer (making the newly indexed documents searchable), then empties the buffer, as shown below.
最新的索引文档不会立刻被搜索到。首先,它们会被写入内存缓冲区(buffer),并等待下一次索引刷新(refresh),在默认情况下,refresh的过程每秒执行一次。refresh过程创建新的内存段(使新索引的文档可搜索),将内存缓冲区中的内容同步到新的内存段,然后清空缓冲区,如下所示。
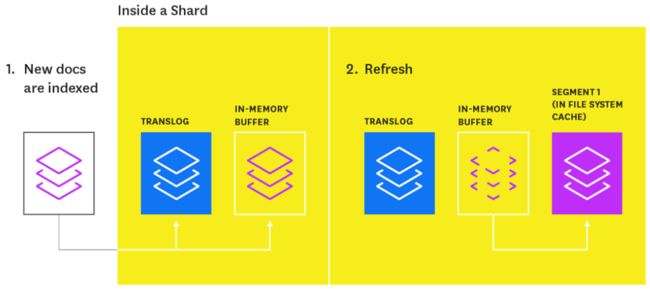
A special segment on segments
一个特殊的段
Shards of an index are composed of multiple segments. The core data structure from Lucene, a segment is essentially a change set for the index. These segments are created with every refresh and subsequently merged together over time in the background to ensure efficient use of resources (each segment uses file handles, memory, and CPU).
索引的分片由多个部分组成。Lucene提供的核心数据结构,段本质上是索引的变更集(a change set)。这些段是在每次刷新时创建的,随后在后台进行合并以确保资源的有效利用(每个段都会使用文件句柄、内存和CPU)。
Segments are mini-inverted indices that map terms to the documents that contain those terms. Every time an index is searched, a primary or replica version of each shard must be searched by, in turn, searching every segment in that shard.
段是一种小型反向索引,它将字段映射到包含这些字段的文档中。每次搜索索引时,必须依次搜索每个分片的主分片本或副本分片,并搜索分片中的每段。
A segment is immutable, so updating a document means:
-
writing the information to a new segment during the refresh process
-
marking the old information as deleted
The old information is eventually deleted when the outdated segment is merged with another segment.
段是不可变的,所以更新文档将意味着:
-
在refresh过程中,新写入的信息将成为一个新的段
-
将旧的信息标记为已删除
当老的段与另一个段合并时,旧的信息才最终被删除。
Index flush
索引flush
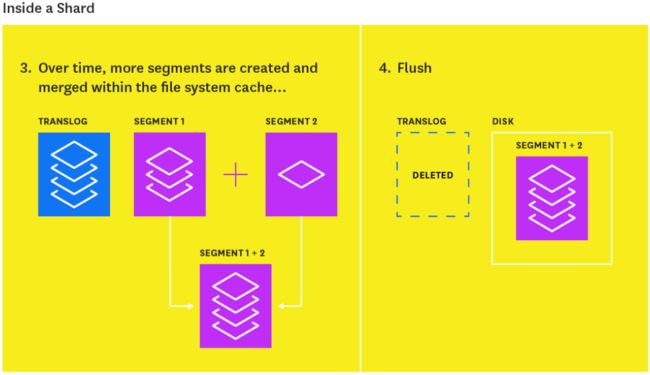
At the same time that newly indexed documents are added to the in-memory buffer, they are also appended to the shard’s translog: a persistent, write-ahead transaction log of operations. Every 30 minutes, or whenever the translog reaches a maximum size (by default, 512MB), a flush is triggered. During a flush, any documents in the in-memory buffer are refreshed (stored on new segments), all in-memory segments are committed to disk, and the translog is cleared.
将索引新增加的文档添加到内存缓冲区的同时,集群还会将这些文档附加到分片的的translog:这是一个持久的、写前事务日志操作。每30分钟,或者当translog达到最大大小(默认值为512MB)时,就会触发一个刷新。在刷新期间,内存缓冲区中的任何文档都被刷新(存储在新段上),所有内存段都被提交到磁盘,translog被清除。
The translog helps prevent data loss in the event that a node fails. It is designed to help a shard recover operations that may otherwise have been lost between flushes. The log is committed to disk every 5 seconds, or upon each successful index, delete, update, or bulk request (whichever occurs first).
translog的作用是防止节点突然不可用时发生数据丢失。它设计的目的是帮助分片进行恢复操作,否则可能会在flush期间造成数据丢失。这个日志每5秒提交一次磁盘,或每次成功的索引后、删除操作、更新或批量请求操作(以先发生的为准)后执行一次磁盘提交。
The flush process is illustrated below:
flush过程如下如所示:
Elasticsearch provides a number of metrics that you can use to assess indexing performance and optimize the way you update your indices.
ES提供了一些指标以便我们使用它们来评估索引性能并对索引的更新进行优化。
| Metric description | Name | Metric type |
|---|---|---|
| Total number of documents indexed | indices.indexing.index_total | Work: Throughput |
| Total time spent indexing documents | indices.indexing.index_time_in_millis | Work: Performance |
| Number of documents currently being indexed | indices.indexing.index_current | Work: Throughput |
| Total number of index refreshes | indices.refresh.total | Work: Throughput |
| Total time spent refreshing | indices indices.refresh.total_time_in_millis | Work: Performance |
| Total number of index flushes to disk | indices.flush.total | Work: Throughput |
| Total time spent on flushing indices to disk | indices.flush.total_time_in_millis | Work: Performance |
| 指标描述 | 指标 | 指标类型 |
|---|---|---|
| 索引的文档总数 | indices.indexing.index_total | Work: Throughput |
| 索引文档的总时间 | indices.indexing.index_time_in_millis | Work: Performance |
| 当前被索引的文档数量 | indices.indexing.index_current | Work: Throughput |
| 索引refresh的总数 | indices.refresh.total | Work: Throughput |
| 索引refresh的总用时 | indices.refresh.total_time_in_millis | Work: Performance |
| 索引flush到磁盘的总数 | indices.flush.total | Work: Throughput |
| 将索引flush到磁盘的总时间 | indices.flush.total_time_in_millis | Work: Performance |
Indexing performance metrics to watch
索引性能指标
Indexing latency : Elasticsearch does not directly expose this particular metric, but monitoring tools can help you calculate the average indexing latency from the available index_total and index_time_in_millis metrics. If you notice the latency increasing, you may be trying to index too many documents at one time (Elasticsearch’s documentation recommends starting with a bulk indexing size of 5 to 15 megabytes and increasing slowly from there).
