菜鸟de大数据之路——(1)Kaggle数据集Titanic分析
前言
Kaggle是一个2010年由Anthony Goldbloom创建的专门为数据科学服务的网站,提供数据科学竞赛,数据库托管,编写和代码分享服务,堪称数据科学家的交友平台。今天,我将试图解决Kaggle上面的经典入门问题——Titianic竞赛https://www.kaggle.com/naresh31/titanic-machine-learning-from-disaster。这个竞赛的主要目的是根据已有的训练集的存活数据,预测测试集的存活数据。下面我将具体介绍数据分析的七个步骤:
一,引入需要的库和数据集
1.引入需要的库
python提供了大量的用于数据处理,绘制图像的库,其中最常用的是pandas,numpy,matplotlib,seaborn这些,运用这些基础的库,我们可以方便的操作数据,分析数据。
#import essential modules for data analysis and data visualization
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import os2.导入数据
Titanic数据集有两个部分组成:训练数据集train.csv和测试数据集test.csv,可以从Kaggle网站下载https://www.kaggle.com/c/titanic/data。需要完成的任务是,根据训练数据集去预测测试数据集的人员存活率,保存到csv文件中。可以用pandas的read_csv方法实现,将数据保存到一个DataFrame数据结构中。
#Importing the datasets
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")3. 数据分析
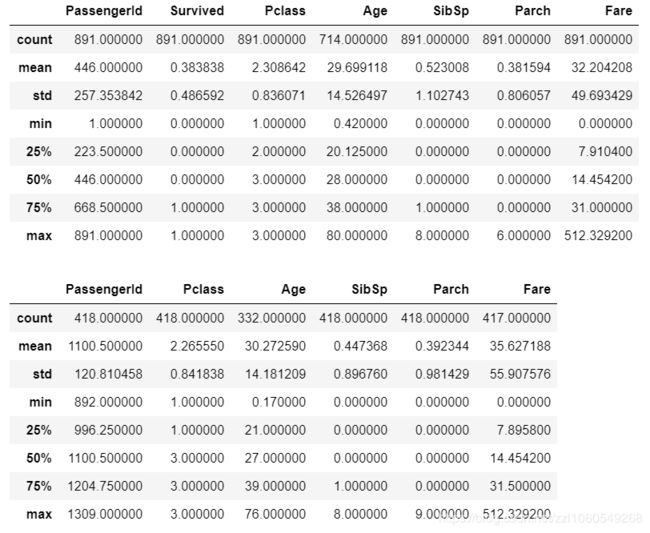
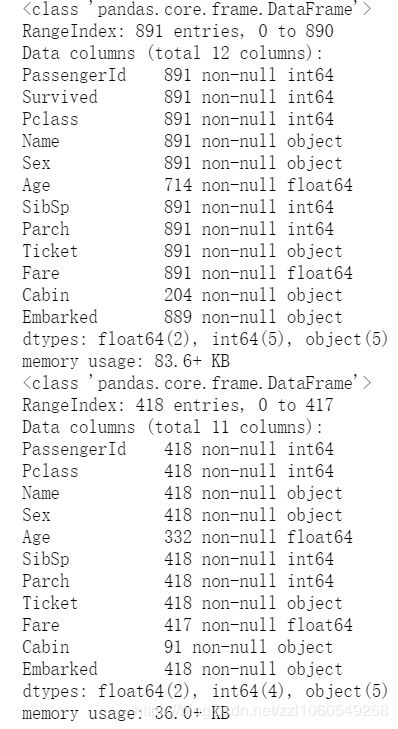
首先看一下train.csv和test.csv的数据组成,可以用pandas的sample方法。也可以用describe和info方法看一看数据的详细信息。
# Let's take a look!
display(train.sample(5),test.sample(5),train.describe(),test.describe(),train.info(),test.info())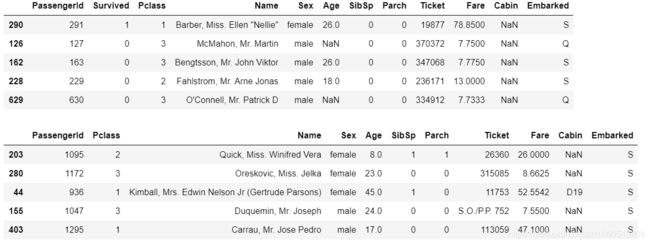
通过基本的分析,可以得到以下结论:
1.训练数据集和测试数据集差了一个suivived属性,也就是我们的预测目标。
2.数据存在缺失,具体来说,Age,Cabin,Embarked,Fare属性存在缺失,需要进行数据补充。
3.Fare这一列的数据非常不均匀,可能需要进行规整或者其他操作。
4.数据类型
Titanic数据主要包括下面几种数据类型:
- Categorical
- Nominal(Cabin,Embarked)
- Dichotomous(Sex)
- Ordinal(Pclass)
