R语言之统计学
数据的描述
1. 用图表描述:
①统计类:
table() 生成频数分布表
prop.table() 将频数分布表转化为比例
addmargins() 给频数分布表添加边际和或边际比例
barplot() 生成条形统计图
pie() 生成饼图

②分布类:
hist() 生成直方图,观察变量内的分布
stem() 生成茎叶图,观察变量内的分布
boxplot() 生成箱线图,观察变量内的分布或对象间的变量水平比较
plot() 生成散点图,观察变量间的分布关系
radarchart() 生成雷达图,观察样本间的相似性。package(fmsb)
2. 用统计量描述:
①水平的描述
mean() 均值,易受极端值影响
median() 中位数,不受极端值影响
quantile() 分位数
summay() 描述统计量,输出数据的基本描述信息
②差异的描述
max()-min() 极差,易受极端值的影响,不能全面反映差异的情况
quantile(x,0.75)-quantile(x,0.25) 四分位差,又称内距、四分间距,不受极端值影响
var() 方差,数据离散程度的度量,比极差、四分位差更全面具体,但受数据取值大小的影响,无量纲
sd() 标准差,方差开方,有量纲,性质同方差
③分布形态的描述
skewness() 偏斜系数,其绝对值越接近0偏斜程度越低数据分布越对称,小于0.5位轻微偏斜,在0.5到1之间为中等偏斜,大于1为严重偏斜。值>0时右偏,均值大于中位数;值<0则左偏,均值小于中位数。package(agricolae)
kurtosis() 峰度系数,数据分布峰值的高低。其值>0时为尖峰分布,数据相对聚集;<0时为扁平分布,数据相对分散。标准正态分布峰度系数为0。package(agricolae)
分布
1. 概率分布:
①函数开头的字母
d = 密度函数(density)
p = 分布函数(distribution function)
q = 分位数函数(quantile function),给定累计概率、均值、方差求所在的分位数
r = 生成随机数(随机偏差)
②一些常用分布函数(开头要加上d、p、q、r)
binom() 二项分布
geom() 几何分布
pois() 泊松分布
norm() 正态分布
unif() 均匀分布
③数据的正态性评估
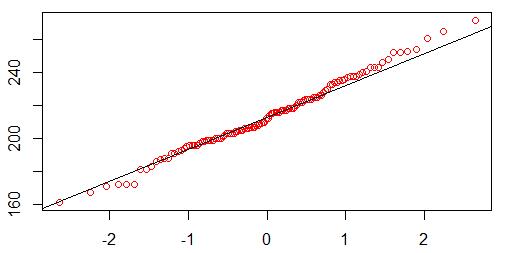
先qqnorm(y = 数据),后qqline( y = 数据 ) 生成Q-Q图,直线表示理论正态分布线,各观测点越接近直线且呈随机分布,表明数据越接近正态分布
2. 统计分布:
①函数开头的字母:
同概率分布的d、p、q、r一样
②三个统计分布(变量均基于正态分布。开头要加上d、p、q、r)
t() t分布,随自由度越大越尖越接近标准正态分布,当正态总体标准差未知时,小样本条件下对总体均值的估计和检验要用到t分布
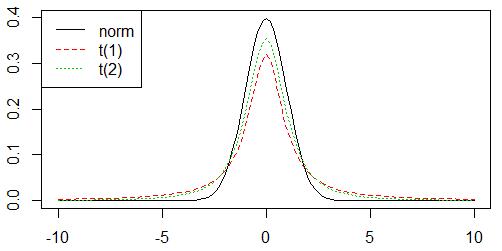
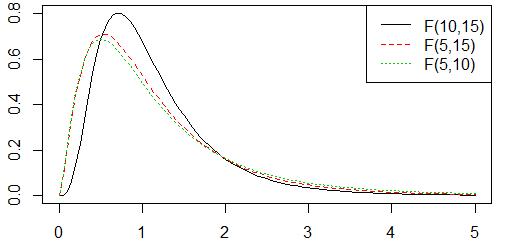
chisq() 卡方分布,通常为不对称的右偏分布,自由度越大则越趋于平坦对称。概率为曲线下的面积。在总体方差的估计和非参数检验中常用到卡方分布
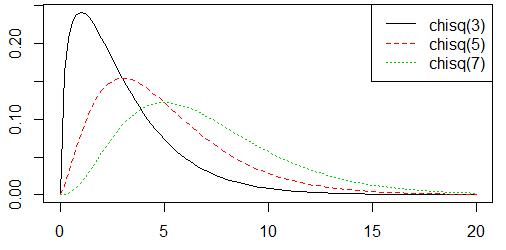
f() F分布,两个相互独立的随机变量的卡方分布除以各自的自由度之比,图像类似卡方分布,形状取决于两个相互独立的随机变量的卡方分布的自由度,其概率为曲线下的面积,通常用于比较不同的总体的方差是否有显著差异
3. 样本统计量的概率分布
①样本均值的分布(中心极限定理)
从均值为μ、方差为σ²;(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时(通常要求n≥30),样本均值的抽样分布近似服从均值为μ、方差为σ²/n 的正态分布。