延迟 :ES并没有这个特定的指标,但监控工具可以帮助你计算可用索引index_total和index_time_in_millis指标的平均延迟。如果你注意到延迟的增加,您可能是一次索引太多的文档了(ES索引文档的bulk操作,建议从5到15兆字节的块大小开始,然后慢慢增加)。
If you are planning to index a lot of documents and you don’t need the new information to be immediately available for search, you can optimize for indexing performance over search performance by decreasing refresh frequency until you are done indexing. The index settings API enables you to temporarily disable the refresh interval:
如果你是对大量的文档进行索引,并且不需要立即就可以搜索到它们,那么建议可以通过减少刷新频率来优化索引性能,直到索引更新完毕。索引设置API允许暂时禁用刷新间隔:
curl -XPUT :9200//_settings -d '{
"index" : {
"refresh_interval" : "-1"
}
}'
You can then revert back to the default value of “1s” once you are done indexing. This and other indexing performance tips will be explained in more detail in part 4 of this series.
在完成索引之后,你可以恢复到默认值“1s”。本系列的第4部分将更详细地解释这个设置的技巧。
Flush latency: Because data is not persisted to disk until a flush is successfully completed, it can be useful to track flush latency and take action if performance begins to take a dive. If you see this metric increasing steadily, it could indicate a problem with slow disks; this problem may escalate and eventually prevent you from being able to add new information to your index. You can experiment with lowering the index.translog.flush_threshold_size in the index’s flush settings. This setting determines how large the translog size can get before a flush is triggered. However, if you are a write-heavy Elasticsearch user, you should use a tool like iostat or the Datadog Agent to keep an eye on disk IO metrics over time, and consider upgrading your disks if needed.
Flush延迟 :因为数据在Flush完成之前不会被持久化到磁盘上,所以如果集群性能开始下降,跟踪Flush延迟并采取行动是非常必要的。如果你看到这个指标不断增加,可能表明了磁盘IO速度缓慢的问题。这个问题可能会升级,并最终阻止你向索引中添加新的信息。你可以尝试降低index.translog.flush_threshold_size这个值来缓解节点压力。这个值决定了在触发Flush操作之前,translog大小可以达到多少。但是,如果你是一个写入量巨大的ES用户,你应该使用iostat或Datadog代理这样的工具来监视磁盘IO度量,并在需要时考虑升级磁盘。
Memory usage and garbage collection
内存使用和垃圾收集
When running Elasticsearch, memory is one of the key resources you’ll want to closely monitor. Elasticsearch and Lucene utilize all of the available RAM on your nodes in two ways: JVM heap and the file system cache. Elasticsearch runs in the Java Virtual Machine (JVM), which means that JVM garbage collection duration and frequency will be other important areas to monitor.
内存是ES集群中需要密切监视的关键资源之一。ES和Lucene以两种方式利用节点上的所有可用RAM: JVM堆和文件系统缓存(file system cache)。ES在Java虚拟机(Java Virtual Machine, JVM)中运行,这意味着JVM垃圾收集的时间和频率将是我们需要监视重要领域。
JVM heap: A Goldilocks tale
JVM 堆
Elasticsearch stresses the importance of a JVM heap size that’s “just right”—you don’t want to set it too big, or too small, for reasons described below. In general, Elasticsearch’s rule of thumb is allocating less than 50 percent of available RAM to JVM heap, and never going higher than 32 GB.
ES强调的是JVM堆大小“刚好”,这一点非常重要——不希望将其设置得太大或太小,原因如下所述:一般来说,ES的经验法则是将可用RAM的50%分配给JVM堆,但最高不要超过32 GB。
The less heap memory you allocate to Elasticsearch, the more RAM remains available for Lucene, which relies heavily on the file system cache to serve requests quickly. However, you also don’t want to set the heap size too small because you may encounter out-of-memory errors or reduced throughput as the application faces constant short pauses from frequent garbage collections. Consult this guide, written by one of Elasticsearch’s core engineers, to find tips for determining the correct heap size.
分配给ES的堆内存越少,留给Lucene的内存就越多,另一方面,Lucene非常依赖文件系统缓存来快速处理请求。但是,你也不能将堆内存设置得太小,以防止会遇到内存不足或造成ES节点吞吐量降低,造成以上现象的原因是应用程序会面临频繁的垃圾收集导致及节点持续或者短暂的暂停。请参考这个指南,它是由Elasticsearch的核心工程师编写的,可以找到确定正确堆大小的技巧。
Elasticsearch’s default installation sets a JVM heap size of 1 gigabyte, which is too small for most use cases. You can export your desired heap size as an environment variable and restart Elasticsearch:
ES默认配置的JVM堆大小为1g,对于大多数集群节点来说都是太小。你可以将所需的JVM堆大小作为环境变量导出,然后重新启动ES:
$ export ES_HEAP_SIZE=30g
The other option is to set the JVM heap size (with equal minimum and maximum sizes to prevent the heap from resizing) on the command line every time you start up Elasticsearch:
另一种方法是在每次启动ES时,使用命令行设置JVM堆的大小(最小和最大值保持一致以防止堆大小调整造成的程序暂停):
$ ES_HEAP_SIZE="30g" ./bin/elasticsearch
In both of the examples shown, we set the heap size to 10 gigabytes. To verify that your update was successful, run:
以上两个实例将堆大小设置为30g,执行如下命令验证更新是否成功:
$ curl -XGET http://:9200/_cat/nodes?h=heap.max
The output should show you the correctly updated max heap value.
输出值应该是所设置的JVM最大堆值。
Garbage collection
垃圾收集
Elasticsearch relies on garbage collection processes to free up heap memory. If you want to learn more about JVM garbage collection, check out this guide.
