以 tf.data 优化训练数据输入管道 丨 Google 开发者大会 2018
以 tf.data 优化训练数据输入管道 丨 Google 开发者大会 2018
Google 开发者大会 (Google Developer Days,简称 GDD) 是展示 Google 最新开发者产品和平台的全球盛会,旨在帮助你快速开发优质应用,发展和留住活跃用户群,充分利用各种工具获得更多收益。2018 Google 开发者大会于 9 月 20 日和 21 日于上海举办。?Google 开发者大会 2018 掘金专题
GDD 2018 第二天的 9 月 21 日 ,陈爽(Google Brain 软件工程师)为我们带来了《以 tf.data 优化训练数据》,讲解如何使用 tf.data 为各类模型打造高性能的 TensorFlow 输入渠道,本文将摘录演讲技术干货。
数据输入管道
- 大多人将时间和金钱花在神经网路架构上,数据输入容易被忽略
- 没有好的数据输入管道,GPU 再强速度也不会显着提高
- 目标:高效丶灵活丶易用
ETL 系统
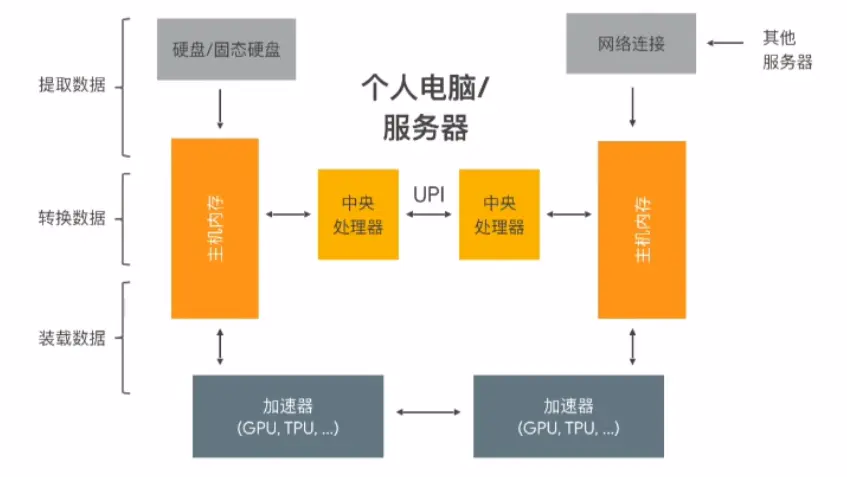
- 提取数据(Extract):将训练数据从存取器(硬盘丶云端等)提取
- 转换数据(Transform):将数据转换为模型可读取的数据,同时进行数据清洗等预处理
- 装载数据(Load):将处理好的数据装载至加速器
tf.data:为机器学习设计的数据输入系统
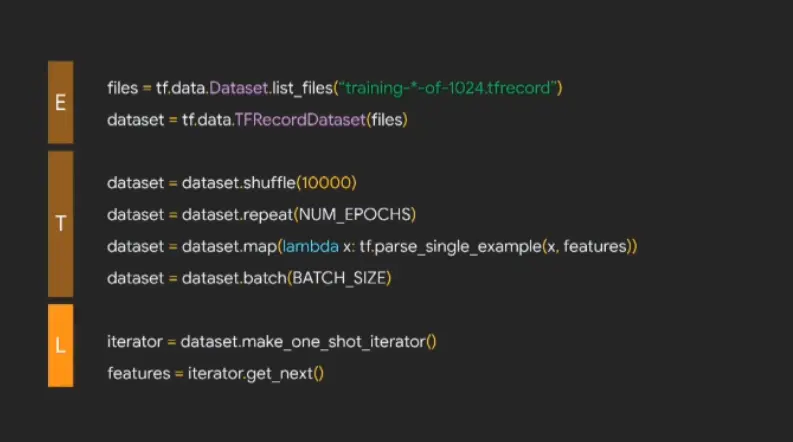
图中代码分别对应 ETL 系统的三个步骤,使用 tf.data 即可轻松实现。
tf.data 优化手段:以上图代码为例
- 多线程处理(使用 num_parallel_reads)
files = tf.data.Dataset.list_files("training-*-of-1024.tfrecord")
dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32)
复制代码- 合并转换步骤(如 shuffle_and_repaeat, map_and_batch)
dataset = dataset.apply(tf.contrib.data.shuffle_and_repaeat(10000, NUM_EPOCHS))
dataset = dataset.apply(tf.contrib.data.map_and_batch(lambda x: ..., BATCH_SIZE))
复制代码- 流水线化(使用 prefetch_to_device)
dataset = dataset.apply(tf.contrib.data.prefetch_to_device("/gpu:0"))
复制代码
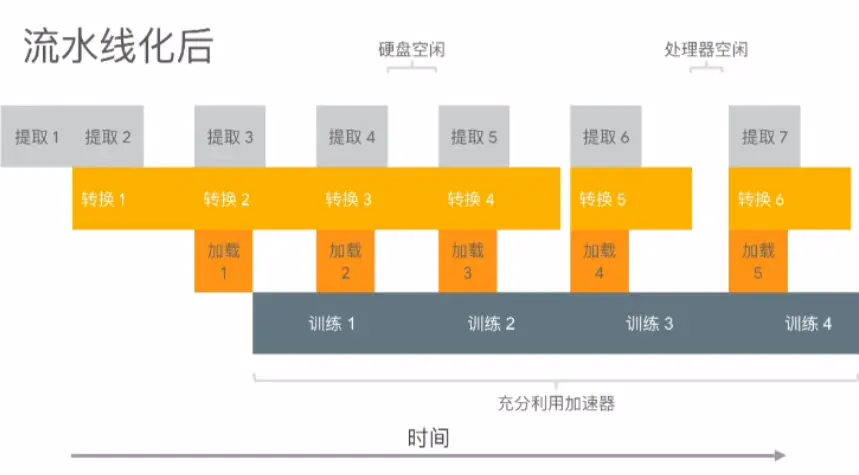
最终代码如下图所示,更多优化手段可以参考 tf.data 性能指南:

