《STL》— STL 知识点总结
C++:STL标准入门汇总
http://www.cnblogs.com/shiyangxt/archive/2008/09/11/1289493.html
stl 在 acm中的应用总结
http://www.cnblogs.com/shanyr/p/5745807.html
C++输入与输出—cout和cin的用法
http://blog.csdn.net/zhanghaotian2011/article/details/8868577
C++中string.find()函数与string::npos
http://www.cnblogs.com/web100/archive/2012/12/02/cpp-string-find-npos.html
find 函数和string :: npos 的用法
http://blog.csdn.net/stpeace/article/details/13069403
memcpy、memmove、memset、memchr、memcmp、strstr详解
http://www.cnblogs.com/jingliming/p/4737409.html
使用STL的next_permutation函数生成全排列(C++)
http://www.slyar.com/blog/stl_next_permutation.html
优先队列详解(转载)
http://www.cnblogs.com/heqinghui/archive/2013/07/30/3225407.html
STL 知识点总结
http://blog.csdn.net/liujiuxiaoshitou/article/details/76687226
C++中substr函数的用法
#include
#include
using namespace std;
main()
{
string s("12345asdf");
string a=s.substr(0,5); //获得字符串s中 从第0位开始的长度为5的字符串//默认时的长度为从开始位置到尾
cout<
一、LIST:
构造函数
list c0; //空链表
list c1(3); //建一个含三个默认值是0的元素的链表
list c2(5,2); //建一个含五个元素的链表,值都是2
list c4(c2); //建一个c2的copy链表
list c5(c1.begin(),c1.end()); ////c5含c1一个区域的元素[_First, _Last)。
成员函数
c.begin() 返回指向链表第一个元素的迭代器。
c.end() 返回指向链表最后一个元素之后的迭代器。
c.rbegin() 返回逆向链表的第一个元素,即c链表的最后一个数据。
c.rend() 返回逆向链表的最后一个元素的下一个位置,即c链表的第一个数据再往前的位置。
operator= 重载赋值运算符。
c.assign(n,num) 将n个num拷贝赋值给链表c。
c.assign(beg,end) 将[beg,end)区间的元素拷贝赋值给链表c。
c.back() 返回链表c的最后一个元素。
c.front() 返回链表c的第一个元素。
c.empty() 判断链表是否为空。
c.size() 返回链表c中实际元素的个数。
c.max_size() 返回链表c可能容纳的最大元素数量。
c.clear() 清除链表c中的所有元素。
c.insert(pos,num) 在pos位置插入元素num。
c.insert(pos,n,num) 在pos位置插入n个元素num。
c.insert(pos,beg,end) 在pos位置插入区间为[beg,end)的元素。
c.erase(pos) 删除pos位置的元素。
c.push_back(num) 在末尾增加一个元素。
c.pop_back() 删除末尾的元素。
c.push_front(num) 在开始位置增加一个元素。
c.pop_front() 删除第一个元素。
resize(n) 从新定义链表的长度,超出原始长度部分用0代替,小于原始部分删除。
resize(n,num) 从新定义链表的长度,超出原始长度部分用num代替。
c1.swap(c2); 将c1和c2交换。
swap(c1,c2); 同上。
c1.merge(c2) 合并2个有序的链表并使之有序,从新放到c1里,释放c2。
c1.merge(c2,comp) 合并2个有序的链表并使之按照自定义规则排序之后从新放到c1中,释放c2。
c1.splice(c1.beg,c2) 将c2连接在c1的beg位置,释放c2
c1.splice(c1.beg,c2,c2.beg) 将c2的beg位置的元素连接到c1的beg位置,并且在c2中施放掉beg位置的元素
c1.splice(c1.beg,c2,c2.beg,c2.end) 将c2的[beg,end)位置的元素连接到c1的beg位置并且释放c2的[beg,end)位置的元素
remove(num) 删除链表中匹配num的元素。
remove_if(comp) 删除条件满足的元素,参数为自定义的回调函数。
reverse() 反转链表
unique() 删除相邻的元素
c.sort() 将链表排序,默认升序
c.sort(comp) 自定义回调函数实现自定义排序
重载运算符
operator==
operator!=
operator<
operator<=
operator>
operator>= 二、set
begin() , 返回set容器的第一个元素
end() , 返回set容器的最后一个元素
clear() , 删除set容器中的所有的元素
empty() , 判断set容器是否为空
max_size() , 返回set容器可能包含的元素最大个数
size() , 返回当前set容器中的元素个数
rbegin , 返回的值和end()相同
rend() , 返回的值和rbegin()相同
count() 用来查找set中某个某个键值出现的次数。这个函数在set并不 是很实用,因为一个键值在set只可能出现0或1次,这样就变了 判断某一键值是否在set出现过了。
Count_if(first,end,condition) 查找满足condition(函数的形式)的次数
1. vector::size_type result1 = count_if(v1.begin(), v1.end(), greater10); bool greater10(int value) {
2. return value >10;
3.}
例子:cout<<"set 中 1 出现的次数是 :"<::iterator,bool>,bool标志着插入是否成功,而iterator代表插入的位置,若key_value已经在set中,则iterator表示的key_value在set中的位置。
inset(first,second); 将定位器first到second之间的元素插入到set中,返回值是void.