ES依赖Java的垃圾收集来释放堆内存。如果想了解更多关于JVM垃圾收集的知识,请参阅本指南。
Because garbage collection uses resources (in order to free up resources!), you should keep an eye on its frequency and duration to see if you need to adjust the heap size. Setting the heap too large can result in long garbage collection times; these excessive pauses are dangerous because they can lead your cluster to mistakenly register your node as having dropped off the grid.
因为垃圾收集会使用资源(为了释放资源!),你应该关注垃圾收集的频率和持续时间,以便评估是否需要调整堆内存的大小。设置的堆内存太大会导致垃圾收集长时间的执行;垃圾收集过程中ES实例暂停,暂停时间如果是过度的,这是十分危险的,因为这会导致集群错误地将此节点从集群中删除。
| 指标描述 | 指标 | Metric type |
|---|---|---|
| Total count of young-generation garbage collections | jvm.gc.collectors.young.collection_count (jvm.gc.collectors.ParNew.collection_count prior to vers. 0.90.10) |
Other |
| Total time spent on young-generation garbage collections | jvm.gc.collectors.young.collection_time_in_millis (jvm.gc.collectors.ParNew.collection_time_in_millis prior to vers. 0.90.10) |
Other |
| Total count of old-generation garbage collections | jvm.gc.collectors.old.collection_count (jvm.gc.collectors.ConcurrentMarkSweep.collection_count prior to vers. 0.90.10) |
Other |
| Total time spent on old-generation garbage collections | jvm.gc.collectors.old.collection_time_in_millis (jvm.gc.collectors.ConcurrentMarkSweep.collection_time_in_millis prior to vers. 0.90.10) |
Other |
| Percent of JVM heap currently in use | jvm.mem.heap_used_percent | Resource: Utilization |
| Amount of JVM heap committed | jvm.mem.heap_committed_in_bytes | Resource: Utilization |
| 指标描述 | 指标 | Metric type |
|---|---|---|
| 年轻一代垃圾收集的总数 | jvm.gc.collectors.young.collection_count (jvm.gc.collectors.ParNew.collection_count prior to vers. 0.90.10) |
Other |
| 用于年轻一代垃圾收集的总时间 | jvm.gc.collectors.young.collection_time_in_millis (jvm.gc.collectors.ParNew.collection_time_in_millis prior to vers. 0.90.10) |
Other |
| 旧代垃圾收集的总数 | jvm.gc.collectors.old.collection_count (jvm.gc.collectors.ConcurrentMarkSweep.collection_count prior to vers. 0.90.10) |
Other |
| 旧代垃圾收集的总时间 | jvm.gc.collectors.old.collection_time_in_millis (jvm.gc.collectors.ConcurrentMarkSweep.collection_time_in_millis prior to vers. 0.90.10) |
Other |
| JVM堆使用率 | jvm.mem.heap_used_percent | Resource: Utilization |
| JVM堆内存 | jvm.mem.heap_committed_in_bytes | Resource: Utilization |
JVM metrics to watch
JVM监控指标
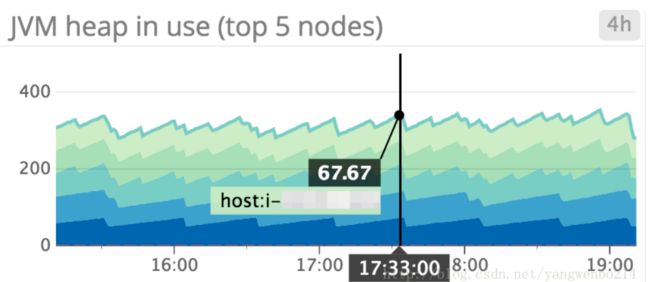
JVM heap in use : Elasticsearch is set up to initiate garbage collections whenever JVM heap usage hits 75 percent. As shown above, it may be useful to monitor which nodes exhibit high heap usage, and set up an alert to find out if any node is consistently using over 85 percent of heap memory; this indicates that the rate of garbage collection isn’t keeping up with the rate of garbage creation. To address this problem, you can either increase your heap size (as long as it remains below the recommended guidelines stated above), or scale out the cluster by adding more nodes.
JVM堆使用率 :当JVM堆使用率达到75%时,ES会启动垃圾收集。如上所示,监视集群所有节点的JVM堆使用率率,设置告警阈值为85%,当节点的这个指标超过阈值时报警,这是非常有必要的;这个指标达到85%表明垃圾收集的速度跟不上内存使用增加的速度。我们可以通过增加JVM堆的值(只要JVM堆值低于上文所述的推荐准则),或者通过添加节点扩展集群来应对这个问题。
JVM heap used vs. JVM heap committed : It can be helpful to get an idea of how much JVM heap is currently in use, compared to committed memory (the amount that is guaranteed to be available). The amount of heap memory in use will typically take on a sawtooth pattern that rises when garbage accumulates and dips when garbage is collected. If the pattern starts to skew upward over time, this means that the rate of garbage collection is not keeping up with the rate of object creation, which could lead to slow garbage collection times and, eventually, OutOfMemoryErrors.
使用的JVM堆与JVM堆内存 :了解当前的JVM堆使用率要比了解为JVM堆分配的内存量更有帮助管理集群。堆内存使用数量的时间曲线通常是锯齿状的,当垃圾收集时,这个值会下降,之后会上升。如果这个值随时间称向上倾斜的趋势,这意味着垃圾收集的速度跟不上内存使用增加的速度,这可能是由于垃圾收集时间减慢导致的,最终可能会导致OutOfMemoryError错误。
Garbage collection duration and frequency : Both young- and old-generation garbage collectors undergo “stop the world” phases, as the JVM halts execution of the program to collect dead objects. During this time, the node cannot complete any tasks. Because the master node checks the status of every other node every 30 seconds, if any node’s garbage collection time exceed 30 seconds, it will lead the master to believe that the node has failed.
垃圾收集的时间和频率 :年轻一代的和老一代垃圾收集器都会发生”停止“阶段,JVM会收集死掉的对象进程所占用的内存。在此期间,节点无法进行任何任务。由于master节点会每30s(可配置值,discovery.zen.ping_timeout=)检查每一个节点的状态,如果某个节点的垃圾收集时间超过30s,将会导致master节点认为此节点离线了。
Memory usage
内存使用
As mentioned above, Elasticsearch makes excellent use of any RAM that has not been allocated to JVM heap. Like Kafka, Elasticsearch was designed to rely on the operating system’s file system cache to serve requests quickly and reliably.
