关于opencv中 tf_text_graph_ssd.py生成pbtxt报错的解决方案
opencv中的dnn模块很强大,可以加载现在主流的深度学习模型,darknet、caffe、tensorflow等,我本人最近在使用tensorflow进行目标检测,用的是ssdlite-mobilenet-v2。tensorflow的object_detection api使用起来很方便,而且大佬研究出来的模型也都没毛病,效果很好,换换数据集,调调参数就ok。训练过程不再本篇博客的讨论范围内,假定现在已经训练完毕,并且生成了pb文件。
一般我们恢复模型都是要用到tensorflow,大致代码如下所示:
import numpy as np
import tensorflow as tf
import cv2 as cv
# Read the graph.
with tf.gfile.FastGFile('frozen_inference_graph.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Session() as sess:
# Restore session
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
# Read and preprocess an image.
img = cv.imread('example.jpg')
rows = img.shape[0]
cols = img.shape[1]
inp = cv.resize(img, (300, 300))
inp = inp[:, :, [2, 1, 0]] # BGR2RGB
# Run the model
out = sess.run([sess.graph.get_tensor_by_name('num_detections:0'),
sess.graph.get_tensor_by_name('detection_scores:0'),
sess.graph.get_tensor_by_name('detection_boxes:0'),
sess.graph.get_tensor_by_name('detection_classes:0')],
feed_dict={'image_tensor:0': inp.reshape(1, inp.shape[0], inp.shape[1], 3)})
# Visualize detected bounding boxes.
num_detections = int(out[0][0])
for i in range(num_detections):
classId = int(out[3][0][i])
score = float(out[1][0][i])
bbox = [float(v) for v in out[2][0][i]]
if score > 0.3:
x = bbox[1] * cols
y = bbox[0] * rows
right = bbox[3] * cols
bottom = bbox[2] * rows
cv.rectangle(img, (int(x), int(y)), (int(right), int(bottom)), (125, 255, 51), thickness=2)
cv.imshow('TensorFlow MobileNet-SSD', img)
cv.waitKey()如果电脑没有tensorflow想要恢复模型怎么办?那就可以考虑下opencv了,opencv加载tensorflow模型需要pb文件和pbtxt文件,pbtxt是可以根据pb文件生成的,在opencv的源代码中进入sample/dnn 文件夹中,由于我们的模型是ssd因此找到以下两个文件
tf_text_graph_ssd.py
tf_text_graph_common.py
在命令行执行
python tf_text_graph_ssd.py --input ssdlite.pb --config pipeline.config --output ssdlite.pbtxt
ssdlite.pb是自己训练的pb模型,pipeline是训练时的配置文件,生成pb时会有,ssdlite.pbtxt就是生成的文件用于opencv恢复模型
但是我本人在这里运行时报错了,如下图所示:
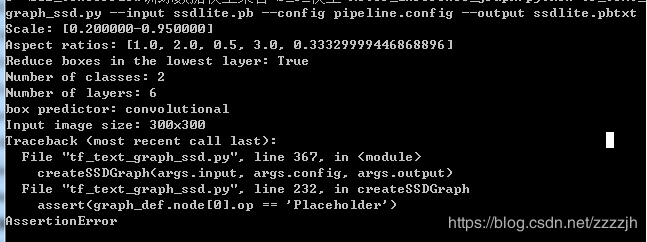
在github中有人提到训练完的模型需要转换一下
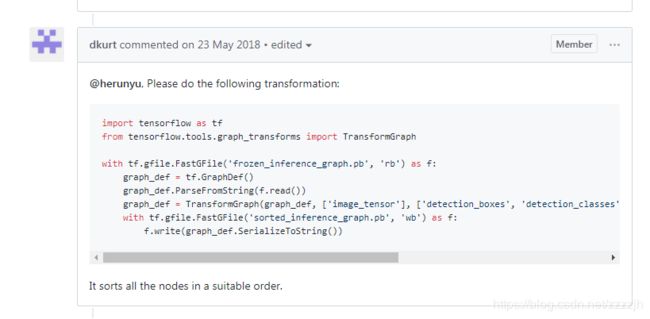
import tensorflow as tf
from tensorflow.tools.graph_transforms import TransformGraph
with tf.gfile.FastGFile('ssdlite.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
graph_def = TransformGraph(graph_def, ['image_tensor'], ['detection_boxes', 'detection_classes', 'detection_scores', 'num_detections'], ['sort_by_execution_order'])
with tf.gfile.FastGFile('ssdlite_new.pb', 'wb') as f:
f.write(graph_def.SerializeToString())#保存新的模型转化完pb模型之后再运行上面的代码,成功生成pbtxt文件
然后用opencv恢复模型
net = cv2.dnn.readNetFromTensorflow(weightsPath,configPath)
大致代码如下:
import cv2 as cv
cvNet = cv.dnn.readNetFromTensorflow('frozen_inference_graph.pb', 'graph.pbtxt')
img = cv.imread('test.jpg')
rows = img.shape[0]
cols = img.shape[1]
cvNet.setInput(cv.dnn.blobFromImage(img, size=(300, 300), swapRB=True, crop=False))
cvOut = cvNet.forward()
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
if score > 0.3:
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (23, 230, 210), thickness=2)
cv.imshow('img', img)
cv.waitKey()在此需要感谢dkurt大神的转换代码,顺便提一下ssdlite的速度是真的快,pc端cpu下大约60ms一帧,如果需要移植到arm平台上,可借助腾讯的ncnn,在移动端加速效果也是很棒的。
参考的一些资料:
https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API
https://github.com/opencv/opencv/issues/11560