lower_bound(key_value),返回第一个大于等于key_value的定位器
upper_bound(key_value),返回最后一个大于等于key_value的定位器 三、vector:
at() 返回指定位置的元素
back() 返回最末一个元素
end() 返回最末元素的迭代器(译注:实指向最末元素的下一个位置)
capacity() 返回vector所能容纳的元素数量(在不重新分配内存的情况下)
clear() 清空所有元素
empty() 判断Vector是否为空(返回true时为空)
erase() 删除指定元素
c.erase(beg,end)
front() 返回第一个元素
insert() 插入元素到Vector中
max_size() 返回Vector所能容纳元素的最大数量(上限)
pop_back() 移除最后一个元素
push_back() 在Vector最后添加一个元素
rbegin() 返回Vector尾部的逆迭代器
rend() 返回Vector起始的逆迭代器
reserve() 设置Vector最小的元素容纳数量
resize() 改变Vector元素数量的大小
size() 返回Vector元素数量的大小
swap() 交换两个Vector四、Map
map的功能
自动建立Key - value的对应。key 和 value可以是任意你需要的类型。
根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录,最多查找10次,1,000,000个记录,最多查找20次。
快速插入Key - Value 记录。
快速删除记录
根据Key 修改value记录。
遍历所有记录。
成员变量和成员函数
1. map最基本的构造函数;
mapmapstring; mapmapint;
mapmapstring; map< char ,string>mapchar;
mapmapchar; mapmapint;
2. map添加数据;
map maplive;
1.maplive.insert(pair(102,"aclive"));
2.maplive.insert(map::value_type(321,"hai"));
3, maplive[112]="April";//map中最简单最常用的插入添加!
3,map中元素的查找:
find()函数返回一个迭代器指向键值为key的元素,如果没找到就返回指向map尾部的迭代器。
map::iterator l_it;;
l_it=maplive.find(112);
if(l_it==maplive.end())
cout<<"we do not find 112"<::iterator l_it;;
l_it=maplive.find(112);
if(l_it==maplive.end())
cout<<"we do not find 112"< m1, m2, m3;
map ::iterator m1_Iter;
m1.insert ( pair ( 1, 10 ) );
m1.insert ( pair ( 2, 20 ) );
m1.insert ( pair ( 3, 30 ) );
m2.insert ( pair ( 10, 100 ) );
m2.insert ( pair ( 20, 200 ) );
m3.insert ( pair ( 30, 300 ) );
cout << "The original map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter->second;
cout << "." << endl;
// This is the member function version of swap
//m2 is said to be the argument map; m1 the target map
m1.swap( m2 );
cout << "After swapping with m2, map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
cout << "After swapping with m2, map m2 is:";
for ( m1_Iter = m2.begin( ); m1_Iter != m2.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
// This is the specialized template version of swap
swap( m1, m3 );
cout << "After swapping with m3, map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
}
6.map的sort问题:
Map中的元素是自动按key升序排序,所以不能对map用sort函数:
7, map的基本操作函数:
C++ Maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
erase() 删除一个元素
find() 查找一个元素
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数 五、Set结构体排序:
#include
#include
#include
using namespace std;
struct node
{
char ch;
int cost;
node()
{
ch = '\0';
cost = 0;
}
//把这个函数注释了,对整个程序没有任何影响
bool operator == ( const node &rhs) const
{
return rhs.ch == ch;
}
//如果把这个程序注释了,将会出现一堆的错误,有关STL中的错误,是无法调试、无法修改的
bool operator < (const node &rhs) const
{
return rhs.cost > cost;
}
};
// 虽然我们重定义了==函数,但这是无用的,set只根据<符号来做判断
// 可以看到,set内部根据cost排序了
注意:如果set元素是一个结构体,你最好要设置你的仿函数,不然set一般默认是按第一个字段排序的,而我们的实际情况是想按序号i排序 struct ST_Message