如上所述,ES可以很好地使用任何尚未分配给JVM堆的RAM。和Kafka一样,ES也被设计成依赖操作系统的文件系统缓存来快速和可靠地服务请求。
A number of variables determine whether or not Elasticsearch successfully reads from the file system cache. If the segment file was recently written to disk by Elasticsearch, it is already in the cache. However, if a node has been shut off and rebooted, the first time a segment is queried, the information will most likely have to be read from disk. This is one reason why it’s important to make sure your cluster remains stable and that nodes do not crash.
ES能否成功的从文件缓存系统中读取数据由多变量共同决定。对于新生成的段文件已经写入进了磁盘了,那么它也已经存在于内存中了。但是,如果节点突然被关闭并重新启动,那么当第一次查询这个段时,信息必须从磁盘中读取。这就是为什么要确保集群保持稳定和节点不崩溃的原因之一。
Generally, it’s very important to monitor memory usage on your nodes, and give Elasticsearch as much RAM as possible, so it can leverage the speed of the file system cache without running out of space.
通常,监视节点上的内存使用非常重要,并尽可能给ES提供RAM,这样它就可以利用文件系统缓存来处理请求。
Host-level network and system metrics
机器级别的网路和系统指标
| Name Metric | type |
|---|---|
| Available disk space | Resource: Utilization |
| I/O utilization | Resource: Utilization |
| CPU usage | Resource: Utilization |
| Network bytes sent/received | Resource: Utilization |
| Open file descriptors | Resource: Utilization |
| 指标 | 指标类型 |
|---|---|
| 磁盘可用空间 | Resource: Utilization |
| I/O利用率 | Resource: Utilization |
| CPU使用率 | Resource: Utilization |
| 网络字节发送/接收 | Resource: Utilization |
| 文件描述符使用量 | Resource: Utilization |
While Elasticsearch provides many application-specific metrics via API, you should also collect and monitor several host-level metrics from each of your nodes.
ES通过API提供了许多特定的指标,你还应该从每个节点所在机器收集和监视几个机器级的指标。
Host metrics to alert on
主机指标
Disk space : This metric is particularly important if your Elasticsearch cluster is write-heavy. You don’t want to run out of disk space because you won’t be able to insert or update anything and the node will fail. If less than 20 percent is available on a node, you may want to use a tool like Curator to delete certain indices residing on that node that are taking up too much valuable disk space.
磁盘空间 :如果ES集群的写入量较大,那么这个指标非常重要。你不希望耗尽磁盘空间,因为这样的话,你将无法插入或更新任何内容,并且节点将不可用。如果一个节点上的可用空间少于20%,你可能需要一些工具像Curator删除该节点上的某些价值不大的索引,以便腾出磁盘空间。
If deleting indices is not an option, the other alternative is to add more nodes, and let the master take care of automatically redistributing shards across the new nodes (though you should note that this creates additional work for a busy master node). Also, keep in mind that documents with analyzed fields (fields that require textual analysis—tokenizing, removing punctuation, and the like) take up significantly more disk space than documents with non-analyzed fields (exact values).
如果不能删除索引,另一种方法是添加更多的节点,并启动分片自动重新分配(应该注意到这将主节点的负载)。此外,请记住,需要分析字段的文档(需要文本分析的字段——标记、删除标点等)比具有非分析字段的文档(确切值)占用更多的磁盘空间。
Host metrics to watch
机器级指标
I/O utilization : As segments are created, queried, and merged, Elasticsearch does a lot of writing to and reading from disk. For write-heavy clusters with nodes that are continually experiencing heavy I/O activity, Elasticsearch recommends using SSDs to boost performance.
I/O利用率 :当段被创建、查询和合并时,ES会有大量的写入和读取。对于I/O操作密集型集群,建议使用SSD磁盘来提高集群性能。
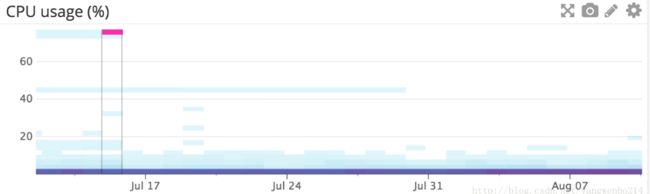
CPU utilization on your nodes : It can be helpful to visualize CPU usage in a heat map (like the one shown above) for each of your node types. For example, you could create three different graphs to represent each group of nodes in your cluster (data nodes, master-eligible nodes, and client nodes, for example) to see if one type of node is being overloaded with activity in comparison to another. If you see an increase in CPU usage, this is usually caused by a heavy search or indexing workload. Set up a notification to find out if your nodes’ CPU usage is consistently increasing, and add more nodes to redistribute the load if needed.
CPU使用率 :查看节点CPU使用率的热度图是非常有帮助的。例如,创建三个不同的图来表示集群中的每一组节点(例如,数据节点、master候选节点和client节点),通过这种方法查看哪种节点负载比较严重。如果发现CPU使用量增加,这通常是由繁重的搜索或索引任务引起的。设置一个阈值以查明节点的CPU使用率是否在持续增加,并在需要时添加更多的节点来重新分配集群负载。
Network bytes sent/received : Communication between nodes is a key component of a balanced cluster. You’ll want to monitor the network to make sure it’s healthy and that it keeps up with the demands on your cluster (e.g. as shards are replicated or rebalanced across nodes). Elasticsearch provides transport metrics about cluster communication, but you can also look at the rate of bytes sent and received to see how much traffic your network is receiving.
发送/接收的字节数 :节点之间通信是平衡集群的关键组件。监视网络的情况,并且确定它能够赶得上集群的去求(例如,当跨节点分片复制或重新平衡分片)。ES提供了集群通信的传输指标,但是你还可以通过查看发送和接收的字节数来查看网络流量出口和入口值。
Open file descriptors : File descriptors are used for node-to-node communications, client connections, and file operations. If this number reaches your system’s max capacity, then new connections and file operations will not be possible until old ones have closed. If over 80 percent of available file descriptors are in use, you may need to increase the system’s max file descriptor count. Most Linux systems ship with only 1,024 file descriptors allowed per process. When using Elasticsearch in production, you should reset your OS file descriptor count to something much larger, like 64,000.
