使用python来进行用户流失预测的实战
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Carl Dawson
编译:ronghuaiyang
导读
借用生存分析的方法来进行用户流失的预测,用到了Cox Proportional Hazards模型。
客户流失率很难预测。在你能做一些事情来阻止客户离开之前,你需要知道,谁将离开,什么时候离开,这将在多大程度上影响你的业务。在这篇文章中,我将解释使用生存分析来预测和预防流失的技术。
客户会不会流失
许多数据分析师试图用黑白分明的方式来模拟这个问题:客户流失vs客户没有流失。我们很容易用这种方式来看待这个问题,因为它是一种我们都知道的模型 —— 监督分类。
但是这样做忽略了客户流失预测问题的许多细微之处 —— 风险、时间线、客户离开的成本等等。
不管怎样,让我们从一个分类模型开始,看看我们最终的结果。
我们的数据集
我们使用的数据集是Kaggle Telco Churn dataset:https://www.kaggle.com/c/telco-churn/data,它包含超过7000个客户的记录,包括特征,比如客户的每月费用,成为客户的时长(几个月),是否有各种附加互联网服务等等。
以下是前5行:
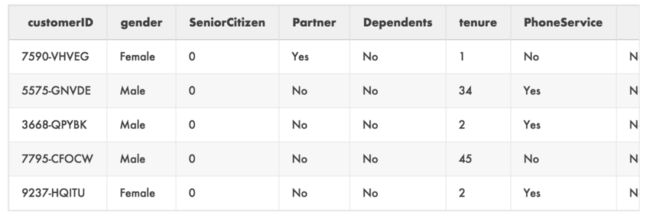
首先你会注意到有很多类别变量为文本值(' Yes ', ' No ',等等),我们使用pd.get_dummies来修复这些:
dummies = pd.get_dummies(
data[[ 'gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'Churn' ]]
)
data = dummies.join(data[['MonthlyCharges', 'TotalCharges']])
如果你按照下面的步骤去做,你还需要修复total charge列中的一些缺失值,这些值使整列变成了文本而不是数字:
data['TotalCharges'] = data[['TotalCharges']].replace([' '], '0')
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'])
现在我们有了一个可用的数据格式,我们把它可视化一下:
from matplotlib import pyplot as plt
plt.scatter( data['tenure'], data['MonthlyCharges'], c=data['Churn_Yes'])
plt.xlabel('Customer Tenure (Months)')
plt.ylabel('Monthly Charges')

很难从这张图中得出任何结论,这个图将客户的tenure(我们正在努力改进的东西)与他们的月费进行了比较。我们继续去训练一个逻辑回归模型,看看我们是否可以使用这些虚拟的特征来预测客户的流失。
逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
X_train, X_test, y_train, y_test = train_test_split(data[x_select], data['Churn_Yes'])
clf = LogisticRegression(solver='lbfgs', max_iter=1000) clf.fit(X_train, y_train)
如果我们训练一个模型,不做任何类间平衡或样本的加权,我们可以达到79.9%的准确率。这对于第一次尝试来说还不错。
下面是Logistic回归模型的混淆矩阵:

你在这里看到的是,虽然总体的准确性是相当高的,但是这个模型只识别出流失用户中的55%,这比我们想要的更接近于随机。
我们的目标是什么?
在这个过程中,大多数数据科学家(包括我自己)会加倍努力,通过设计新特征、尝试不同的算法、平衡数据集等等来提高模型的准确性。但是最好停下来问问自己你的最终目标是什么。
了解每一位将要流失的客户固然很好,但这些信息究竟能带来多少真正有用的信息呢?如果你想留住他们,你怎么知道该关注什么?在他们成为你的亏损客户之前,你需要花多少钱才留住他们?
