Apache Pulsar之与Apache Kafka的异同——标准队列和流
消息模型是用户在选择流消息系统时应该考虑的第一件事。消息传递模型应该涵盖以下3个领域:
- 消息消费:如何分发和消费消息
- 消息确认:如何确认消息
- 消息存储:消息保留多长时间,消息删除的触发机制,如何删除
消息消费方式
在现代实时流架构中,消息传递案例可以分为两类:队列和流。
- 队列
队列是无须的或共享的消息。使用队列消息传递,可以创建多个消费者来从点对点消息传递通道接收消息。当通道传递消息时,任何消费者都可能收到消息。消息传递系统的实现确定哪个消费者实际接收消息。
Queuing通常与无状态应用程序一起使用。无状态应用程序不关心顺序,但它们确实需要识别或删除单个消息的能力,以及尽可能扩展并行消耗的能力。典型的基于队列的消息传递系统包括RabbitMQ和RocketMQ。
- 流
相比之下,流是严格有序的或独占的消息传递。使用流消息传递,始终只有一个消费者使用消息传递通道。消费者接收从通道发送的消息,其顺序与消息的写入顺序一致。
Streaming通常与有状态的应用程序一起使用。有状态应用程序关心消息顺序及其状态。消息的顺序决定有状态应用程序的状态。当发生无序消费时,排序将影响应用程序,需要处理逻辑的正确性。
在面向微服务或事件驱动的体系结构中,流和队列都是必要的。
Pulsar的模型
Pulsar将Queuing和Streaming统一为一个统一的消息模型:producer-topic-subscription-consumer。主题是发数据的通道。每个主题分区都基于存储在Apache BookKeeper中的分布式日志。发布者发布的每条消息只在一个主题分区上存储一次,复制到多个bookies (BookKeeper服务器)上存储,消费者可以根据需要多次使用。
Topic是消费数据来源。尽管消息只在主题分区上存储一次,但是可以使用不同的方式使用这些消息。
消费者被分组在一起消费消息。每一组消费者相当于一个subscription 在一个topic。每个使用者组都可以使用自己的方式来消费、独占、共享或failover,在不同的使用者组中消费方式可能是不相同的。这将队列和流结合在一个模型和API中,它的设计和实现的目标是不影响性能和节省成本开销,同时也为用户提供了很大的灵活性,以最适合当前用例的方式使用消息。
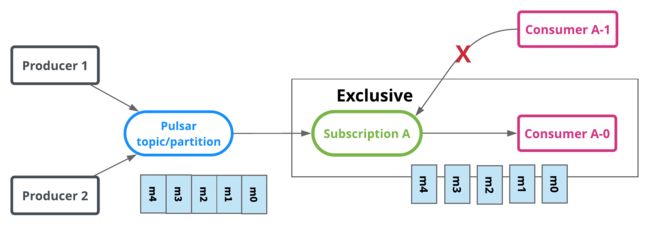
- Exclusive subscriptions (streaming)
顾名思义,在任何给定时间,订阅(使用者组)中只能有一个使用者使用主题分区。下面的图1演示了一个独占订阅的示例。有一个活动消费者A-0与订阅a。消息m0到m4按顺序交付,并由A-0使用。如果另一个消费者A-1希望附加到订阅A,则不允许这样做。
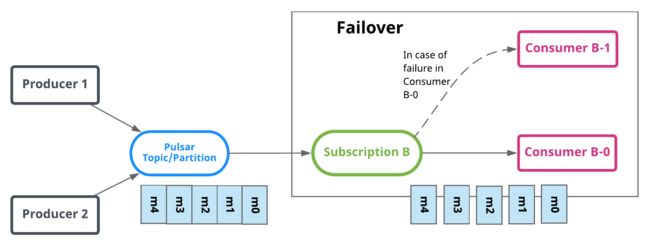
- Failover subscriptions (streaming)
使用故障转移订阅,多个使用者可以附加到同一个订阅。但是,对于给定的主题分区,将选择一个使用者作为该主题分区的主使用者。其他使用者将被指定为故障转移使用者。当主使用者断开连接时,分区将被重新分配给一个故障转移使用者来使用,而新分配的使用者将成为新的主使用者。当这种情况发生时,所有非压缩消息都将传递给新的主用户。这类似于Apache Kafka中的用户分区再平衡。