文件描述符使用量 :文件描述符用于节点到节点的通信、客户端连接和文件操作任务。如果这个数字到达了系统的最大容量,那么新的连接和文件操作将不可能被执行直到有空闲的。如果超过80%的文件描述符在使用,可能需要增加系统的文件描述符的最大值。大多数Linux系统只允许每个进程使用1024个文件描述符。在生产环境中使用ES应该增加文件描述符的使用值比如64 000。
HTTP connections
HTTP连接
| Metric description | Name | Metric type |
|---|---|---|
| Number of HTTP connections currently open | http.current_open | Resource: Utilization |
| Total number of HTTP connections opened over time | http.total_opened | Resource: Utilization |
| 指标描述 | 指标 | 指标类型 |
|---|---|---|
| 当前打开的HTTP连接的数量 | http.current_open | Resource: Utilization |
| 打开的HTTP连接的总数 | http.total_opened | Resource: Utilization |
Requests sent in any language but Java will communicate with Elasticsearch using RESTful API over HTTP. If the total number of opened HTTP connections is constantly increasing, it could indicate that your HTTP clients are not properly establishing persistent connections. Reestablishing connections adds extra milliseconds or even seconds to your request response time. Make sure your clients are configured properly to avoid negative impact on performance, or use one of the official Elasticsearch clients, which already properly configure HTTP connections.
除了Java之外,以任何语言发送的请求都将使用基于RESTful的API通过HTTP与ES进行通信。如果打开的HTTP连接的总数不断增加,这可能表明你的HTTP客户端没有正确地建立持久连接。重新建立连接会导致请求响应时间延长。确保您的客户端被正确的配置以避免对性能的负面影响,或者使用一个官方的ES客户端。
Cluster health and node availability
集群健康和节点可用性
| Metric description | Name | Metric type |
|---|---|---|
| Cluster status (green, yellow, red) | cluster.health.status | Other |
| Number of nodes | cluster.health.number_of_nodes | Resource: Availability |
| Number of initializing shards | cluster.health.initializing_shards | Resource: Availability |
| Number of unassigned shards | cluster.health.unassigned_shards | Resource: Availability |
| Metric description | Name | Metric type |
|---|---|---|
| 集群状态 | cluster.health.status Other | |
| 节点数 | cluster.health.number_of_nodes | Resource: Availability |
| 初始化分片数 | cluster.health.initializing_shards | Resource: Availability |
| 未分配分片数 | cluster.health.unassigned_shards | Resource: Availability |
Cluster status : If the cluster status is yellow, at least one replica shard is unallocated or missing. Search results will still be complete, but if more shards disappear, you may lose data.
集群状态 :如果集群状态为黄色,则至少有一个副本分片未分配或丢失。搜索结果仍然是完整的,但是如果更多的分片丢失可能会丢失数据。
A red cluster status indicates that at least one primary shard is missing, and you are missing data, which means that searches will return partial results. You will also be blocked from indexing into that shard. Consider setting up an alert to trigger if status has been yellow for more than 5 min or if the status has been red for the past minute.
集群状态为红色表明至少有一个主分片丢失,集群丢失了数据,这意味着搜索将返回部分结果。你也将被禁止索引到丢失的主分片。考虑设置一个警报,如果状态是黄色的,超过5分钟,或者状态是红色的,过去一分钟。
Initializing and unassigned shards : When you first create an index, or when a node is rebooted, its shards will briefly be in an “initializing” state before transitioning to a status of “started” or “unassigned”, as the master node attempts to assign shards to nodes in the cluster. If you see shards remain in an initializing or unassigned state too long, it could be a warning sign that your cluster is unstable.
初始化和未分配的碎片 :当第一次创建索引时,或当一个节点重新启动时,它的分片将在“已启动”或“未分配”状态之前短暂地处于“初始化”状态,因为主节点试图将分片进行分配。如果看到分片长时间处于初始化或未分配状态,则可能是集群不稳定的信号。
Resource saturation and errors
资源饱和度和错误
Elasticsearch nodes use thread pools to manage how threads consume memory and CPU. Since thread pool settings are automatically configured based on the number of processors, it usually doesn’t make sense to tweak them. However, it’s a good idea to keep an eye on queues and rejections to find out if your nodes aren’t able to keep up; if so, you may want to add more nodes to handle all of the concurrent requests. Fielddata and filter cache usage is another area to monitor, as evictions may point to inefficient queries or signs of memory pressure.
ES使用线程池来管理线程消耗的内存和CPU。由于线程池设置是根据处理器的数量自动配置的,因此调整它们通常没有意义。但是,关注队列和拒绝数,看看节点是否能跟上请求的进度,如果不能,可能需要添加更多的节点来处理并发请求。Fielddata和过滤器缓存的使用是另一个需要监视的领域,因为驱除可能是由于低效的查询或者暴露出了内存压力的迹象。
Thread pool queues and rejections
线程池队列和拒绝数
Each node maintains many types of thread pools; the exact ones you’ll want to monitor will depend on your particular usage of Elasticsearch. In general, the most important ones to monitor are search, index, merge, and bulk, which correspond to the request type (search, index, and merge and bulk operations).
每个节点都会维护多种类型的线程池;要监视哪些线程池取决于ES的使用场景。通常,最需要监视的是搜索、索引、合并和批量处理的线程池(对应的请求类型是搜索、索引、合并和批量操作)。
The size of each thread pool’s queue represents how many requests are waiting to be served while the node is currently at capacity. The queue allows the node to track and eventually serve these requests instead of discarding them. Thread pool rejections arise once the thread pool’s maximum queue size (which varies based on the type of thread pool) is reached.