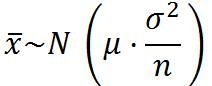
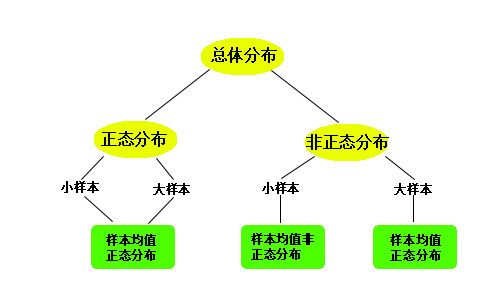
②样本的均值分布规则
③样本比例的分布
从一个总体中重复选取样本量为n的样本,由样本比例的所有可能取值形成的分布是样本比例的概率分布。当样本量很大时(通常要求np≥10和n(1-p)≥10)样本比例分布可用正态分布近似,p的期望值E(p) = π,方差为[π(1-π)]/n
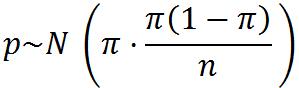
参数估计
1. 参数估计的原理
①点估计
用估计量的某个取值直接作为总体参数的估计值,比如直接用样本均值x作为总体均值μ的估计值,用样本比例p直接作为总体比例π的估计值,用样本方差s²作为总体方差σ²的估计值
②区间估计
在点估计的基础上给出总体参数估计得一个估计区间,该区间通常是由样本统计量加减估计误差得到的
③置信区间(CI)
区间估计中,由样本估计量构造出的总体参数在一定置信水平(置信度)下的估计区间称为置信区间
在其他条件不变的情况下,使用一个较大的置信水平会得到一个较宽的置信区间,而使用一个较大的样本则会得到一个较窄(准确)的区间
置信水平只是告诉我们在多次估计得到的区间中大概有多少个区间包括了参数的真值,而不是针对所抽取的这个样本所构建的区间而言

④评价估计量的标准
无偏性:估计量抽样分布的期望值等于被估计的总体参数
有效性:估计量的方差大小。对同一总体参数的多个无偏估计量,更小方差的估计量更有效
一致性:随着样本量的无限增大,统计量收敛于所总体的参数
2. 总体均值的区间估计
①一个总体均值的估计
大样本(n≥30,可来自任何分布的总体):
总体方差已知
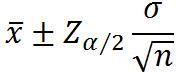
总体方差未知
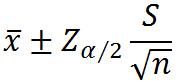
小样本(假定总体正态分布):
总体方差已知
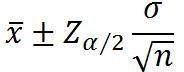
总体方差未知,可用t.test()进行检验
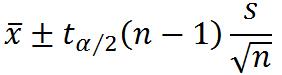
②两个总体均值之差的估计
独立大样本的估计(n1≥30 , n2≥30):
总体方差已知

总体方差未知
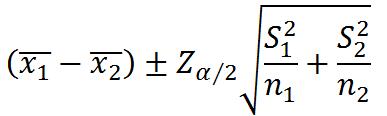
独立小样本的估计(假定总体正态分布):
两个总体方差都已知
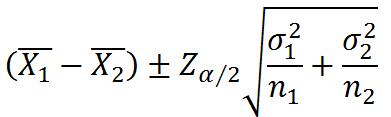
两个总体方差都未知但相等,可用t.test(var.equal = T)进行检验
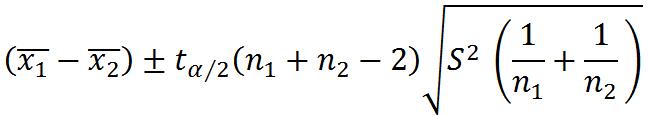
两个总体方差都未知且不等,可用t.test(var.equal = F)进行检验
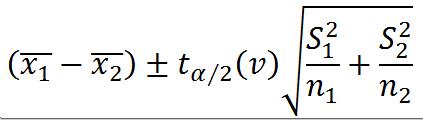
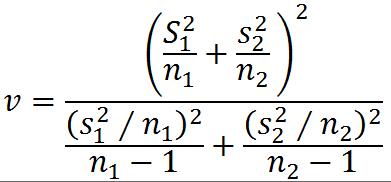
配对样本的估计(同一个体的前后两次测量。d为两两配对的差值。可用t.test(paired = T)进行检验)
:
大样本总体方差已知
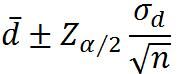
大样本总体方差未知

小样本总体方差已知(假定总体正态分布)
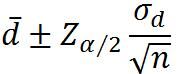
小样本总体方差未知(假定总体正态分布)

3.总体比例的区间估计(大样本)
①一个总体比例的估计
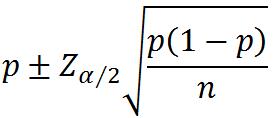
②两个总体比例之差的估计
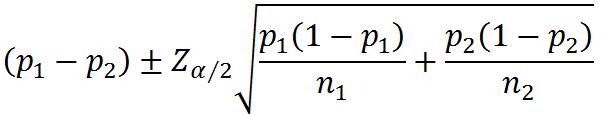
4.总体方差的区间估计(假定总体正态分布)