{
public:
ST_Message(int seq, int64_t time, string strfrom, string strto, string strinfo){
this->seq=seq;this->time=time;this->strfrom=strfrom;this->strto=strto;this->strinfo=strinfo;}
int seq;
int64_t time;
string strfrom;
string strto;
string strinfo;
bool operator <(const ST_Message& other) const // 注意是const函数
{
if (seq != other.seq) // dtime按升序排序
{
return (seq < other.seq);
}
else if(time < other.time)
{
return (time < other.time);
}
else if(strcmp(strfrom.c_str(), other.strfrom.c_str()) != 0)
{
return (strcmp(strfrom.c_str(), other.strfrom.c_str()) < 0);
}
else if(strcmp(strto.c_str(), other.strto.c_str()) != 0)
{
return (strcmp(strto.c_str(), other.strto.c_str()) < 0);
}
else
{
return (strcmp(strinfo.c_str(), other.strinfo.c_str()) < 0);
}
}
};stl中自动有序的容器map也和set有相同的应用,如果你想快速理解,那么把这篇文章中的set改成map就差不多了。
总之,有序的stl容器在工程中应用什么方便和广泛,但是当我们需要自己的排序的时候,可以用仿函数来设置它!
六、C++ STL中Map的按Key排序和按Value排序
map是用来存放
但是,我们除了希望能够查询某个学生的成绩,或许还想看看整体的情况。我们想把所有同学和他相应的成绩都输出来,并且按照我们想要的顺序进行输出:比如按照学生姓名的顺序进行输出,或者按照学生成绩的高低进行输出。换句话说,我们希望能够对map进行按Key排序或按Value排序,然后按序输出其键值对的内容。
一、C++ STL中Map的按Key排序
其实,为了实现快速查找,map内部本身就是按序存储的(比如红黑树)。在我们插入
【参考代码】
1. #include
2. #include
3. #include
4. using namespace std;
5.
6. typedef pair
7.
8. ostream& operator<<(ostream& out, const PAIR& p) {
9. return out << p.first << "\t" << p.second;
10. }
11.
12. int main() {
13. map
14. name_score_map["LiMin"] = 90;
15. name_score_map["ZiLinMi"] = 79;
16. name_score_map["BoB"] = 92;
17. name_score_map.insert(make_pair("Bing",99));
18. name_score_map.insert(make_pair("Albert",86));
19. for (map
20. iter != name_score_map.end();
21. ++iter) {
22. cout << *iter << endl;
23. }
24. return 0;
25. }
【运行结果】
大家都知道map是stl里面的一个模板类,现在我们来看下map的定义:
1. template < class Key, class T, class Compare = less
2. class Allocator = allocator
它有四个参数,其中我们比较熟悉的有两个: Key 和 Value。第四个是Allocator,用来定义存储分配模型的,此处我们不作介绍。
现在我们重点看下第三个参数: class Compare = less
这也是一个class类型的,而且提供了默认值less
所谓的函数对象:即调用操作符的类,其对象常称为函数对象(function object),它们是行为类似函数的对象。表现出一个函数的特征,就是通过“对象名+(参数列表)”的方式使用一个 类,其实质是对operator()操作符的重载。
现在我们来看一下less的实现:
1. template <class T> struct less : binary_function
2. bool operator() (const T& x, const T& y) const
3. {return x
4. };
它是一个带模板的struct,里面仅仅对()运算符进行了重载,实现很简单,但用起来很方便,这就是函数对象的优点所在。stl中还为四则运算等常见运算定义了这样的函数对象,与less相对的还有greater:
1. template <class T> struct greater : binary_function
2. bool operator() (const T& x, const T& y) const
3. {return x>y;}
4. };
map这里指定less作为其默认比较函数(对象),所以我们通常如果不自己指定Compare,map中键值对就会按照Key的less顺序进行组织存储,因此我们就看到了上面代码输出结果是按照学生姓名的字典顺序输出的,即string的less序列。
我们可以在定义map的时候,指定它的第三个参数Compare,比如我们把默认的less指定为greater:
【参考代码】
1. #include
2. #include
3. #include
4. using namespace std;
5.
6. typedef pair
7.
8. ostream& operator<<(ostream& out, const PAIR& p) {
9. return out << p.first << "\t" << p.second;
10. }
11.