每个线程池队列的大小表明了处于等待服务的请求数量。队列允许节点跟踪并最终服务这些请求,而不是丢弃它们。一旦线程池达到最大队列大小(根据线程池的类型而变化),就会出现请求被拒绝的情况。
| Metric description | Name | Metric type |
|---|---|---|
| Number of queued threads in a thread pool | thread_pool.bulk.queue thread_pool.index.queue thread_pool.search.queue thread_pool.merge.queue |
Resource: Saturation |
| Number of rejected threads a thread pool | thread_pool.bulk.rejected thread_pool.index.rejected thread_pool.search.rejected thread_pool.merge.rejected |
Resource: Error |
| Metric description | Name | Metric type |
|---|---|---|
| 程池中排队的线程数 | thread_pool.bulk.queue thread_pool.index.queue thread_pool.search.queue thread_pool.merge.queue |
Resource: Saturation |
| 线程池中被拒绝的线程数 | thread_pool.bulk.rejected thread_pool.index.rejected thread_pool.search.rejected thread_pool.merge.rejected` |
Resource: Error |
Metrics to watch
监控指标
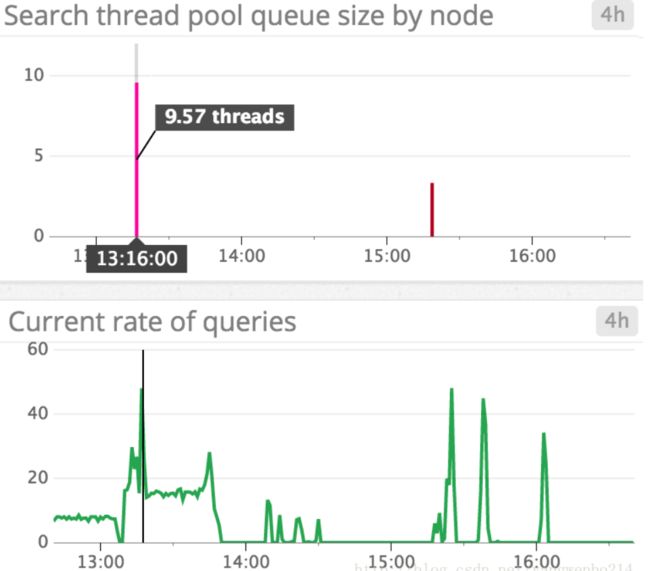
Thread pool queues: Large queues are not ideal because they use up resources and also increase the risk of losing requests if a node goes down. If you see the number of queued and rejected threads increasing steadily, you may want to try slowing down the rate of requests (if possible), increasing the number of processors on your nodes, or increasing the number of nodes in the cluster. As shown in the screenshot below, query load spikes correlate with spikes in search thread pool queue size, as the node attempts to keep up with rate of query requests.
线程池队列:太长的队列并不是理想的,因为它们会消耗资源,而且如果节点宕机了,还会增加丢失请求的风险。如果看到线程队列和拒绝的数量稳步增加,可能需要尝试减慢请求率(如果可能的话),增加节点上的处理器的数量,或者增加集群中的节点数量。如下图所示,查询负载峰值与搜索线程池队列大小的峰值相关,因为节点试图跟上查询请求的速率。
Bulk rejections and bulk queues : Bulk operations are a more efficient way to send many requests at one time. Generally, if you want to perform many actions (create an index, or add, update, or delete documents), you should try to send the requests as a bulk operation instead of many individual requests.
批量请求的拒绝和队列长度:批量请求操作是最有效的方式来发送请求。通常来说,如果执行许多操作(创建索引、添加、更新或删除文档),应该尝试将请求作为批量操作发送,而不是单独发送。
Bulk rejections are usually related to trying to index too many documents in one bulk request. According to Elasticsearch’s documentation, bulk rejections are not necessarily something to worry about. However, you should try implementing a linear or exponential backoff strategy to efficiently deal with bulk rejections.
批量请求拒绝数通常是由于试图在一个批量请求中索引太多文档造成的。根据ES文档,批量拒绝并不一定需要担心。但是,您应该试着实现一个线性的或指数补偿策略以有效地处理批量拒绝。
Cache usage metrics
缓存使用率指标
Each query request is sent to every shard in an index, which then hits every segment of each of those shards. Elasticsearch caches queries on a per-segment basis to speed up response time. On the flip side, if your caches hog too much of the heap, they may slow things down instead of speeding them up!
每个查询请求都会被发送到索引的每个分片的每个段。根据段缓存查询以加快响应时间。另一方面,如果您的缓存占用了太多的堆,它们可能会降低速度而不是加快速度!
In Elasticsearch, each field in a document can be stored in one of two forms: as an exact value or as full text. An exact value, such as a timestamp or a year, is stored exactly the way it was indexed because you do not expect to receive to query 1/1/16 as “January 1st, 2016.” If a field is stored as full text, that means it is analyzed—basically, it is broken down into tokens, and, depending on the type of analyzer, punctuation and stop words like “is” or “the” may be removed. The analyzer converts the field into a normalized format that enables it to match a wider range of queries.
在ES中,文档中的每个字段有两种存储形式:准确的值或全文。准确的值,比如时间戳,按照索引的方式存储,因为不希望接收到查询1/1/16作为“2016年1月1日”。如果一个字段被存储为全文,这意味着它会被用于分析——基本上,它会被分解成一些标记的集合,根据分析器的类型,标点符号和停止词如“是”或“the”可能被删除。分析器将字段转换为规范化格式,使其能够匹配更大范围的查询。
For example, let’s say that you have an index that contains a type called location; each document of the type location contains a field, city, which is stored as an analyzed string. You index two documents: one with “St. Louis” in the city field, and the other with “St. Paul”. Each string would be lowercased and transformed into tokens without punctuation. The terms are stored in an inverted index that looks something like this:
例如,假设您有一个索引,其中包含一个名为location的类型;每个文档的location类型都被包含一个字段,city,它存储为一个分析字符串。你索引两个文档:一个是带有“St.Louis”的city类型,而另一个是“St.Paul”。每个字符串将被转换成小写并且没有标点符号。这些术语被存储在一个反向索引中,看起来像如下这个样子:
| Term | Doc1 | Doc2 |
|---|---|---|
| st | x | x |
| louis | x | |
| paul | x |
|字段 |Doc1| Doc2|
|st| x| x|
|louis |x ||
|paul| | x|
The benefit of analysis is that you can search for “st.” and the results would show that both documents contain the term. If you had stored the city field as an exact value, you would have had to search for the exact term, “St. Louis”, or “St. Paul”, in order to see the resulting documents.