①一个总体方差的估计
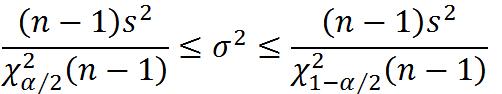
②两个总体方差比的估计
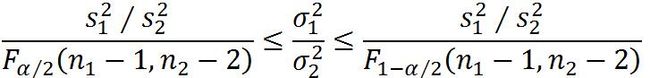
假设检验
1. 假设检验的基本原理
①思路
首先对所关心的总体提出某种假设,然后从待检验的总体中抽取一个随机样本并获得数据,再根据样本提供的信息判断假设是否成立
②如何提出假设
将自己想推翻的假设设为原假设H0,将自己想得出证明的假设设为备择假设H1。
③一些定义
若备择假设没有特定的方向性,并含有符合≠,这样的假设检验称为双侧检验或称双尾检验;若备择假设有具体的方向性,并含有符号”>”或”<”,这样的假设检验称为单侧检验或单尾检验,其中”>”为右侧检验,”<”为左侧检验
④两类错误与显著性水平
原假设正确却拒绝原假设==>第一类错误,概率称为α,也成α错误
原假设错误却接受原假设==>第二类错误,概率称为β,也成β错误
假设检验中犯第一类错误的概率也称为显著性水平,记为α,它是人们事先指定的犯第一类错误概率的最大允许值。显著性水平α越小,犯第一类错误的可能性越小,但犯第二类错误的可能性则越大。当选择样本量时,通常要求α≤0.05,β≤0.1。
⑤依据什么做出决策
根据样本数据算出犯第一类错误的概率P值,原假设成立时小概率事件不应该发生,如果小概率事件发了,就应当拒绝原假设。

⑥怎么表述决策结果
假设检验的目的主要是收集证据拒绝原假设,而支持你所倾向的备择假设。当拒绝原假设时,表明样本提供的证据证明它是错误的,当没有拒绝原假设时,我们也没有办法证明它是正确的。所有我们通常说:“拒绝原假设”、”不拒绝原假设”(如果说“接受原假设”则很可能会犯第二类错误)。
2. 总体均值的检验(其中的μ0为假设的总体均值)
①一个总体的均值检验
大样本(n≥30,可来自任何分布的总体):
总体方差已知
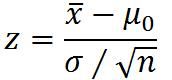
总体方差未知

小样本(假设总体正态分布)
总体方差已知
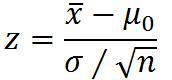
总体方差未知
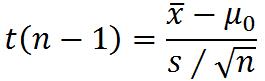
②两个总体均值之差检验
独立大样本的检验(n1≥30,n2≥30):
两个总体方差已知
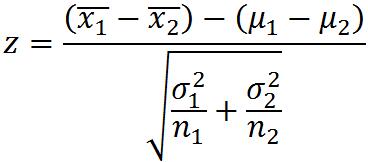
两个总体方差未知
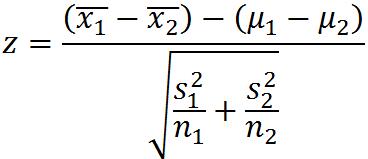
独立小样本的检验(假设总体正态分布)
总体方差已知
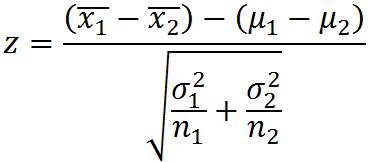
两个总体方差未知但相等

两个总体方差未知且不等
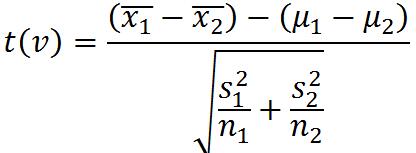
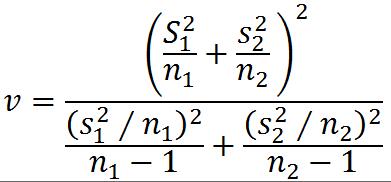
③配对样本的检验(两个样本差值构成正态分布,且配对差从总体差值随机抽取)
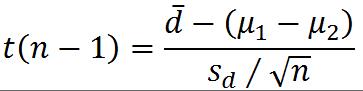
3. 总体比例的检验(大样本)
①一个总体比例的检验
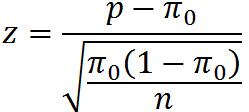
②两个总体比例之差的检验
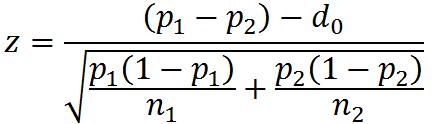
4.总体方差的检验(总体服从正态分布)
①一个总体方差的检验
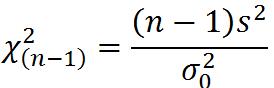
②两个总体方差比的检验(是否有显著性差异)
类别变量分析
1. 一个类别变量的拟合优度检验
当只研究一个类别变量时,可利用卡方检验来判断个类别的观察频数与某一期望频数或理论频数是否一致(是否均匀分布),这就是卡方拟合度检验
①期望频数相等
chisq.test(x) 卡方拟合度检验默认期望频数相等