12. int main() {
13. map
14. name_score_map["LiMin"] = 90;
15. name_score_map["ZiLinMi"] = 79;
16. name_score_map["BoB"] = 92;
17. name_score_map.insert(make_pair("Bing",99));
18. name_score_map.insert(make_pair("Albert",86));
19. for (map
20. iter != name_score_map.end();
21. ++iter) {
22. cout << *iter << endl;
23. }
24. return 0;
25. }
【运行结果】
现在知道如何为map指定Compare类了,如果我们想自己写一个compare的类,让map按照我们想要的顺序来存储,比如,按照学生姓名的长短排序进行存储,那该怎么做呢?
其实很简单,只要我们自己写一个函数对象,实现想要的逻辑,定义map的时候把Compare指定为我们自己编写的这个就ok啦。
1. struct CmpByKeyLength {
2. bool operator()(const string& k1, const string& k2) {
3. return k1.length() < k2.length();
4. }
5. };
是不是很简单!这里我们不用把它定义为模板,直接指定它的参数为string类型就可以了。
【参考代码】
1. int main() {
2. map
3. name_score_map["LiMin"] = 90;
4. name_score_map["ZiLinMi"] = 79;
5. name_score_map["BoB"] = 92;
6. name_score_map.insert(make_pair("Bing",99));
7. name_score_map.insert(make_pair("Albert",86));
8. for (map
9. iter != name_score_map.end();
10. ++iter) {
11. cout << *iter << endl;
12. }
13. return 0;
14. }
【运行结果】
二、C++ STL中Map的按Value排序
在第一部分中,我们借助map提供的参数接口,为它指定相应Compare类,就可以实现对map按Key排序,是在创建map并不断的向其中添加元素的过程中就会完成排序。
现在我们想要从map中得到学生按成绩的从低到高的次序输出,该如何实现呢?换句话说,该如何实现Map的按Value排序呢?
第一反应是利用stl中提供的sort算法实现,这个想法是好的,不幸的是,sort算法有个限制,利用sort算法只能对序列容器进行排序,就是线性的(如vector,list,deque)。map也是一个集合容器,它里面存储的元素是pair,但是它不是线性存储的(前面提过,像红黑树),所以利用sort不能直接和map结合进行排序。
虽然不能直接用sort对map进行排序,那么我们可不可以迂回一下,把map中的元素放到序列容器(如vector)中,然后再对这些元素进行排序呢?这个想法看似是可行的。要对序列容器中的元素进行排序,也有个必要条件:就是容器中的元素必须是可比较的,也就是实现了<操作的。那么我们现在就来看下map中的元素满足这个条件么?
我们知道map中的元素类型为pair,具体定义如下:
1. template <class T1, class T2> struct pair
2. {
3. typedef T1 first_type;
4. typedef T2 second_type;
5.
6. T1 first;
7. T2 second;
8. pair() : first(T1()), second(T2()) {}
9. pair(const T1& x, const T2& y) : first(x), second(y) {}
10. template <class U, class V>
11. pair (const pair
12. }
pair也是一个模板类,这样就实现了良好的通用性。它仅有两个数据成员first和 second,即key 和 value,而且
在
1. template<class _T1, class _T2>
2. inline bool
3. operator<(const pair<_T1, _T2>& __x, const pair<_T1, _T2>& __y)
4. { return __x.first < __y.first
5. || (!(__y.first < __x.first) && __x.second < __y.second); }
重点看下其实现:
1. __x.first < __y.first || (!(__y.first < __x.first) && __x.second < __y.second)
这个less在两种情况下返回true,第一种情况:__x.first < __y.first 这个好理解,就是比较key,如果__x的key小于 __y的key则返回true。
第二种情况有点费解: !(__y.first < __x.first) && __x.second < __y.second
当然由于||运算具有短路作用,即当前面的条件不满足是,才进行第二种情况的判断 。第一种情况__x.first < __y.first不成立,即__x.first >= __y.first成立,在这个条件下,我们来分析下 !(__y.first < __x.first) && __x.second < __y.second