分析的好处是您可以搜索“st”。结果显示,这两个文件都包含了这个词。如果您将city字段存储为一个确切的值,那么您将不得不搜索确“St. Louis”,或“St. Paul”来看到这些文档。
Elasticsearch uses two main types of caches to serve search requests more quickly: fielddata and filter.
ES使用两种主要的缓存类型来更快地为搜索请求提供服务:fielddata和filter。
Fielddata cache
Fielddata 缓存
The fielddata cache is used when sorting or aggregating on a field, a process that basically has to uninvert the inverted index to create an array of every field value per field, in document order. For example, if we wanted to find a list of unique terms in any document that contained the term “st” from the example above, we would:
fielddata缓存用于对字段进行排序或聚合,这个过程基本上是按文档顺序对反向索引进行反向工程,以创建每个字段值的数组。例如,如果我们想在任何包含上述例子中的术语“st”的文档中找到唯一的术语列表,我们将:
Scan the inverted index to see which documents contain that term (in this case, Doc1 and Doc2)
For each of the documents found in step 1, go through every term in the index to collect tokens from that document, creating a structure like the below:
|Doc| Terms|
|Doc1 |st, louis|
|Doc2| st, paul|
Now that the inverted index has been “uninverted,” compile the unique tokens from each of the docs (st, louis, and paul). Compiling fielddata like this can consume a lot of heap memory, especially with large numbers of documents and terms. All of the field values are loaded into memory.
扫描反向索引,查看哪些文档包含该字段(在本例中为Doc1和Doc2)
对于步骤1中发现的每个文档,遍历索引中的每一项,从该文档收集token,创建如下结构:
|Doc |Terms|
|Doc1 |st, louis|
|Doc2 |st, paul|
现在,反向索引已经“不反向”了,从每个文档(st, louis和paul)编译惟一的token。像这样的编译,fielddata会消耗大量堆内存,特别是对于大量的文档和术语,所有字段值都被加载到内存中。
For versions prior to 1.3, the fielddata cache size was unbounded. Starting in version 1.3, Elasticsearch added a fielddata circuit breaker that is triggered if a query tries to load fielddata that would require over 60 percent of the heap.
对于1.3之前的版本,fielddata缓存大小是无限制的。从1.3版本开始,Elasticsearch增加了一个fielddata断路器,如果查询试图加载需要超过60%堆的fielddata(默认值60%),就会触发这个断路器。
Filter cache
过滤器缓存
Filter caches also use JVM heap. In versions prior to 2.0, Elasticsearch automatically cached filtered queries with a max value of 10 percent of the heap, and evicted the least recently used data. Starting in version 2.0, Elasticsearch automatically began optimizing its filter cache, based on frequency and segment size (caching only occurs on segments that have fewer than 10,000 documents or less than 3 percent of total documents in the index). As such, filter cache metrics are only available to Elasticsearch users who are using a version prior to 2.0.
过滤器缓存也使用JVM堆。在2.0之前的版本中,ES自动缓存过滤后查询,其最大值为堆的10%,并删除最近使用率最少的数据。从2.0版本开始,ES根据频率和段大小自动开始优化它的过滤器缓存(缓存只发生在拥有少于10,000个文档或索引中少于3%的文档的段上)。因此,过滤器缓存度量仅对使用2.0之前版本的用户可用。
For example, a filter query could return only the documents for which values in the year field fall in the range 2000–2005. During the first execution of a filter query, Elasticsearch will create a bitset of which documents match the filter (1 if the document matches, 0 if not). Subsequent executions of queries with the same filter will reuse this information. Whenever new documents are added or updated, the bitset is updated as well. If you are using a version of Elasticsearch prior to 2.0, you should keep an eye on the filter cache as well as eviction metrics (more about that below).
例如,过滤器查询只能返回年份字段中的值在2000-2005范围内的文档。在第一次执行筛选器查询时,ES将创建一个位集,其中的文档与筛选器匹配(如果文档匹配,则为1,如果不匹配,则为0)。使用相同过滤器的查询的后续执行将重用此信息。每当添加或更新新文档时,位集也会被更新。如果您在2.0之前使用的是一个版本的Elasticsearch,那么您应该关注过滤器缓存以及退出度量(更多相关内容见下文)。
| Metric description | Name | Metric type |
|---|---|---|
| Size of the fielddata cache (bytes) | indices.fielddata.memory_size_in_bytes | Resource: Utilization |
| Number of evictions from the fielddata cache | indices.fielddata.evictions | |
| Size of the filter cache (bytes) (only pre-version 2.x) | indices.filter_cache.memory_size_in_bytes | Resource: Utilization |
| Number of evictions from the filter cache (only pre-version 2.x) | indices.filter_cache.evictions | Resource: Saturation |
| Metric description | Name | Metric type |
|---|---|---|
| Fielddata堆大小 | indices.fielddata.memory_size_in_bytes | Resource: Utilization |
| Fielddata堆驱除数 | indices.fielddata.evictions | Resource: Saturation |
| Size of the filter cache (bytes) (only pre-version 2.x) | indices.filter_cache.memory_size_in_bytes | Resource: Utilization |
| Number of evictions from the filter cache (only pre-version 2.x) | indices.filter_cache.evictions | Resource: Saturation |
Cache metrics to watch
缓存监控指标
Fielddata cache evictions : Ideally, you want to limit the number of fielddata evictions because they are I/O intensive. If you’re seeing a lot of evictions and you cannot increase your memory at the moment, Elasticsearch recommends a temporary fix of limiting fielddata cache to 20 percent of heap; you can do so in your config/elasticsearch.yml file. When fielddata reaches 20 percent of the heap, it will evict the least recently used fielddata, which then allows you to load new fielddata into the cache.
