NLTK学习之一:简单文本分析
nltk的全称是natural language toolkit,是一套基于python的自然语言处理工具集。
1 NLTK的安装
nltk的安装十分便捷,只需要pip就可以。
pip install nltk在nltk中集成了语料与模型等的包管理器,通过在python解释器中执行
>>> import nltk
>>> nltk.download()便会弹出下面的包管理界面,在管理器中可以下载语料,预训练的模型等。
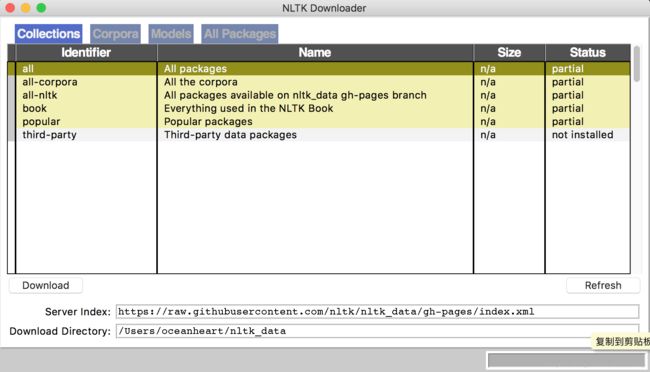
2 对文本进行简单的分析
2.1 Text类介绍
nltk.text.Text()类用于对文本进行初级的统计与分析,它接受一个词的列表作为参数。Text类提供了下列方法。
| 方法 | 作用 |
|---|---|
| Text(words) | 对象构造 |
| concordance(word, width=79, lines=25) | 显示word出现的上下文 |
| common_contexts(words) | 显示words出现的相同模式 |
| similar(word) | 显示word的相似词 |
| collocations(num=20, window_size=2) | 显示最常见的二词搭配 |
| count(word) | word出现的词数 |
| dispersion_plot(words) | 绘制words中文档中出现的位置图 |
| vocab() | 返回文章去重的词典 |
nltk.text.TextCollection类是Text的集合,提供下列方法
| 方法 | 作用 |
|---|---|
| nltk.text.TextCollection([text1,text2,]) | 对象构造 |
| idf(term) | 计算词term在语料库中的逆文档频率,即 log总文章数文中出现term的文章数 |
| tf(term,text) | 统计term在text中的词频 |
| tf_idf(term,text) | 计算term在句子中的tf_idf,即tf*idf |
2.2 示例
下面我们对青春爱情小说《被遗忘的时光》做下简单的分析。首先加载文本:
import ntlk
import jieba
raw=open('forgotten_times.txt').read()
text=nltk.text.Text(jieba.lcut(raw))对于言情小说,先看下风花雪月这样的词出现的情况
print text.concordance(u'风花雪月')输出如下:
>>> Displaying 2 of 2 matches:
彼时 校园 民谣 不复 大热 了 , 但 处身 校园 , 喜欢 吟唱 风花雪月 的 感性 青年 还是 喜欢 借此 抒怀 。 邵伊敏 平常 听 英语歌 较
的 眼睛 看 的 是 自己 , 迷恋 的 却 多半 只是 少女 心中 的 风花雪月 , 而 迷恋 过后 不可避免 不是 失望 就是 幻灭 。 他 将 目光再看下作者对于某些同义词的使用习惯
print text.common_contexts([u'一起',u'一同'])输出如下:
>>> 爷爷奶奶_生活 在_时下面看下文章常用的二词搭配
text.collocations()输出
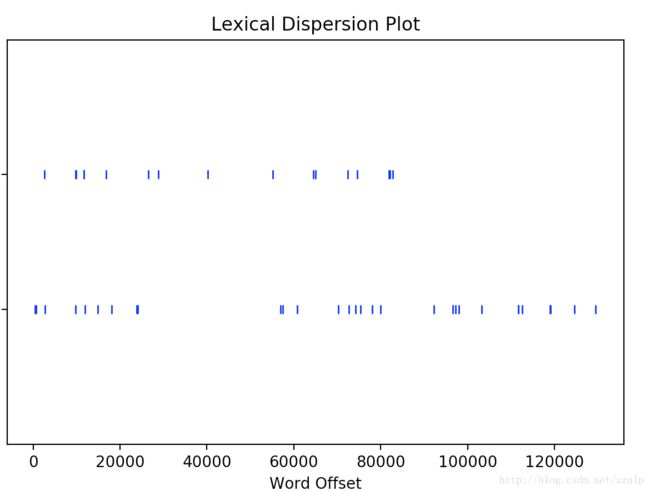
出入境 管理处; 沃尔沃 XC90; 慢吞吞 爬起来; 没交过 男朋友; 邵伊敏 回头一看; 戴维凡 哭笑不得; 没想到 邵伊敏; 邵伊敏 第二天; 邵伊敏 没想到查看关心的词在文中出现的位置
text.dispersion_plot([u'校园',u'大学'])输出如下图:
3 对文档用词进行分布统计
3.1 FreqDist类介绍