!(__y.first < __x.first) ,看清出,这里是y的key不小于x的key,结合前提条件,__x.first < __y.first不成立,即x的key不小于y的key
即: !(__y.first < __x.first) && !(__x.first < __y.first ) 等价于 __x.first == __y.first ,也就是说,第二种情况是在key相等的情况下,比较两者的value(second)。
这里比较令人费解的地方就是,为什么不直接写 __x.first == __y.first呢? 这么写看似费解,但其实也不无道理:前面讲过,作为map的key必须实现<操作符的重载,但是并不保证==符也被重载了,如果key没有提供==,那么 ,__x.first == __y.first 这样写就错了。由此可见,stl中的代码是相当严谨的,值得我们好好研读。
现在我们知道了pair类重载了<符,但是它并不是按照value进行比较的,而是先对key进行比较,key相等时候才对value进行比较。显然不能满足我们按value进行排序的要求。
而且,既然pair已经重载了<符,而且我们不能修改其实现,又不能在外部重复实现重载<符。
1. typedef pair
2. bool operator< (const PAIR& lhs, const PAIR& rhs) {
3. return lhs.second < rhs.second;
4. }
如果pair类本身没有重载<符,那么我们按照上面的代码重载<符,是可以实现对pair的按value比较的。现在这样做不行了,甚至会出错(编译器不同,严格的就报错)。
那么我们如何实现对pair按value进行比较呢? 第一种:是最原始的方法,写一个比较函数; 第二种:刚才用到了,写一个函数对象。这两种方式实现起来都比较简单。
1. typedef pair
2. bool cmp_by_value(const PAIR& lhs, const PAIR& rhs) {
3. return lhs.second < rhs.second; }
4. struct CmpByValue {
5. bool operator()(const PAIR& lhs, const PAIR& rhs) {
6. return lhs.second < rhs.second;
7. } };
接下来,我们看下sort算法,是不是也像map一样,可以让我们自己指定元素间如何进行比较呢?
1. template <class RandomAccessIterator>
2. void sort ( RandomAccessIterator first, RandomAccessIterator last );
3.
4. template <class RandomAccessIterator, class Compare>
5. void sort ( RandomAccessIterator first, RandomAccessIterator last, Compare comp );
我们看到,令人兴奋的是,sort算法和map一样,也可以让我们指定元素间如何进行比较,即指定Compare。需要注意的是,map是在定义时指定的,所以传参的时候直接传入函数对象的类名,就像指定key和value时指定的类型名一样;sort算法是在调用时指定的,需要传入一个对象,当然这个也简单,类名()就会调用构造函数生成对象。
这里也可以传入一个函数指针,就是把上面说的第一种方法的函数名传过来。(应该是存在函数指针到函数对象的转换,或者两者调用形式上是一致的,具体确切原因还不明白,希望知道的朋友给讲下,先谢谢了。)
【参考代码】
1. int main() {
2. map
3. name_score_map["LiMin"] = 90;
4. name_score_map["ZiLinMi"] = 79;
5. name_score_map["BoB"] = 92;
6. name_score_map.insert(make_pair("Bing",99));
7. name_score_map.insert(make_pair("Albert",86));
8. //把map中元素转存到vector中
9. vector
10. sort(name_score_vec.begin(), name_score_vec.end(), CmpByValue());
11. // sort(name_score_vec.begin(), name_score_vec.end(), cmp_by_value);
12. for (int i = 0; i != name_score_vec.size(); ++i) {
13. cout << name_score_vec[i] << endl;
14. }
15. return 0;
16. }
list
1.list的成员函数push_back()把一个对象放到一个list的后面,而 push_front()把对象放到前面
2.list容器不支持在iterator加一个数来指向隔一个的对象。 就是说,我们不能用Milkshakes.begin()+2来指向list中的第三个对象,因为STL的list是以双链的list来实现的, 它不支持随机存取。vector和deque(向量和双端队列)和一些其他的STL的容器可以支持随机存取
3.使用STL list和 iterator,我们要初始化、比较和给iterator增量来遍历这个容器。STL通用的for_each算法能够减轻我们的工作.for_each算法引用了iterator范围的概念,这是一个由起始iterator和一个末尾iterator指出的范围。 起始iterator指出操作由哪里开始,末尾iterator指明到哪结束,但是它不包括在这个范围内。