Fielddata 缓存驱除 :理想情况下,你希望限制字段数据驱逐的数量,因为它们是I/O密集型操作。如果有大量的删除操作,并且目前无法增加内存,那么请使用ES进行临时修复的建议,将fielddata缓存限制在JVM堆的20%以内;在comfiig/elasticsearch.yml文件中可以修改。当fielddata达到堆的20%时,它将删除最近最少使用的fielddata,从而允许您将新的fielddata加载到缓存中。
Elasticsearch also recommends using doc values whenever possible because they serve the same purpose as fielddata. However, because they are stored on disk, they do not rely on JVM heap. Although doc values cannot be used for analyzed string fields, they do save fielddata usage when aggregating or sorting on other types of fields. In version 2.0 and later, doc values are automatically built at document index time, which has reduced fielddata/heap usage for many users. However, if you are using a version between 1.0 and 2.0, you can also benefit from this feature—simply remember to enable them when creating a new field in an index.
ES还建议尽可能使用doc值,因为它们的用途与fielddata相同。但是,因为它们存储在磁盘上,所以它们不依赖于JVM堆。虽然不能将doc值用于分析的字符串字段,但是在聚合或排序其他类型的字段时,它们确实可以节省字段数据的使用。在2.0版和以后的版本中,doc值是在文档索引时自动构建的,这减少了许多用户对fielddata/heap的使用。但是,如果您正在使用1.0和2.0之间的版本,那么您也可以从这个特性中获益—只需记住在索引中创建新字段时启用它们即可。
Filter cache evictions : As mentioned earlier, filter cache eviction metrics are only available if you are using a version of Elasticsearch prior to 2.0. Each segment maintains its own individual filter cache. Since evictions are costlier operations on large segments than small segments, there’s no clear-cut way to assess how serious each eviction may be. However, if you see evictions occurring more often, this may indicate that you are not using filters to your best advantage—you could just be creating new ones and evicting old ones on a frequent basis, defeating the purpose of even using a cache. You may want to look into tweaking your queries (for example, using a bool query instead of an and/or/not filter).
过滤缓存驱除数 :如前所述,过滤缓存删除指标只有在使用2.0之前的一个版本的弹性搜索时才可用。每个段维护自己的筛选器缓存。由于拆迁是在大范围而不是小范围内进行的代价更高的行动,因此没有明确的方法来评估每一次拆迁的严重程度。然而,如果您看到驱逐发生得更频繁,这可能表明您没有使用过滤器达到最佳的好处——您可能只是创建新的过滤器,并频繁地驱逐旧的过滤器,这甚至违背了使用缓存的目的。您可能希望调整查询(例如,使用bool查询而不是and/or/not过滤器)。
Pending tasks
Pending 任务
| Metric description | Name | Metric type |
|---|---|---|
| Number of pending tasks | pending_task_total | Resource: Saturation |
| Number of urgent pending tasks | pending_tasks_priority_urgent | Resource: Saturation |
| Number of high-priority pending tasks | pending_tasks_priority_high | Resource: Saturation |
| Metric description | Name | Metric type |
|---|---|---|
| Number of pending tasks | pending_task_total | Resource: Saturation |
| Number of urgent pending tasks | pending_tasks_priority_urgent | Resource: Saturation |
| Number of high-priority pending tasks | pending_tasks_priority_high | Resource: Saturation |
Pending tasks can only be handled by master nodes. Such tasks include creating indices and assigning shards to nodes. Pending tasks are processed in priority order—urgent comes first, then high priority. They start to accumulate when the number of changes occurs more quickly than the master can process them. You want to keep an eye on this metric if it keeps increasing. The number of pending tasks is a good indication of how smoothly your cluster is operating. If your master node is very busy and the number of pending tasks doesn’t subside, it can lead to an unstable cluster.
Pending任务只能由master节点进行处理。这些任务包括创建索引和为节点分配分片等待。Pending任务按照优先级顺序记性处理的——优先级首先是加急,然后是高优先级。当更改发生的速度超过主服务器处理更改的速度时,这些任务开始堆积。如果这个指标一直在增加,你需要关注它。Pending任务的数量很好地显示了集群运行的顺利程度。如果集群的master节点非常繁忙,且Pending任务的数量没有减少,则可能导致集群不稳定。
Unsuccessful GET requests
失败的GET请求
| Metric description | Name | Metric type |
|---|---|---|
| Total number of GET requests where the document was missing | indices.get.missing_total | Work: Error |
| Total time spent on GET requests where the document was missing | indices.get.missing_time_in_millis | Work: Error |
| Metric description | Name | Metric type |
|---|---|---|
| Total number of GET requests where the document was missing | indices.get.missing_total | Work: Error |
| Total time spent on GET requests where the document was missing | indices.get.missing_time_in_millis | Work: Error |
A GET request is more straightforward than a normal search request—it retrieves a document based on its ID. An unsuccessful get-by-ID request means that the document ID was not found. You shouldn’t usually have a problem with this type of request, but it may be a good idea to keep an eye out for unsuccessful GET requests when they happen.
GET请求比普通的搜索请求更简单——它根据文档的ID检索文档。不成功的GET请求意味着没有找到文档ID。你通常不会对这类请求有什么问题,但是当不成功的请求发生时,最好留心它们。
Conclusion
结论
In this post, we’ve covered some of the most important areas of Elasticsearch to monitor as you grow and scale your cluster:
在这篇文章中,我们讨论了随着集群的发展和规模的扩大,需要监控的一些核心指标:
-
Search and indexing performance
-
Memory and garbage collection
-
Host-level system and network metrics
-
Cluster health and node availability
-
Resource saturation and errors
-
查询和索引性能
-
内存和垃圾收集
-
机器级别的系统和网络性能
-
集群监控和节点可用性
-
资源饱和度和错误
As you monitor Elasticsearch metrics along with node-level system metrics, you will discover which areas are the most meaningful for your specific use case. Read part 2 of our series to learn how to start collecting and visualizing the Elasticsearch metrics that matter most to you.
当您监控了ES字表和机器级系统指标时,你将发现哪些指标对你的ES使用环境最有意义。阅读本系列的第2部分,了解如何开始收集和可视化ES的监控指标。
原文链接:https://www.datadoghq.com/blog/monitor-elasticsearch-performance-metrics/