tf.data 的灵活性
支持函数式编程

如上图,可以用自定义的 map_fn 处理 TensorFlow 或兼容的函数,同时支持 AutoGraph 处理过的函数。
支持不同语言与数据类型
- 使用 Dataset.form_generator() 支持 Python 代码生成 Dataset
- 使用 DatasetOpKernel 和 tf.load_op_library 支持自定义 C++ 数据处理代码
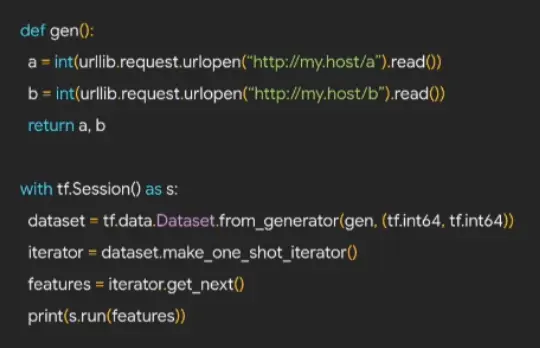
如下图,使用 Python 自带的 urllib 获取服务器数据,存入 dataset:
支持多种数据来源
如普通文件系统丶GCP 云储存丶其他云储存丶SQL 数据库等。
读取 Google 云储存的 TFRecord 文件示例:
files = tf.contrib.data.TFRecordDataset(
"gs://path/to/file.tfrecord", num_parallel_reads=32)
复制代码使用自订 SQL 数据库示例:
files = tf.contrib.data.SqlDataset(
"sqllite", "/foo/db.sqlite", "SELECT name, age FROM people",
(tf.string, tf.int32))
复制代码tf.data 的易用性
在 Eager 执行模式下,可以直接使用 Python for 循环:
tf.enable_eager_execution()
for batch in dataset:
train_model(batch)
复制代码为 TF Example 或 CSV 提供现有高效配方

上图可以简单替换为一个函数:
dataset = tf.contrib.data.make_batched_features_dataset(
"training-*-of-1024.tfrecord",
BATCH_SIZE, features, num_epochs=NUM_EPOCHS)
复制代码使用 CSV 数据集的情境:
dataset = tf.contrib.data.make_csv_dataset(
"*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS)
复制代码使用 AUTOTUNE 自动调节管道
可以简单的使用 AUTOTUNE 找到 prefetching 的最佳参数:
dataset = dataset.prefetch(tf.contrib.data.AUTOTUNE)
复制代码支持 Keras 和 Estimators 相互兼容
对於 Keras,可以将 dataset 直接传递使用;对於 Estimators 训练函数,将 dataset 包装至输入函数并返回即可,如下示例:
def input_fn():
dataset = tf.contrib.data.make_csv_dataset(
"*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS)
return dataset
tf.estimator.Estimator(model_fn=train_model).train(input_fn=input_fn)
复制代码实际运用经验
- 原始 tf.data 数据输入代码: ~150 图像 / 秒
- 管道化的 tf.data 数据输入代码: ~1,750 图像 / 秒 => 12倍的性能!
- Cloud TPU 上使用 tf.data: ~4,100 图像 / 秒
- Cloud TPU Pod 上使用 tf.data: ~219,000 图像 / 秒
结论
本场演讲介绍了 tf.data 这个兼具高效丶灵活与易用的 API,同时了解如何运用管道化及其他优化手段来增进运算效能,以及许多可能未曾发现的实用函数。
资源
- 入门指南
- www.tensorflow.org/guide/datas…
- www.tensorflow.org/performance…
- 示例代码
- github.com/tensorflow/…
- github.com/tensorflow/…
- github.com/tensorflow/…