让我们试着从不同的角度看问题。
生存分析
逻辑回归所做的是为每个描述它属于正类的可能性的样本分配一个概率。
在预测流失vs不流失的这种情况下,对于任何类型的分类,都有一个小烦恼,我们必须选择一个阈值(比如0.5,<0.5就是0, >=0.5 就是1)。然而,如果你仔细想想,其实这个概率才是我们想要的。
在任何足够大的客户群体中,都会有具有相同属性/特征的人(这就是鸽子洞原理)。有些会流失,有些不会,理想情况下,你想知道的是每个组的流失概率。这就是Logistic回归所给出的结果,但是在这种情况下,使用Logistic回归确实有一个问题 —— 不清楚它预测的时间范围。所以我们现在进入生存分析。
生存分析是一套用于生命科学(主要是流行病学和药物研究)的方法,用于确定患者随时间的生存概率。这是一个非常大的问题,有许多复杂的统计工具,但我们将只使用其中之一 —— Cox比例风险模型。
Cox比例风险模型
Cox PH模型是一种基于回归的模型,它分析数据集关于病人(或客户)生存时间的协变量(特征)。它被称为比例风险模型,因为它描述了每个特征如何在基线存活率上按比例增加风险的。
由于Python中有一个lifelines包,具有很好的文档,所以很容易使用Cox PH模型。
使用CoxPH模型
在大多数情况下,你需要做的第一件事,你需要用数据集准备好Cox回归模型的两个特征:
“age”(病人开始服药和最近一次观察他们的状态之间的时间差异,在我们的例子中,为顾客加入服务的时间和最近一次观察他们是否流失之间的时间差异)
“event”(表示事件是否发生的二进制标志,如死亡或流失)
幸运的是,telco数据集已经在tenure和Churn列中设计了这两个特征。
在进行任何类型的基于矩阵的回归时,需要注意的一件重要事情是,在Python中,奇异矩阵(行列式不为0,也就是说有两列变量是线性相关的)会抛出一个错误。所有这一切意味着,当你创建虚拟变量(one-hot编码)时,你必须扔掉其中的一列。
以下是我们的简化数据集的前5行:
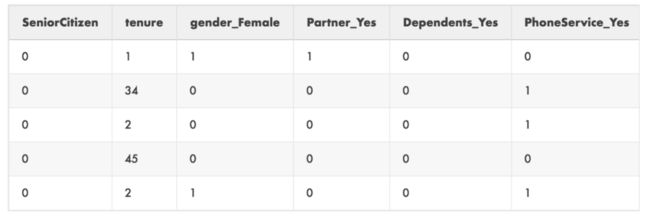
可以看到,Gender_Male已经消失,Partner_No、Dependents_No等等也消失了。
现在我们有了正确格式的数据集,让我们来拟合Cox模型:
from lifelines import CoxPHFitter
cph_train, cph_test = train_test_split(data[x_select], test_size=0.2)
cph.fit(cph_train, 'tenure', 'Churn_Yes')
lifelines包有一些独特之处,可能会给使用惯了Scikit-Learn的用户带来一些麻烦,首先,包含churn的列需要包含在传递给fit调用的数据集中。因此,我们不能像在逻辑回归中那样将数据集分成四份(对X和y进行训练和测试),我们必须将其分成两份。这与R语法非常相似,你可以在单个数据集中指定相关的列,而算法会负责将它们从训练数据中删除。
cph.fit调用的时候,你需要传入三个不同的参数。第一个是我们使用train_test_split创建的数据集,第二个是‘age’列(在我们的例子中是tenure),第三个是'event'列(在我们的例子中是Churn_Yes)。
lifelines包的下一个独特之处是可以在模型上使用的.print_summary方法(另一个从R借鉴的方法)。
下面是我们的模型summary:
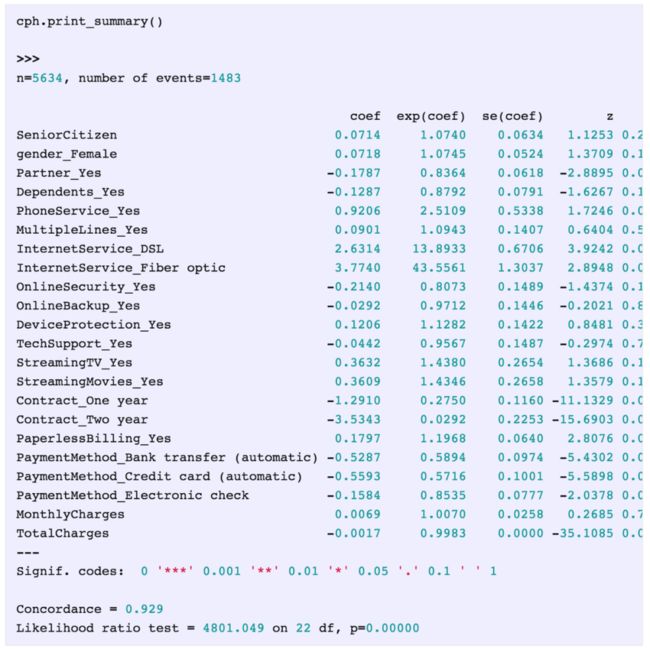
关于这个输出,有几件重要的事情需要注意。
我们可以看到在输出的顶部列出了n=5634的样本数量,在其旁边是我们的event数量(流失的客户)。
我们得到了模型的系数。这些是非常重要的,它们告诉我们每个特征是如何“增加”风险的,因此,如果系数是一个正数,那么该特征使客户更有可能流失,如果是负数,那么拥有该特征的客户就不太可能流失。
我们可以得到特征的显著性值,一个非常好的补充!