- Numeric
- Discrete(PassengerId,SibSp,Parch,Survived)
- Continuous(Age,Name)
5.数据展示
下面用Tableau工具可视化一下数据:
%%HTML
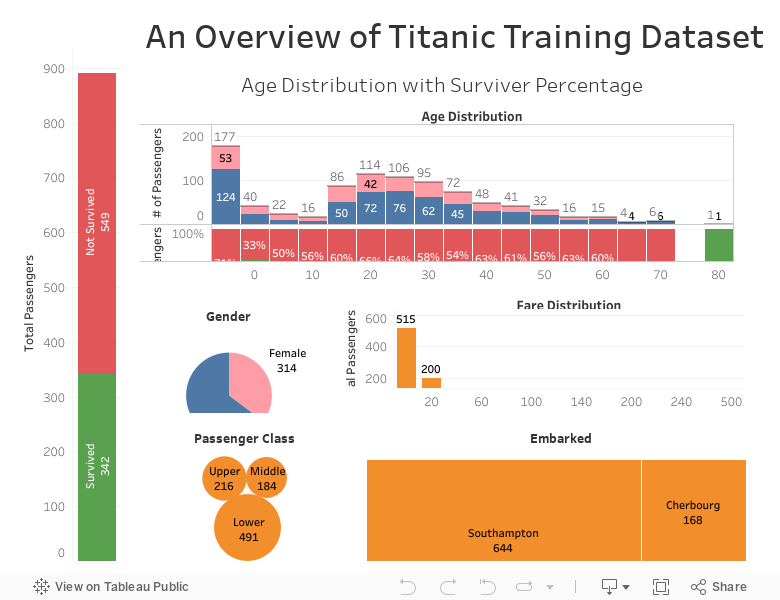
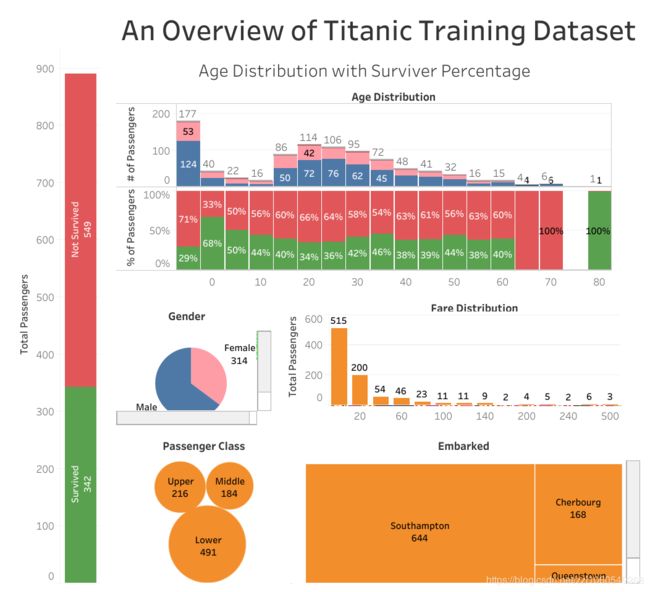
通过Tableau的可视化图表,我们可以看出,尽管三等船舱的乘客数量是最多的,但是获救的人中,一等舱的乘客数量反而是最多的,乘船人数女性少于男性,但是获救的女性大于男性数量,同时获救的儿童比例很大,部分和Titanic电影中的台词"女士和儿童优先"吻合。
二,数据填充
1.Embarked填充
首先看一下Embarked数据的整体分布:
percent = pd.DataFrame(round(train.Embarked.value_counts(dropna=False, normalize=True)*100,2))
total = pd.DataFrame(train.Embarked.value_counts(dropna=False))
total.columns = ["Total"]
percent.columns = ['Percent']
pd.concat([total, percent], axis = 1)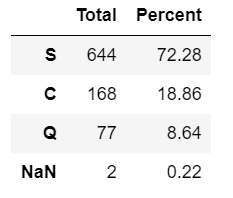
可以简单的看出,大部分的Embarked数据是S,总共缺少2条数据,我们可以选择以S进行填充,但是我们可以进一步分析一下数据,首先看一下这俩条数据到底是什么:
train[train.Embarked.isnull()]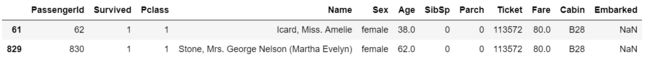
下面我们可以从Fare,Pclass,Embarked的分布中探索一下可能的分布:
fig, ax = plt.subplots(figsize=(16,12),ncols=2)
ax1 = sns.boxplot(x="Embarked", y="Fare", hue="Pclass", data=train, ax = ax[0]);
ax2 = sns.boxplot(x="Embarked", y="Fare", hue="Pclass", data=test, ax = ax[1]);
ax1.set_title("Training Set", fontsize = 18)
ax2.set_title('Test Set', fontsize = 18)
fig.show()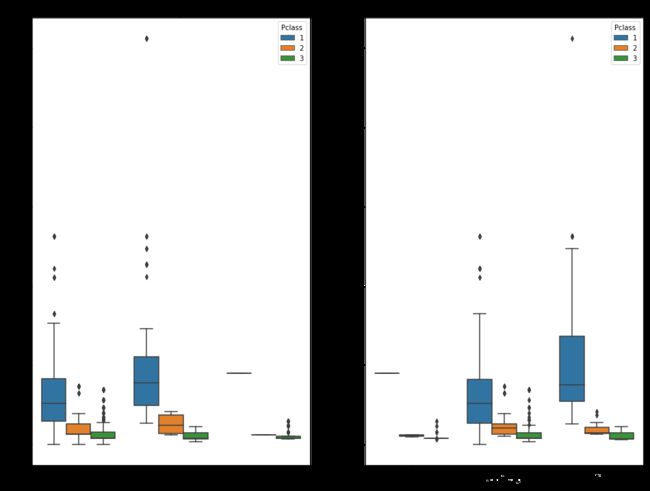
可以看出,不管是在train还是test数据中,当Fare接近80$,大部分一等舱的乘客上船地点是C港口,因此我们选择C港口作为填充数据。我们可以这样分析的主要原因是考虑到邮轮的价格主要和乘船距离和客舱级别有关,因此,相同的价格和相同的客舱级别应当对应相同的上船地点。
train.Embarked.fillna('C',inplace=True)2.Cabin填充