②期望频数不等
chisq.test(x = 变量频数 , p = 期望频数)
2.两个类别变量的独立性检验
对于两个类别变量的推断分析,主要是检验两个变量是否独立,这就是卡方独立性检验
①列联表与卡方独立性检验
chisq.test(x = 列联表) 卡方独立性检验的原假设是:两个变量独立
②使用卡方独立性检验的注意事项
1)若仅有两个单元格,单元格的最小期望频数不应小于5
2)单元格在两个以上时,期望频数小于5的单元格不能超过总格子数的20%
3.两个类别变量的相关性度量
若卡方独立性检验拒绝了原假设,即两个变量不独立,这意味着他们之间存在一定的关系,这时可以进一步测度他们的关联程度,使用的统计量主要有φ系数、Cramer’V系数、列联系数
①φ系数
用于2×2的列联表,取值[ 0 , 1 ],φ越接近1表明两个变量之间的关系越强,越接近0表明关系越弱
②Cramer’V系数
取值[ 0 , 1 ],当两个变量独立时V = 0,当两个变量完全相关时V = 1,当列联表的行列有一个为2时,Cramer’V系数 = φ系数
③列联系数
主要用于大于2×2列联表的相关性测量,取值[ 0 , 1 ),越接近0关系越弱,越接近1关系越强
④R计算
assocstats(x = 列联表) package(vcd)

方差分析
1. 方差分析的基本原理
①什么是方差分析
方差分析是分析各类别自变量对数值因变量影响的一种统计方法
②误差分解
1)反映全部观测数据的误差称为总误差
2)不同自变量(处理)造成的误差称为处理误差,又叫组间误差
3)其他随机因素造成的误差称为随机误差,又叫组内误差,简称误差
统计中误差通常用平方和表示,记为SS:
1)反映数据总误差大小的平方和称为总平方和,记为SST
2)反映处理误差大小的平方和称为处理平方和,也称组间平方和,记为SSA
3)反映随机误差大小的平方和称为误差平方和,也称组内平方和,记为SSE
显然,三个组内平方和的关系为:SST = SSA + SSE
方差分析就是分析数据的总误差中有没有处理误差
③方差分析的基本假定
1)正态性:每种处理所对应的总体都应来自正态分布
2)方差齐性:各个总体的方差σ²必须相等
3)独立性:每个样本数据是来自不同处理的独立样本(要求严格)
2. 单因子方差分析
只考虑一个类别比那里
对观测数据影响的方差分析称为单因子方差分析
①效应检验
1)先进行正态性检验:Q-Q图(在概率分布里有讲解,这里不再累述),
2)再进行方差齐性检验:bartlett.test(data = 数据 , formula = 因变量~自变量 ),函数原假设为方差齐
3)然后进行拟合方差模型分析aov(data = 数据 , formula = 因变量~自变量) ,原假设为自变量对因变量的影响不显著
4)查看方差分析表summary(object = 拟合方程模型)
5)fit$coefficients表示不考虑组间误差的影响时因变量总的平均值
②多重比较
单因子方差分析只能表明自变量对因变量的影响是否显著,却不能知道究竟哪些处理的因变量差异显著,而多重比较通过均值之间的配对检验来找出到底哪些处理之间存在差异
1)pairwise.t.test(x = 因变量 , g = 自变量),输出一个处理间的关系矩阵,观察处理间的显著性差异
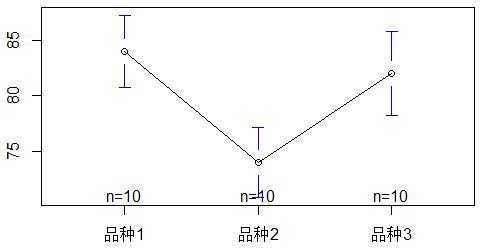
③可视化效应
plotmeans(data = 数据, formula = 因变量~自变量)
3.双因子方差分析
考虑两个类别自变量对数值因变量影响的方差分析称为双因子方差分析。只考虑两个因子对因变量的单独影响,即主效应,这时方差分析称为无重复双因子分析;除考虑两个因子对因变量的单独影响外,还考虑两个因子的搭配对因变量产生的交互影响,这时方差分析称为可重复双因子分析。
①主效应分析
方法同 2.单因子方差检验 的 ①效应检验,其中formula表示形式为 因变量~自变量1+自变量2