4.使用iterator范围时,这个范围指出一个list或任意 其他容器中的一部分来处理。通常首iterator指着开始的位置,次iterator指着停止处理的地方。 由次iterator指出的元素不被处理。
5.在STL中有时容器支持它自己对一个特殊算法的实现,这通常是为了提高性能。list容器有它自己的sort算法,这是因为通用算法仅能为那些提供随机存取里面元素 的容器排序,而由于list是作为一个连接的链表实现的,它不支持对它里面的元素随机存取。所以就需要一个特殊的 sort()成员函数来排序list。
由于各种原因,容器在性能需要较高或有特殊效果需求的场合支持外部函数(extra functions), 这通过利用构造函数的结构特性可以作到。
6.必须确保在两个尖括号之间或尖括号和名字之间用空格隔开,因为是为了避免同“>>”移位运算符混淆。比如
vector
这样写会报错,而这样写:
vector > veclis;
就可以避免错误
7.vector(向量)——STL中标准而安全的数组。只能在vector的“前面”增加数据。
deque(双端队列double-ended queue)——在功能上和vector相似,但是可以在前后两端向其中添加数据。
list(列表)——游标一次只可以移动一步。如果你对链表已经很熟悉,那么STL中的list则是一个双向链表(每个节点有指向前驱和指向后继的两个指针)。
set(集合)——包含了经过排序了的数据,这些数据的值(value)必须是唯一的。
map(映射)——经过排序了的二元组的集合,map中的每个元素都是由两个值组成,其中的key(键值,一个map中的键值必须是唯一的)是在排序或搜索时使用,它的值可以在容器中重新获取;而另一个值是该元素关联的数值。比如,除了可以ar[43] = "overripe"这样找到一个数据,map还可以通过ar["banana"] = "overripe"这样的方法找到一个数据。如果你想获得其中的元素信息,通过输入元素的全名就可以轻松实现。
multiset(多重集)——和集合(set)相似,然而其中的值不要求必须是唯一的(即可以有重复)。
multimap(多重映射)——和映射(map)相似,然而其中的键值不要求必须是唯一的(即可以有重复)。
8.游标是指针,但不仅仅是指针。游标和指针很像,功能很像指针,但是实际上,游标是通过重载一元的”*”和”->”来从容器中间接地返回一个值。
9.iterator——对于除了vector以外的其他任何容器,你可以通过这种游标在一次操作中在容器中朝向前的方向走一步。这意味着对于这种游标你只能使用“++”操作符。而不能使用“--”或“+=”操作符。而对于vector这一种容器,你可以使用“+=”、“—”、“++”、“-=”中的任何一种操作符和“<”、“<=”、“>”、“>=”、“==”、“!=”等比较运算符。
10.除了类型和值外,模板含有其他的参数。你可以传递一个回调函数(通常所说的声明“predicate”——这是带有一个参数的函数返回一个布尔值)。例如,如果你想自动建立一个集合,集合中的元素按升序排列,你可以用简明的方法建立一个set类:
set
greater 是另一个模板函数(范型函数),当值放置在容器中后,它用来为这些值排序。如果你想按降序排列这些值,你可以这样写:
set
11.vector中reserve只是预先划分一块内存给vector使用,主要是为了提高效率:避免在不断push_back的过程中,由于容量变动导致的重新分配!
如果没有的话,push_back的之后,当内存不够了,就会有内存的重新分配和元素的拷贝。这是绝对很低效的。
如果 vector的容量不够了,它会
1. 重新分配更多的空间(一般是增加 N/2,N为原容量)
2. 将现有vector中的数据逐个拷贝到新空间
3. 释放旧空间中的所有元素
4. vector 指向新空间
八、C++的cin与cout
输入和输出并不是C++语言中的正式组成成分。C和C++本身都没有为输入和输出提供专门的语句结构。输入输出不是由C++本身定义的,而是在编译系统提供的I/O库中定义的。
C++的输出和输入是用“流”(stream)的方式实现的。图3.2和图3.3表示C++通过流进行输入输出的过程。
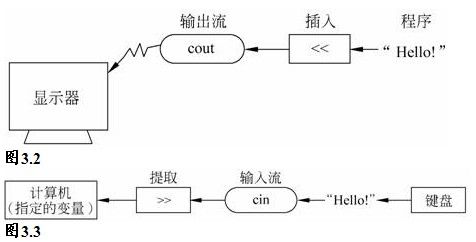
有关流对象cin、cout和流运算符的定义等信息是存放在C++的输入输出流库中的,因此如果在程序中使用cin、cout和流运算符,就必须使用预处理命令把头文件stream包含到本文件中:
#include
尽管cin和cout不是C++本身提供的语句,但是在不致混淆的情况下,为了叙述方便,常常把由cin和流提取运算符“>>”实现输入的语句称为输入语句或cin语句,把由cout和流插入运算符“<<”实现输出的语句称为输出语句或cout语句。根据C++的语法,凡是能实现某种操作而且最后以分号结束的都是语句。
一、输入流与输出流的基本操作
cout语句的一般格式为:
cout<<表达式1<<表达式2<<……<<表达式n;
cin语句的一般格式为:
cin>>变量1>>变量2>>……>>变量n;
在定义流对象时,系统会在内存中开辟一段缓冲区,用来暂存输入输出流的数据。在执行cout语句时,先把插入的数据顺序存放在输出缓冲区中,直到输出缓冲区满或遇到cout语句中的endl(或'\n',ends,flush)为止,此时将缓冲区中已有的数据一起输出,并清空缓冲区。输出流中的数据在系统默认的设备(一般为显示器)输出。
一个cout语句可以分写成若干行。如
cout<<"This is a simple C++ program."<
可以写成
cout<<"This is " //注意行末尾无分号
<<"a C++ "
<<"program."