我们得到了一致性。
一致性
与使用准确性来比较逻辑回归模型类似,你可以使用一致性比较不同的Cox PH模型。
简单地说,一致性是对模型内部一致性的评估 —— 如果它说某个特征增加了风险,那么具有该特征的观测结果应该风险会高。如果它们是这样的,那么一致性会上升,如果不是,那么一致性会下降。
我们的模型的一致性是0.929,总分是1,所以它是一个很好的Cox模型。
Cox模型绘图
在模型上调用基础的.plot可以得到:
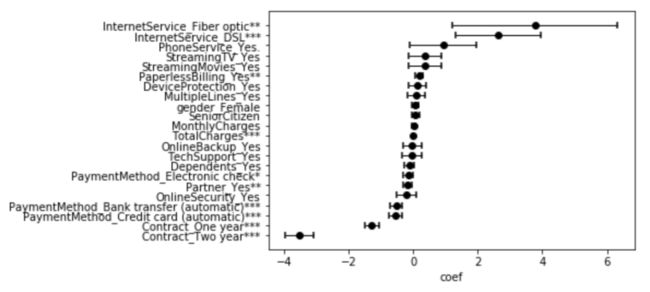
一个方便的特征重要性的可视化和各种特征的风险的影响。在这一点上,我们还可以做的是调查这些特征是如何影响生存的,就像这样:
cph.plot_covariate_groups('TotalCharges', groups=[0,4000])
.plot_covariate_groups是 lifelines 中的一个方法,第一个输入是特征的名字,第二个是组的范围。所以,这里我们看的是客户的Total Charges接近0以及Total Charges接近4000的生存曲线的对比,看起来是这样:
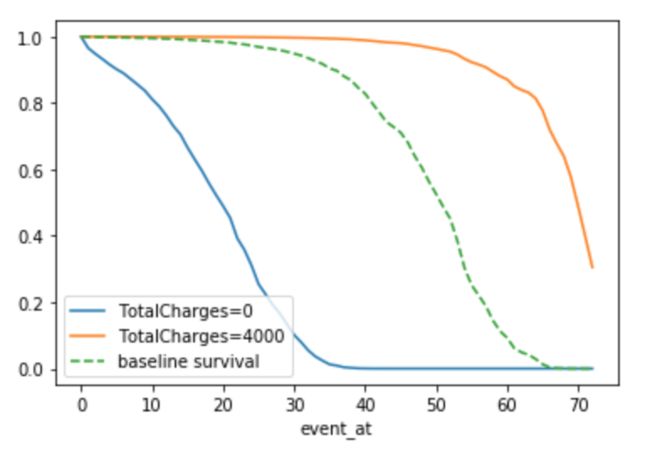
你可以看到,总开销接近于零的客户比总开销接近于4000的客户面临更高的风险(生存曲线下降)。
流失预测
我们有一个好的,有效的模型,现在呢?