②交互效应分析
方法同 2.单因子方差检验 的 ①效应检验,其中formula表示形式为 因变量~自变量1+自变量2+自变量1:自变量2
③可视化效应
interaction.plot(x.factor = 作为X轴的自变量, trace.factor = 另一个自变量, response = 因变量)

一元线性回归
1. 变量间的关系
①确定变量间的关系
由于影响一个变量的因素有很多个,才造成变量间关系的不确定性。变量间这种不确定的关系称为相关关系
特点:一个变量的取值不能由另一个变量唯一确定,当变量x取某个值时,变量y的取值可能有多个。或者说:当x取某一固定值时,y的取值对应着一个分布
②相关关系的描述
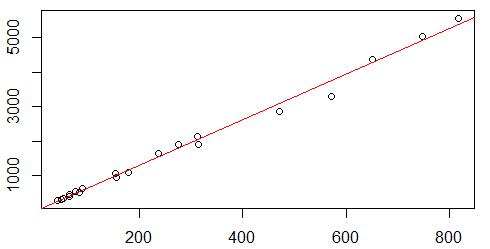
描述相关关系的一个常用工具就是散点图
plot(x = 作为x轴的变量 , y = 作为y轴的变量) ,绘制散点图
abline( lm( data = 数据 , formula = 作y轴的变量~作x轴的变量) ) 给散点图添加回归线,其中lm()函数是线性拟合模型,能够给出数据的线性回归参数:截距与斜率
③关系强度的度量
1)相关系数:Pearson相关系数,r取值范围[-1 , 1],r大于0表明正线性相关,小于0表明负线性相关,|r|越趋于1表明两个变量间的线性关系越强。|r|= 1时称为完全线性相关,|r| = 0时表明不存在线性关系
cor(x = 作为x轴的变量 , y = 作为y轴的变量)
2)相关系数的检验:R.A.Fisher提出的t检验,可用于小样本和大样本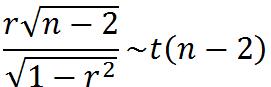
cor.test(x = 作为x轴的变量 , y = 作为y轴的变量),原假设为总体两个变量的线性关系不显著
2. 回归模型的估计和检验
回归建模的大体思路如下:
1)确定变量间的关系
2)确定因变量和自变量,并建立变量间的关系模型
3)对模型建立评估和检验
4)利用回归方程进行预测
5)利用预测的残差分析模型的假定
①一元线性回归模型
1)回归模型:
因变量:被预测或被解释的变量
自变量:用来预测或用来解释因变量的一个或多个变量*
当回归中只涉及一个自变量时称为一元回归,描述因变量y如何依赖于自变量x和误差ε的方程称为回归模型,一元回归模型可表示为
![]()
β0+β1x反映了由于x的变化而引起的y的线性变化,ε是被称为误差项的随机变量,对于误差项ε需要作出以下假定:
正态性:ε是一个服从正态分布的随机变量
方程齐性:对于所有的x值,ε的方差σ²都相同
独立性:对于一个特定的x值,它所对应的ε与其他x所对应的ε不相关
2)估计的回归方程:
由于实际参数β0和β1是未知的,所有必须利用样本数据去估计它们。用样本统计量估计模型中的参数β0和β1时,就得到了估计的回归方程
![]()
②参数的最小二乘估计
模型中参数的确定方法通常是最小二乘法,根据最小二乘法有:
![]()
1)lm(data = 数据,formula = 因变量~自变量),得出线性拟合模型
2)summary(object = 线性拟合模型),对线性拟合模型概述
3)confint(object = 线性拟合模型 , level = 置信水平),对线性拟合模型的参数得出相应水平的置信区间
4)anova(object = 线性拟合模型),得到模型的方差分析表
③模型的拟合优度
回归直线与各观测点的接近程度称为回归直线对数据的拟合优度,评价拟合优度的一个重要统计量就是判定系数
1)判定系数:
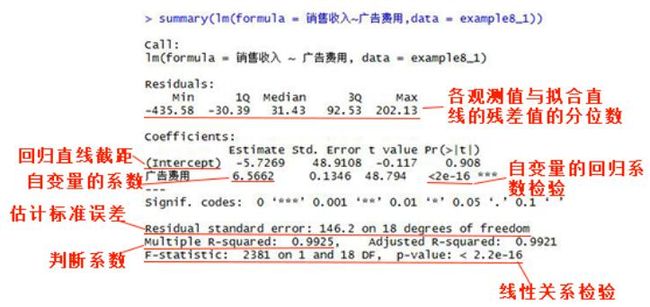
回归平方和占总平方和的比例,记为R²。R²的取值范围是[ 0 ,1],其值越接近1表明回归直线拟合程度就越好,越接近0则回归直线拟合程度越差。在summary(object = 线性拟合模型)中Multiple R-squared一栏中显示