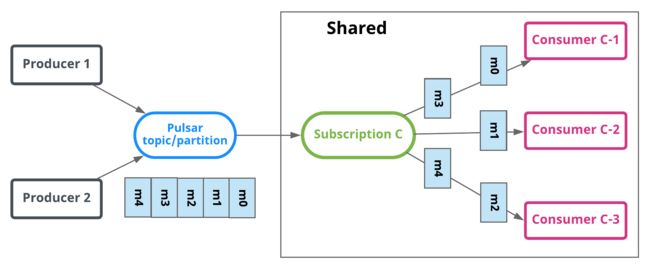
使用共享订阅,您可以在同一个订阅上附加任意数量的使用者。消息在多个消费者之间以循环分发的方式传递,任何给定的消息都只传递给一个消费者。当使用者断开连接时,所有传递给它但未被确认的消息都将被重新调度,以便发送给订阅时仍然存在的使用者。图3演示了一个共享订阅。消费者C-1、C-2和C-3都使用同一主题分区上的消息。每个消费者收到约三分之一的消息。
如何选择Queuing和Streaming
Exclusive 和 Failover每个主题分区只允许一个使用者,按分区顺序消费,适用于Streaming。Shared允许每个主题分区有多个使用者。同一订阅中的每个使用者只接收发布到主题分区的消息的一部分。Shared适用于Queuing,这些用例不需要订购,并且消费者数量可以大于分区数量。
一个Subscription相当于Kafka中的一个消费者组,subscriptions 高可用且简单,可以根据需要创建任意数量的订阅。同一主题的不同订阅不必具有相同的订阅类型。这意味着您可以在同一个主题上拥有一个包含10个使用者的故障转移订阅和一个包含20个使用者的共享订阅。如果共享订阅处理事件较慢,则可以在不更改分区数量的情况下向共享订阅添加更多使用者。图4描述了一个包含3个订阅(a、B和C)的主题,并说明了消息如何在系统中从生产者流向消费者。
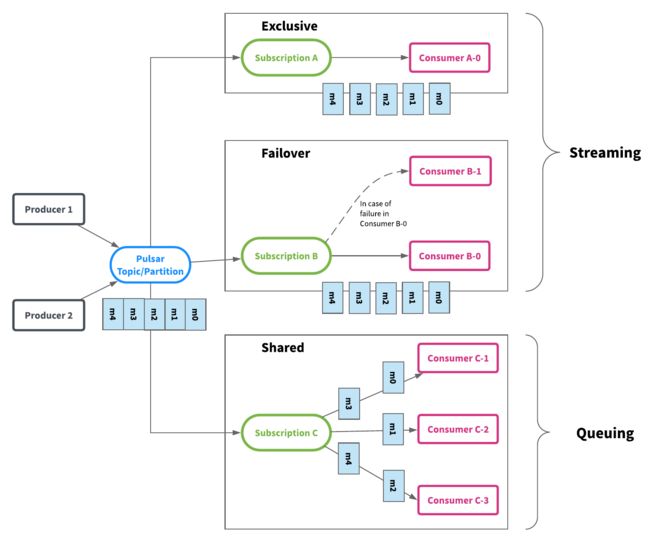
除了统一消息传递API之外,由于Pulsar主题分区实际上是存储在Apache BookKeeper中的分布式日志,所以它还提供了一个reader API(类似于consumer API,但没有offset管理),以便用户完全控制如何使用消息。
消息确认
当使用跨机器分布的消息传递系统时,可能会发生故障。在消息传递系统中使用来自主题的消息的使用者的情况下,消费消息的消费者和服务于主题分区的消息代理都可能失败。故障发生到恢复之后,消费者可以从发生故障的地方继续消费,这样不会丢数据,也不会重复消费。在Kafka中,恢复的地方通常称为偏移量,恢复的过程被称为消息确认或提交偏移量。
Pulsar中,游标(cursor)用于跟踪每个订阅的消息确认。每当消费者对主题分区上的消息进行ack时,游标就会更新。可以确保使消费者不会重复消费。然而,游标不像Apache Kafka中那样是简单的偏移量。游标要多得多。
Apache Pulsar有两种方法可以确认消息,单独确认ack或累积确认消息。通过累积确认,消费者只需要确认它收到的最后一条消息。主题分区中的所有消息(包括)提供消息ID将被标记为已确认,并且不会再次传递给消费者。累积确认与Apache Kafka中的偏移更新实际上相同。
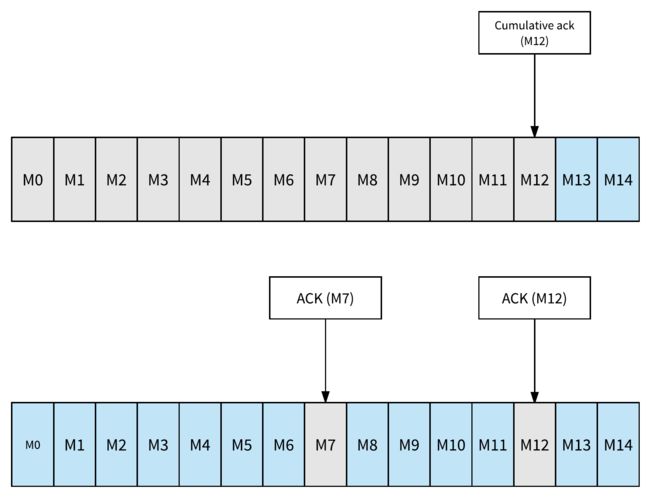
Apache Pulsar的区别特征是能够单独进行ack,即选择性acking。消费者可以单独确认消息。Acked消息将不会被重新传递。图5说明了ack个体和ack累积之间的差异(灰色框中的消息被确认并且不会被重新传递)。在图的顶部,它显示了ack累积的示例,M12之前(包括M12)的消息被标记为acked。在图的底部,它显示了单独进行acking的示例。仅确认消息M7和M12 - 在消费者故障的情况下,除了M7和M12之外,将重新传送所有消息。