Cabin数据不管是在train还是在test中都有大量的缺失,比例达到77%,比较简单的方法是直接drop这一列,因为这一列能提供的信息很少,或者简单的按照是否有Cabin进行重新分类,但是这样我们就损失掉了Cabin列包含的信息。考虑到数据集本身比较简单,因此我们进一步探索Cabin列的特点,可以看出Cabin列由字母和数字组成,如果我们拆分出字母,按照Fare进行分类,我们可以发现Cabin列的首字母标识了Fare的高低。
#Concat train and test into a all_data
survivers = train.Survived
train.drop(["Survived"],axis=1, inplace=True)
all_data = pd.concat([train,test], ignore_index=False)
#using N to fillna
all_data.Cabin.fillna("N", inplace=True)
all_data.Cabin = [i[0] for i in all_data.Cabin]
#dig deeper
with_N = all_data[all_data.Cabin == "N"]
without_N = all_data[all_data.Cabin != "N"]
all_data.groupby("Cabin")['Fare'].mean().sort_values()
所以我们可以根据Fare填充Cabin的值:
def cabin_estimator(i):
a = 0
if i<16:
a = "G"
elif i>=16 and i<27:
a = "F"
elif i>=27 and i<38:
a = "T"
elif i>=38 and i<47:
a = "A"
elif i>= 47 and i<53:
a = "E"
elif i>= 53 and i<54:
a = "D"
elif i>=54 and i<116:
a = 'C'
else:
a = "B"
return a
with_N['Cabin']=with_N.Fare.apply(lambda x: cabin_estimator(x))3.Fare填充
在test数据集中Fare存在一个缺失,我们首先看一下缺失数据的情况,然后根据具体情况,选择适合的某些数据取平均值进行填充:
print(test[test.Fare.isnull()])
test.Fare.fillna(test[(test.Pclass==3)&(test.Sex=="male")&(test.Embarked=="S")].Fare.mean(),inplace=True)4.Age填充
Age数据在Test和train数据中缺失的比例都约在20%,根据之前的分析,Age对于预测生存率有很重要的作用,所以我们不能简单的进行均值填充,在此我们采用随机森林回归器进行预测,这一部分在后面的特征工程里面进行实际操作。
三,可视化和数据关联分析
四,统计分析
五,特征工程
六,训练前步骤
七,选择模型训练
八,提交结果