其中SST 为总平方和,反映了因变量取值的总误差大小,可分为两部分:SSR(反映y的总变差中由于x的变动引起的y的变化部分,是可以由回归直线来解释的yi的变差部分,称为回归平方和)和SSE(实际观测点与回归值的离差平方和,它是除了x对y的线性影响之外的其他随机因素对y的影响,是不能由回归直线来解释的yi的变差部分,称为残差平方和)。
2)估计标准误差:
残差平方和均方根,即残差的标准差,用Se来表示。其中k为自变量的个数,在一元线性回归中n-k-1 = n-2。Se是度量观测点在直线周围分散程度的一个统计量,反映了实际观测值yi与回归估计值y^之间的差异程度,也是对误差项ε的标准差σ的估计值,也可以看做是排除了x对y的线性影响后,y随机波动大小的一个估计量。在summary(object = 线性拟合模型)中Residual standard error一栏中显示
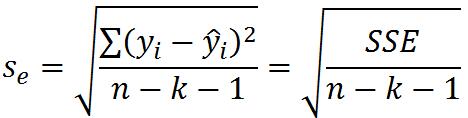
④模型的显著性检验
回归分析中的显著性检验主要包括线性关系检验和回归系数检验
1)线性关系检验:
线性关系检验简称F检验,用于检验自变量x与因变量y之间的线性关系是否显著。将SSR除以相应的自由度(SSR的自由度是自自变量的个数n)后的结果称为回归均方(MSR),将SSE除以相应自由度(SSE自由度为n-k-1,k是自变量的个数)后的结果称为残差均方(MSE)。若原假设成立(两个变量之间的线性关系不显著),则比MSR/MSE的抽样分布服从分子自由度为k,分母自由度为n-k-1的F分布。在summary(object = 线性拟合模型)中F-statistic和p-value一栏中显示
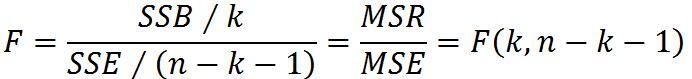
2)回归系数的检验和判断:
回归系数检验简称t检验,用于检验自变量因变量的影响是否显著。其原假设是自变量对因变量的影响不显著。在一元线性回归中,由于只有一个自变量,所以回归系数检验和线性关系检验是等价的(在多元回归中这两种检验不再等价)。在summary(object = 线性拟合模型)中在Coefficients表的Pr列中显示
⑤概括
3. 利用回归方程进行预测
回归分析的主要目的之一是根据所建立的回归方程用给定的自变量来预测因变量。若对于x的一个给定值x0,求出y的一个预测值y0,这就是点估计,在点估计的基础上可以求出y的一个估计区间。估计区间由两种类型:平均值的置信区间和个别值的预测区间
①平均值的置信区间
平均值的置信区间是对x的一个给定值x0,求出y的平均值的估计区间。
predict(object = 线性拟合模型,newdata = 预测的自变量值,interval = ‘confidence’,level =置信水平)。其中newdata为data.frame类型,该函数返回拟合值fit,置信区间下限lwr和上限upr
②个别值的预测区间
个别值的预测区间是对x的一个给定值x0,求出y的一个个别值的估计区间。
predict(object = 线性拟合模型,newdata = 预测的自变量值,interval = ‘prediction’,level =置信水平)。其中newdata为data.frame类型,该函数返回拟合值fit,预测区间下限lwr和上限upr
③置信区间和预测区间图
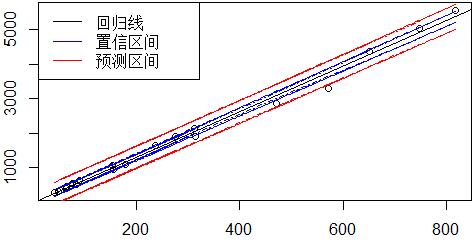
4. 回归模型诊断
判断模型假定是否成立的过程就是回归诊断,通过回归诊断可以判断所建立的模型是否合适。
在回归模型中我们先假定自变量x与因变量y之间是线性关系,同时假定误差项的随机变量ε是期望值为0、方差相等且服从正态分布的一个独立随机变量。检验ε假定是否成立的方法通常是进行残差图分析。
①残差与标准化残差
残差是因变量的观测值与估计的回归方程求出的预测值之差,反映了用估计的回归方程预测y而引起的误差。