这个练习的目的是获得一些有用的信息,帮助我们做出关于如何进行干预以减少和防止客户流失的决策。我们来做一些预测。
不幸的是,对于已经流失的客户,我们能做的不多,所以让我们从数据集中只选择剩下的客户:
censored_subjects = data.loc[data['Churn_Yes'] == 0]
我们选择所有那些尚未流失的客户。现在我们用简便的方法来预测它们的生存曲线。
unconditioned_sf = cph.predict_survival_function(censored_subjects)
你可以看到,我们将这个称为“无条件”生存函数,这是因为我们知道,其中一些曲线会在客户当前的留存期之前预测为客户会流失。我们必须在收集数据时知道客户还在的基础上设定预测条件:
conditioned_sf = unconditioned_sf.apply(lambda c: (c / c.loc[data.loc[c.name, 'tenure']]).clip_upper(1))
现在,我们可以调查个别顾客,看看这个调节如何影响他们的存活率,可以超过基线:
subject = 12
unconditioned_sf[subject].plot(ls="--", color="#A60628", label="unconditioned")
conditioned_sf[subject].plot(color="#A60628", label="conditioned on $T>58$") plt.legend()
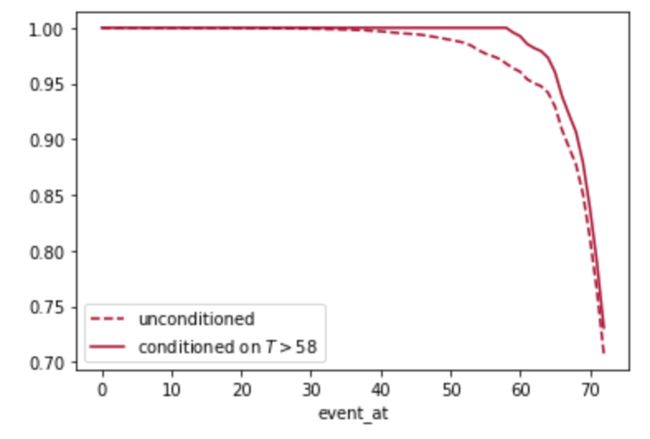
正如你所看到的,我们知道客户12在58个月后仍然是客户,这一事实意味着他的生存曲线下降的速度慢于与他相似的没有这种情况的客户的基线。
非常方便的predict_survival_function方法创建了一个矩阵,其中包含每个剩余客户在每个时间点的生存概率。接下来我们需要做的是选择一个单一的数字作为预测客户将留存多久,我们可以使用它来确定干预值。
根据用例,你可以选择任何百分比,但是对于我们的用例,我们将使用中位数。
from lifelines.utils import median_survival_times, qth_survival_times
predictions_50 = median_survival_times(conditioned_sf)
# This is the same, but you can change the fraction to get other
# %tiles.
# predictions_50 = qth_survival_times(.50, conditioned_sf)
我们在Dataframe中得到一个单个行,其中包含月的数量(留存期),其中客户有50%的可能性会进行交易。
我们可以使用这一行,通过将它与我们的数据DataFrame相连接,可以调查客户对业务的预期剩余价值:
values = predictions_50.T.join(data[['MonthlyCharges','tenure']])
values['RemainingValue'] = values['MonthlyCharges'] * (values[0.5] - values['tenure'])
下面是这个新DataFrame的前5行:
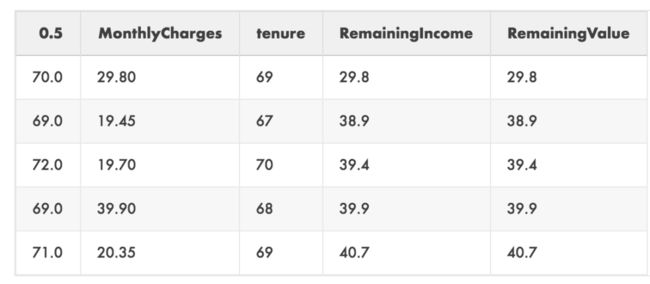
名为0.5的列是我们从median_survival_times调用中接收到的单个行。如果你选择了不同的百分比,则此列的名称将有所不同。
我们在这里看到的是,通过将每月的费用乘以客户当前的tenure与他们的取消日期中值之间的差值,我们可以了解到哪些客户会对我们的top line造成最大的损害。
流失预防
好了,现在我们知道了哪些客户的客户流失风险最高,但我们能做些什么来留住他们呢?如果我们回到之前的系数图我们可以看到对存活率有积极影响的最重要的特征是:
有2年的合同
有一年的合同
用信用卡付款
银行转帐付款
超过了这四种,存活率的增加就变得微乎其微,而且结果也不显著。我们来看看这四个。
我们需要做的是了解我们可以花多少钱来留住客户,是比较他们类似的客户的存活率,而不是他们的这四个特征:
upgrades = ['PaymentMethod_Credit card (automatic)', 'PaymentMethod_Bank transfer (automatic)', 'Contract_One year', 'Contract_Two year']
results_dict = {}
for customer in values.index:
actual = data.loc[[customer]] change = data.loc[[customer]]
results_dict[customer] = [cph.predict_median(actual)]
for upgrade in upgrades:
change[upgrade] = 1 if list(change[upgrade]) == [0] else 0
results_dict[customer].append(cph.predict_median(change))