这个类主要记录了每个词出现的次数,根据统计数据生成表格,或绘图。其结构很简单,用一个有序词典进行实现。所以dict类型的方法在此类也是适用的。如keys()等。
| 方法 | 作用 |
|---|---|
| B() | 返回词典的长度 |
| plot(title,cumulative=False) | 绘制频率分布图,若cumu为True,则是累积频率分布图 |
| tabulate() | 生成频率分布的表格形式 |
| most_common() | 返回出现次数最频繁的词与频度 |
| hapaxes() | 返回只出现过一次的词 |
3.2 示例
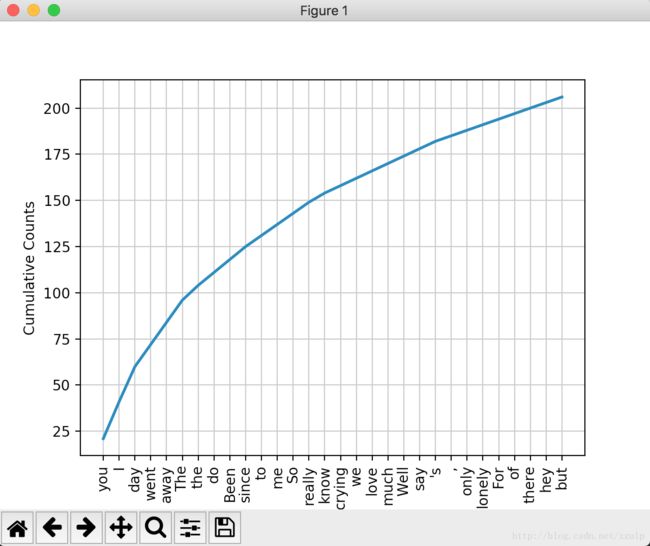
对歌曲《The day you went away》的歌词进行分析。
text = open('corpus/the_day_you_went_away.txt').read()
fdist = nltk.FreqDist(nltk.word_tokenize(text))
fdist.plot(30,cumulative=True)代码第二行调用了word_tokenize()函数,此函数的作用是基于空格/标点等对文本进行分词,返回分词后的列表。如果要处理中文,需要三方的分词器先处理,之后才能使用nltk进行处理。运行输出分布图如下:
4 nltk自带的语料库
在nltk.corpus包下,提供了几类标注好的语料库。见下表:
| 语料库 | 说明 |
|---|---|
| gutenberg | 一个有若干万部的小说语料库,多是古典作品 |
| webtext | 收集的网络广告等内容 |
| nps_chat | 有上万条聊天消息语料库,即时聊天消息为主 |
| brown | 一个百万词级的英语语料库,按文体进行分类 |
| reuters | 路透社语料库,上万篇新闻方档,约有1百万字,分90个主题,并分为训练集和测试集两组 |
| inaugural | 演讲语料库,几十个文本,都是总统演说 |
更多语料库,可以用nltk.download()在下载管理器中查看corpus。
4.1语料库处理
| 方法明 | 说明 |
|---|---|
| fileids() | 返回语料库中文件名列表 |
| fileids[categories] | 返回指定类别的文件名列表 |
| raw(fid=[c1,c2]) | 返回指定文件名的文本字符串 |
| raw(catergories=[]) | 返回指定分类的原始文本 |
| sents(fid=[c1,c2]) | 返回指定文件名的语句列表 |
| sents(catergories=[c1,c2]) | 按分类返回语句列表 |
| words(filename) | 返回指定文件名的单词列表 |
| words(catogories=[]) | 返回指定分类的单词列表 |
5 文本预处理
NLP在获取语料之后,通常要进行文本预处理。英文的预处理包括:分词,去停词,提取词干等步骤。中文的分词相对于英文更复杂一些,也需要去停词。但没有提取词干的需要。
对于英文去停词的支持,在corpus下包含了一个stopword的停词库。
对于提取词词干,提供了Porter和Lancaster两个stemer。另个还提供了一个WordNetLemmatizer做词形归并。Stem通常基于语法规则使用正则表达式来实现,处理的范围广,但过于死板。而Lemmatizer实现采用基于词典的方式来解决,因而更慢一些,处理的范围和词典的大小有关。
porter = nltk.PorterStemmer()
porter.stem('lying') #'lie'
lema=nltk.WordNetLemmatizer()
lema.lemmatize('women') #'woman'