残差除以它的标准差后的结果称为标准化残差,也称Pearson残差或半学生化残差。检验误差项ε的假定是否成立可以通过残差图的分析来完成。
1)若关于ε等方差的假定成立,而且假定描述变量x和y之间关系的回归模型是合理的,那么残差图中的所有点都应以均值0为中心随机分布在一条水平带中间。
2)若对于所有的x值,ε的方差是不同的,这就违反了ε方差相等的假设
3)若残差图呈现出某种非线性形态,表明所选择的回归模型不合理,这是应该考虑非线性模型
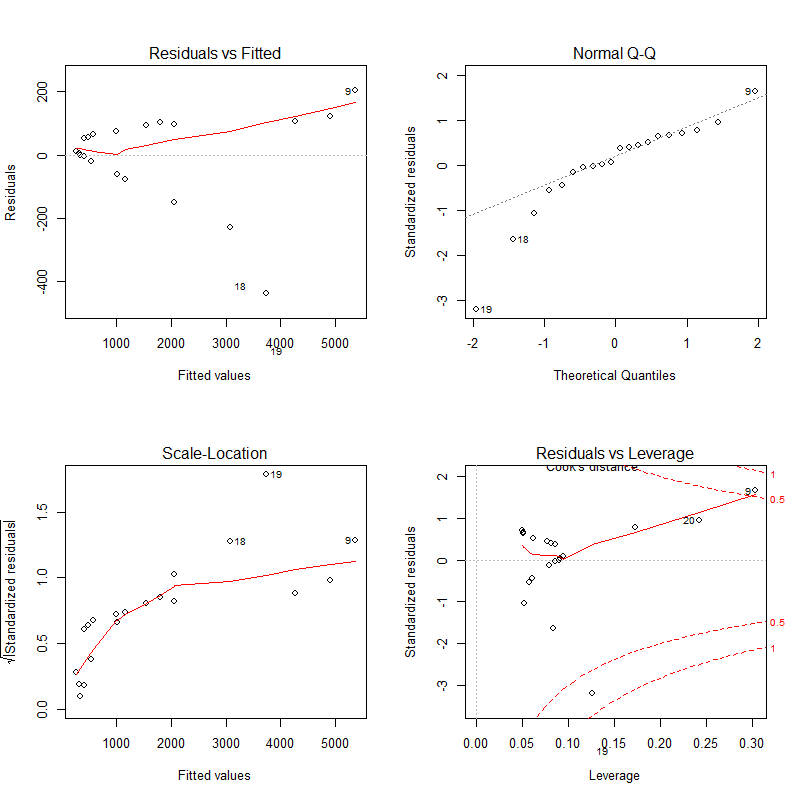
②模型诊断
plot(x = 线性拟合模型)
1)左上图是残差值~拟合值图,该图可以用于判断因变量与自变量之间的线性关系假定是否成立。若因变量与自变量之间为线性关系,那么残差值与拟合值之间基本上在一条水平线附近随机波动。
2)右上图是标准化残差的正态Q-Q图,该图用于检验关于残差正态性的假定是否成立。若各个点基本在直线周围随机分布,没有固定模式,则可以判断关于ε正态性的假定基本成立
3)左下图是位置尺度图,该图可用于判断残差方差齐性。若ε满足方差齐性,各个点在水平线周围则随机分布
4)右下图是残差与杠杆图,该图可用于鉴别样本数据中是否有离群点、高杠杆值点和强影响点。强影响点可以通过Cook距离来识别
多元线性回归
影响因变量的因素往往有多个,这种一个因变量同多个自变量的回归就是多元回归,当因变量与各自变量之间为线性关系时,称为多元线性回归
1)确定所关注的因变量y和影响因变量的k个自变量
2)假定因变量y与k个自变量之间为线性关系,并建立变量间的线性关系模型
3)对模型进行评估和检验
4)判别模型中是否存在多重共线性,如果存在,进行处理
5)利用回归方程进行预测,并利用预测的残差分析模型的假定
1. 多元线性回归
①回归模型与回归方程
1)回归模型:
设因变量y,k个自变量分别为x1,x2,…,xk。描述因变量y如何依赖于自变量x1,x2,…,xk和误差项ε的方程称为多元线性回归方程
![]()
对于ε同样有3个基本假定:
正态性:ε是一个服从正态分布的随机变量,且期望值为0,即E(ε) = 0
方差齐性:对于自变量x1,x2,…,xk的所有值,ε的方差σ²都相等
独立性:对于自变量x1,x2,…,xk的一组特定值,它所对应的ε与任意一组x1,x2,…,xk其他值所对应的ε都不相关。同样对于给定的一组x1,x2,…,xk值,因变量y也是一个服从正态分布的随机变量
2)估计的回归方程:
回归模型中的参数β0、β1、β2…βk是未知的,需要利用样本数据去估计。当用样本统计量去估计模型中的参数β0、β1、β2…βk时,就得到了估计的多元线性回归方程
![]()
②参数的最小二乘估计
多元线性回归模型中的参数仍然使用最小二乘法来估计,也就是残差平方和最小
![]()
1)lm(data = 数据,formula = 因变量~自变量1+自变量2+…自变量k),得出线性拟合模型
2)summary(object = 线性拟合模型),对线性拟合模型概述
3)confint(object = 线性拟合模型 , level = 置信水平),对线性拟合模型的参数得出相应水平的置信区间
4)anova(object = 线性拟合模型),得到模型的方差分析表
2. 拟合优度和显著性检验
①模型的拟合优度
多元线性回归模型的拟合优度可以用多重判定系数、估计标准误差等统计量来评价。
1)多重判断系数:
在多元线性回归中同样有SST = SSR + SSE,这里不再累述。同样,多重判断系数是多元线性回归中回归平方和占总平方和的比例:R² = SSR / SST。R²度量了多元线性回归模型的拟合优度,它表示在因变量y的总变差中被多个自变量共同所解释的比例
在多元线性回归中,当增加自变量时会使SSE变小,从而SSR变大,R²变大。为了避免增加自变量而高估R²,有根据样本量n和自变量个数k 调整的多重判断系数。在summary(object = 线性拟合模型)中Adjusted R-squared一栏中显示