change[upgrade] = 1 if list(change[upgrade]) == [0] else 0
results_df = pd.DataFrame(results_dict).T
results_df.columns = ['baseline'] + upgrades
actions = values.join(results_df).drop([0.5], axis=1)
我们在这里所做的是循环遍历客户,每次更改一个特征,并存储有此更改的客户的预期生存期中值。最后我们剩下的是:

我们可以看到,如果我们设法让第一个客户使用信用卡支付,我们可以增加4个月的生存时间(25-21基线),等等。
这是一个非常好的结果,它确实帮助我们看到我们如何才能在留住客户方面取得进展,但让我们更进一步,看看这在财务上有什么影响:
actions['CreditCard Diff'] = (
actions['PaymentMethod_Credit card (automatic)'] -
actions['baseline']
) * actions['MonthlyCharges']
actions['BankTransfer Diff'] = (
actions['PaymentMethod_Bank transfer (automatic)'] -
actions['baseline']
) * actions['MonthlyCharges']
actions['1yrContract Diff'] = (
actions['Contract_One year'] - actions['baseline']
) * actions['MonthlyCharges']
actions['2yrContract Diff'] = (
actions['Contract_Two year'] - actions['baseline']
) * actions['MonthlyCharges']

现在我们可以看到,将第一排的顾客转移到使用信用卡支付,价值可能高达119.40英镑。这比简单地数月的数量有用多了。
准确率以及校准
好了,快好了。我们有了货币价值,我们可以用它来判断特定的客户流失干预是否可行,以及关于“何时”客户会流失的可靠预测。但所有这些到底有多准确呢?
我们知道我们的Cox模型是一个很好的模型(92.9%的一致性),但这在实际中意味着什么呢?它有多精确?
当你从概率的角度看待像流失(或欺诈或盗窃)这样的事件时,检查校准性比检查准确性更重要。校准性是模型获得概率随时间变化的倾向。
就像这样,一个天气预报服务是经过校准的话,如果在所有的时间里它说有40%的可能性下雨,实际上就有40%的可能性下雨。
在Scikit-Learn中,我们可以使用calibration_curve方法从概率预测和数据集的真实值中获得这个值:
from sklearn.calibration import calibration_curve
plt.figure(figsize=(10, 10))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
probs = 1-np.array(cph.predict_survival_function(cph_test).loc[13])
actual = cph_test['Churn_Yes']
fraction_of_positives, mean_predicted_value = \
calibration_curve(actual, probs, n_bins=10, normalize=False)
ax1.plot(mean_predicted_value, fraction_of_positives, "s-", label="%s" % ("CoxPH",))
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05]) ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliability curve)')
可以得到这个:
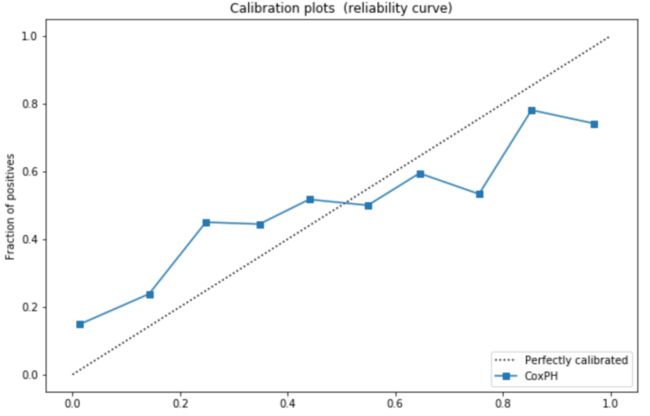
通过检查数据集(在我们的例子中是测试集)中出现的分数的各种概率,你可以看下这个图表。
你可以看到它非常接近对角线,代表完美的校准。然而,我们的模型似乎在低端低估了风险(<50%的流失率)和在高端轻微高估了风险(>50%的客户流失率)。
为了从数字上了解距离完美校准有多远,我们可以使用Scikit-Learn包中的brier_score_loss:
brier_score_loss(
cph_test['Churn_Yes'], 1 -
np.array(cph.predict_survival_function(cph_test).loc[13]), pos_label=1
)
敏锐的读者可能已经注意到,我的索引保持在tenure= 13。由于我们的模型在一定的时间范围内工作,我们必须在每一步都检查校准性,以获得准确的校准性:
loss_dict = {}
for i in range(1,73):