<
也可写成多个cout语句,即
cout<<"This is "; //语句末尾有分号
cout <<"a C++ ";
cout <<"program.";
cout<
以上3种情况的输出均为
This is a simple C++ program.
注意 不能用一个插入运算符“<<”插入多个输出项,如:
cout<
cout<
在用cout输出时,用户不必通知计算机按何种类型输出,系统会自动判别输出数据的类型,使输出的数据按相应的类型输出。如已定义a为int型,b为float型,c为char型,则
cout<
会以下面的形式输出:
4 345.789 a
与cout类似,一个cin语句可以分写成若干行。如
cin>>a>>b>>c>>d;
可以写成
cin>>a //注意行末尾无分号
>>b //这样写可能看起来清晰些
>>c
>>d;
也可以写成
cin>>a;
cin>>b;
cin>>c;
cin>>d;
以上3种情况均可以从键盘输入: 1 2 3 4 ↙
也可以分多行输入数据:
1↙
2 3↙
4↙
在用cin输入时,系统也会根据变量的类型从输入流中提取相应长度的字节。如有
char c1,c2;
int a;
float b;
cin>>c1>>c2>>a>>b;
如果输入
1234 56.78↙
注意: 34后面应该有空格以便和56.78分隔开。也可以按下面格式输入:
1 2 34 56.78↙ (在1和2之间有空格)
不能用cin语句把空格字符和回车换行符作为字符输入给字符变量,它们将被跳过。如果想将空格字符或回车换行符(或任何其他键盘上的字符)输入给字符变量,可以用3.4.3节介绍的getchar函数。
在组织输入流数据时,要仔细分析cin语句中变量的类型,按照相应的格式输入,否则容易出错。
二、在输入流与输出流中使用控制符
上面介绍的是使用cout和cin时的默认格式。但有时人们在输入输出时有一些特殊的要求,如在输出实数时规定字段宽度,只保留两位小数,数据向左或向右对齐等。C++提供了在输入输出流中使用的控制符(有的书中称为操纵符)。
需要注意的是: 如果使用了控制符,在程序单位的开头除了要加iostream头文件外,还要加iomanip头文件。
举例: 输出双精度数。
double a=123.456789012345;对a赋初值
(1) cout<
(2) cout<
(3) cout<
(4) cout<< setiosflags(ios∷fixed);输出: 123.456789
(5) cout<
(6) cout<
(7) cout<
下面是整数输出的例子:
int b=123456;对b赋初值
(1) cout<
(2) cout<
(3) cout<
(4) cout<
(5) cout<
(6) cout<
如果在多个cout语句中使用相同的setw(n),并使用setiosflags(ios∷right),可以实现各行数据右对齐,如果指定相同的精度,可以实现上下小数点对齐。
例3.1 各行小数点对齐。
#include
#include
using namespace std;
int main( )
{
double a=123.456,b=3.14159,c=-3214.67;
cout<
cout<
cout<
cout<
return 0;
}
输出如下:
123.46 (字段宽度为10,右对齐,取两位小数)
3.14
-3214.67
先统一设置定点形式输出、取两位小数、右对齐。这些设置对其后的输出均有效(除非重新设置),而setw只对其后一个输出项有效,因此必须在输出a,b,c之前都要写setw(10)。
学C++的时候,这几个输入函数弄的有点迷糊;这里做个小结,为了自己复习,也希望对后来者能有所帮助,如果有差错的地方还请各位多多指教(本文所有程序均通过VC 6.0运行)转载请保留作者信息;
1、cin
1、cin.get()
2、cin.getline()
3、getline()
4、gets()
5、getchar()
1、cin>>
用法1:最基本,也是最常用的用法,输入一个数字:
#include
using namespace std;
main ()
{
int a,b;
cin>>a>>b;
cout<
输入:2[回车]3[回车]
输出:5
用法2:接受一个字符串,遇“空格”、“TAB”、“回车”都结束
#include
using namespace std;
main ()
{
char a[20];
cin>>a;
cout<
输入:jkljkljkl
输出:jkljkljkl
输入:jkljkl jkljkl //遇空格结束
输出:jkljkl
2、cin.get()
用法1: cin.get(字符变量名)可以用来接收字符
#include
using namespace std;
main ()
{
char ch;
ch=cin.get(); //或者cin.get(ch);
cout<
输入:jljkljkl
输出:j
用法2:cin.get(字符数组名,接收字符数目)用来接收一行字符串,可以接收空格
#include
using namespace std;
main ()
{
char a[20];
cin.get(a,20);
cout<
输入:jkl jkl jkl
输出:jkl jkl jkl
输入:abcdeabcdeabcdeabcdeabcde (输入25个字符)
输出:abcdeabcdeabcdeabcd (接收19个字符+1个'\0')
用法3:cin.get(无参数)没有参数主要是用于舍弃输入流中的不需要的字符,或者舍弃回车,弥补cin.get(字符数组名,接收字符数目)的不足.