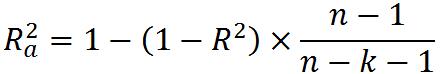
2)估计标准误差:
与一元线性回归无异,这里不再累述
②模型的显著性检验
在一元线性回归中,由于只有一个自变量,F检验(线性关系检验)与t检验(回归系数检验)是等价的,但在多元线性回归中这两种检验不再等价。F检验主要是检验因变量同多个自变量的整体线性关系是否显著,在k个变量中只要有一个自变量同因变量的线性关系显著,F检验就显著,但这不一定意味着每个自变量同因变量的关系都显著。t检验则是对每个回归系数分别进行单独的检验,以判断每个自变量对因变量的影响是否显著
1)线性关系检验:
与一元线性回归无异,这里不再累述
2)回归系数检验:
与一元线性回归无异,这里不再累述
3. 多重共线性及其处理
当回归模型中使用两个或两个以上的自变量时,这些自变量之间往往会彼此相关,提供多余的信息。而当存这种自变量彼此相关的情况时,我们称回归模型中存在多重共线性
①多重共线性及其识别
1)多重共线性产生的问题:
变量之间高度高度相关时,可能会使回归的结果造成混乱,甚至会把分析引入歧途
多重共线性可能对参数估计值的正负号产生影响
2)多重共线性的识别与处理
Ⅰ.对模型中各自变量之间的相关系数进行显著性检验
corr.test(x = 自变量,use = “pairwise/complete”) library(psych)。该函数返回自变量间的相关系数矩阵及显著性P值矩阵,其中x为矩阵或数据帧
Ⅱ.考察各回归系数的显著性。当模型的F检验(线性关系检验)显著时,几乎所有回归系数的t检验(回归系数检验)却不显著,则表示模型中可能存在多重共线性。
Ⅲ.分析回归系数的正负号,如果回归系数的正负号与预期相反,则表示模型中可能存在多重共线性
Ⅳ.用容忍度和方差扩大因子(VIF)来识别多重共线性。容忍度越小(通常阈值为0.1),多重共线性越严重。VIF等于容忍度的倒数,显然VIF越大(通常阈值为1/0.1=10),多重共线性越严重
vif(mod = 线性拟合模型) library(car),函数返回各自变量的VIF值
②变量选择与逐步回归
在建立多元线性回归模型时,不要试图引入更多的自变量,除非确实有必要。变量选择的方法主要有向前选择、向后选择、逐步回归等
1)向前选择
向前选择法是从模型中没有自变量开始,然后按下面的步骤选择自变量来拟合模型
Ⅰ.分别拟合因变量y对k个自变量的一元线性回归模型,共有k个,找出F统计量的值最大的模型及其自变量x,将该自变量首先引入模型。
Ⅱ.在模型已经引入了xi的基础上,再分别拟合引入模型外的k-1个自变量的回归模型,挑选出F统计量的值最大的含有两个自变量的模型。
Ⅲ.然后再分别拟合引入模型外的k-2个自变量的回归模型,挑选出F统计量的值最大的含有三个自变量的模型…依次进行迭代,直到模型外的自变量均无统计显著性为止
2)向后剔除
与向前剔除相反
Ⅰ.拟合因变量对所有k个自变量的回归模型。然后考察k个去掉了一个自变量的模型,挑选出F统计量最大的拟合模型(此时模型拥有k-1个自变量)
Ⅱ.对拥有k-1个自变量的模型剔除1个自变量处理,分别计算k-1个拥有k-2个自变量的回归模型的F统计量,挑选出最大的回归模型
Ⅲ.重复步骤Ⅱ,直到剔除了一个F统计量显著的自变量为止
3)逐步回归
逐步回归是将向后剔除和向前剔除结合起来,前两步与向前选择法相同,不过在新增加一个自变量后会对模型中所有的变量重新进行考察,看看有没有可能剔除某个自变量。如果在新增加一个自变量后,前面增加的某个自变量对模型的贡献变得不显著,这个自变量就会被剔除
step(object = 线性拟合模型),该函数返回的信息中,AIC的值越小,说明拟合的模型精度越高而且越简洁。在最后的Call项中会给出最精简的回归拟合模型
4. 利用回归方程进行预测
方法同一元线性回归预测
———————————————
本文为博主就贾俊平先生的《统计学-基于R应用》一书做的读书笔记,如果有兴趣的朋友可以购买借阅原书进行仔细阅读