独占或故障转移订阅的消费者能够单独或累积地发送消息; 而共享订阅中的消费者只允许单独发送消息。单独确认消息的能力提供了处理消费者故障的更好体验。对于某些应用程序来说,防止重新传送已经确认的消息是非常重要的,因为对于那些处理消息的应用程序可能需要很长时间或者资源。
选择订阅类型和确认方法的灵活性允许Pulsar在简单的统一API中支持各种消息传递和流式使用案例。
信息保留
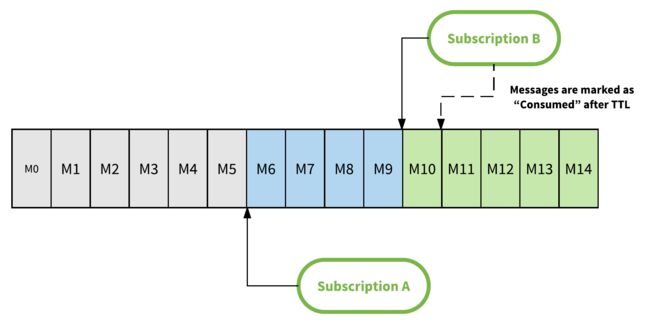
与传统的消息传递系统相比,消息被确认后不会立即删除。Pulsar broker只在接收到消息确认时更新游标。消息只能在所有订阅都已使用之后删除(消息在其游标中被标记为已确认)。然而Pulsar还允许您保存消息更长的时间,即使所有订阅已经消费了它们。以上通过配置消息保留期来实现的。图6演示了消息保留在包含两个订阅的主题分区中的情况。订阅A已经使用了M6之前的所有消息,订阅B已经使用了M10之前的所有消息。这意味着M6之前的所有消息(在灰色框中)都可以安全地删除。订阅A仍然没有使用M6和M9之间的消息,无法删除它们。
如果一个主题分区配置了一个消息保留期,就算a和b已经消费了M0到M5的消息,但也在配置的时间段内保留。
TTL
除了消息保留,Pulsar还支持消息存活时间(TTL)。如果在配置的TTL时间段内没有任何消费者使用消息,则消息将自动标记为已确认。消息保留和消息TTL的区别在于,消息保留适用于标记为已确认并设置为要删除的消息。保留是对主题应用的时间限制,而TTL则应用于未使用的消息。
因此,TTL是订阅的消费时间限制。上面的图6说明了Pulsar中的TTL。例如,如果订阅B的消费者没有消费,即使没有消费者真正读过消息,消息M10也会在配置的TTL时间段结束后自动标记为已确认。
Comparison(对比)
| Kafka | Pulsar | |
| 概念 | 生产者-主题-消费者/消费者组 | 生产者-主题-订阅-消费者 |
| 消费 | 更关注分区上的流和独占消息传递。没有共同的消费。 | 统一消息模型和API。
|
| ACK | 简单的offset管理
|
统一消息模型和API。
|
| Retention | 基于保留删除消息。如果使用者在保留期之前没有读取消息,则会丢失数据。 | 只有在所有订阅使用消息之后才会删除它们。没有数据丢失,甚至订阅的消费者也长时间处于下降状态。 即使在所有订阅都使用消息之后,也允许将消息保存一段已配置的保留期间。 |
| TTL | 支持 | 不支持 |
Apache Pulsar将高性能流(Apache Kafka追求的)和灵活的传统队列(RabbitMQ追求的)结合到一个统一的消息模型和API中。Apache Pulsar使用统一的API,为流媒体和排队提供了一个性能相同的系统。
小结
在这篇文章中,介绍了Apache Pulsar的消息模型,它将队列和流统一到一个API中。应用程序可以将此单一API用于高性能队列和流,而无需设置开销,例如RabbitMQ用于队列,Kafka用于流。