这个我还不知道怎么用,知道的前辈请赐教;
3、cin.getline() // 接受一个字符串,可以接收空格并输出
#include
using namespace std;
main ()
{
char m[20];
cin.getline(m,5);
cout<
输入:jkljkljkl
输出:jklj
接受5个字符到m中,其中最后一个为'\0',所以只看到4个字符输出;
如果把5改成20:
输入:jkljkljkl
输出:jkljkljkl
输入:jklf fjlsjf fjsdklf
输出:jklf fjlsjf fjsdklf
//延伸:
//cin.getline()实际上有三个参数,cin.getline(接受字符串的看哦那间m,接受个数5,结束字符)
//当第三个参数省略时,系统默认为'\0'
//如果将例子中cin.getline()改为cin.getline(m,5,'a');当输入jlkjkljkl时输出jklj,输入jkaljkljkl时,输出jk
当用在多维数组中的时候,也可以用cin.getline(m[i],20)之类的用法:
#include
#include
using namespace std;
main ()
{
char m[3][20];
for(int i=0;i<3;i++)
{
cout<<"\n请输入第"<
}
cout< } 请输入第1个字符串: 请输入第2个字符串: 请输入第3个字符串: 输出m[0]的值:kskr1 4、getline() // 接受一个字符串,可以接收空格并输出,需包含“#include #include 输入:jkljkljkl 输入:jkl jfksldfj jklsjfl 和cin.getline()类似,但是cin.getline()属于istream流,而getline()属于string流,是不一样的两个函数 5、gets() // 接受一个字符串,可以接收空格并输出,需包含“#include #include 输入:jkljkljkl 输入:jkl jkl jkl 类似cin.getline()里面的一个例子,gets()同样可以用在多维数组里面: #include main () cout< } 请输入第1个字符串: 请输入第2个字符串: 请输入第3个字符串: 输出m[0]的值:kskr1 自我感觉gets()和cin.getline()的用法很类似,只不过cin.getline()多一个参数罢了; 这里顺带说明一下,对于本文中的这个kskr1,kskr2,kskr3的例子,对于cin>>也可以适用,原因是这里输入的没有空格,如果输入了空格,比如“ks kr jkl[回车]”那么cin就会已经接收到3个字符串,“ks,kr,jkl”;再如“kskr 1[回车]kskr 2[回车]”,那么则接收“kskr,1,kskr”;这不是我们所要的结果!而cin.getline()和gets()因为可以接收空格,所以不会产生这个错误; 6、getchar() //接受一个字符,需包含“#include #include 输入:jkljkljkl //getchar()是C语言的函数,C++也可以兼容,但是尽量不用或少用; 有什么建议可以一起探讨,我的email是
cout<<"输出m["<
kskr1
kskr2
kskr3
输出m[1]的值:kskr2
输出m[2]的值:kskr3
#include
using namespace std;
main ()
{
string str;
getline(cin,str);
cout<
输出:jkljkljkl
输出:jkl jfksldfj jklsjfl
#include
using namespace std;
main ()
{
char m[20];
gets(m); //不能写成m=gets();
cout<
输出:jkljkljkl
输出:jkl jkl jkl
#include
using namespace std;
{
char m[3][20];
for(int i=0;i<3;i++)
{
cout<<"\n请输入第"<
}
cout<<"输出m["<
kskr1
kskr2
kskr3
输出m[1]的值:kskr2
输出m[2]的值:kskr3
#include
using namespace std;
main ()
{
char ch;
ch=getchar(); //不能写成getchar(ch);
cout<
输出:j