score = brier_score_loss(
cph_test['Churn_Yes'], 1 -
np.array(cph.predict_survival_function(cph_test).loc[i]),
pos_label=1 )
loss_dict[i] = [score]
loss_df = pd.DataFrame(loss_dict).T
fig, ax = plt.subplots()
ax.plot(loss_df.index, loss_df)
ax.set(xlabel='Prediction Time', ylabel='Calibration Loss', title='Cox PH Model Calibration Loss / Time')
ax.grid()
plt.show()
我们得到这个:

所以我们可以看到,我们的模型在5到25个月之间校准得很好,然后越来越差。为了使我们的分析更真实,剩下要做的唯一事情就是解释这种糟糕的校准性。
让我们为让客户做出改变所带来的预期投资回报创建一个上界和下界:
loss_df.columns = ['loss']
temp_df = actions.reset_index().set_index('PaymentMethod_Credit card (automatic)').join(loss_df)
temp_df = temp_df.set_index('index')
actions['CreditCard Lower'] = temp_df['CreditCard Diff'] - (temp_df['loss'] * temp_df['CreditCard Diff'])
actions['CreditCard Upper'] = temp_df['CreditCard Diff'] + (temp_df['loss'] * temp_df['CreditCard Diff'])
temp_df = actions.reset_index().set_index('PaymentMethod_Bank transfer (automatic)').join(loss_df)
temp_df = temp_df.set_index('index')
actions['BankTransfer Lower'] = temp_df['BankTransfer Diff'] - (.5 * temp_df['loss'] * temp_df['BankTransfer Diff']) actions['BankTransfer Upper'] = temp_df['BankTransfer Diff'] + (.5 * temp_df['loss'] * temp_df['BankTransfer Diff'])
temp_df = actions.reset_index().set_index('Contract_One year').join(loss_df)
temp_df = temp_df.set_index('index')
actions['1yrContract Lower'] = temp_df['1yrContract Diff'] - (.5 * temp_df['loss'] * temp_df['1yrContract Diff']) actions['1yrContract Upper'] = temp_df['1yrContract Diff'] + (.5 * temp_df['loss'] * temp_df['1yrContract Diff'])
temp_df = actions.reset_index().set_index('Contract_Two year').join(loss_df)
temp_df = temp_df.set_index('index')
actions['2yrContract Lower'] = temp_df['2yrContract Diff'] - (.5 * temp_df['loss'] * temp_df['2yrContract Diff']) actions['2yrContract Upper'] = temp_df['2yrContract Diff'] + (.5 * temp_df['loss'] * temp_df['2yrContract Diff'])
这里我们对之前的值打了个折来考虑校准的不确定性。我们查看模型在每个时间段的校准情况,我们预测会有一个特定的提升,并产生和创建一个投资回报的上下界。
这就得到了这样的结果:
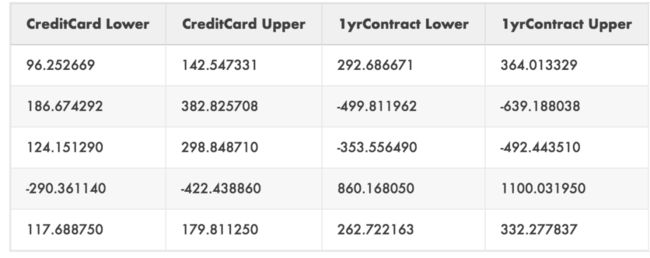
至此,我们结束了生存分析、一致性和校准性之旅。我们的努力所得到的是一组可操作的数据,我们可以使用这些数据使客户注册时间更长——这就是客户流失预测的要点!

—END—
英文原文:https://towardsdatascience.com/churn-prediction-and-prevention-in-python-2d454e5fd9a5?gi=df0e635db665

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!