随机森林:提供银行精准营销解决方案
原文地址:https://blog.csdn.net/weixin_34233679/article/details/88480912
本例是根据科赛网练习赛进行练手,学习巩固一下随机森林建模以及应用。
- 赛题描述
本练习赛的数据,选自UCI机器学习库中的「银行营销数据集(Bank Marketing Data Set)」
这些数据与葡萄牙银行机构的营销活动相关。这些营销活动以电话为基础,一般,银行的客服人员需要联系客户至少一次,以此确认客户是否将认购该银行的产品(定期存款)。
因此,与该数据集对应的任务是「分类任务」,「分类目标」是预测客户是(' 1 ')或者否(' 0 ')购买该银行的产品。
- 导入相关库
-
from sklearn.ensemble
import RandomForestClassifier
-
from sklearn.model_selection
import GridSearchCV
-
from sklearn.model_selection
import cross_val_score
-
import matplotlib.pyplot
as plt
-
import pandas
as pd
-
import numpy
as np
- 查看数据集
-
data = pd.read_csv(
'train_set.csv')
-
data.head()

字段分别为表示为客户ID、年龄、职业、婚姻状况、受教育水平、是否有违约记录、每年账户的平均余额、是否有住房贷款、是否有个人贷款、与客户联系的沟通方式、最后一次联系的时间(几号)、最后一次联系的时间(月份)、最后一次联系的交流时长、在本次活动中,与该客户交流过的次数、距离上次活动最后一次联系该客户,过去了多久(999表示没有联系过)、在本次活动之前,与该客户交流过的次数、上一次活动的结果、预测客户是否会订购定期存款业务。
数据集没有缺失值,不需要填充。
- 查看数据概述
data.describe()
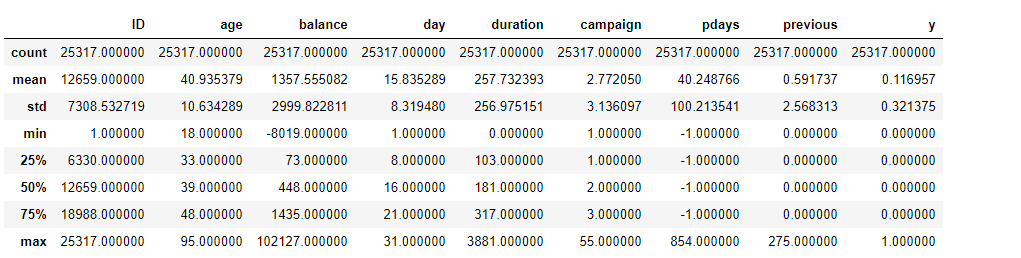
从表格可以看出,客户最大年龄为95,最小年龄为18,平均年龄为41。"在距离上次活动最后一次联系该客户,过去了多久"这个字段中最小为-1,最大为854,并没有999。可以推断,应该-1表示为没联系过。
由于最后一次联系的时间(几号)、最后一次联系的时间(月份)、距离上次活动最后一次联系该客户这个三个特征有重合,并且前两个字段无法说明距今时间长度,故删除前两个字段。然后将'job','marital','education','default','housing','loan','contact','poutcome'这些类别变量进行哑变量处理。
-
data.drop([
'ID',
'day',
'month'], axis=
1, inplace=True)
-
dummy = pd.get_dummies(
data[[
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'poutcome']])
-
data = pd.concat([dummy,
data], axis=
1)
-
data.drop([
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'poutcome'], inplace=True, axis=
1)
- 拆分数据集
-
from sklearn.model_selection
import train_test_split
-
X =
data[
data.columns[:
-1]]
-
y =
data.y
-
Xtrain, Xtest, ytrian, ytest = train_test_split(X, y, test_size=
0.3, random_state=
90)
- 确定随机森林数目
-
scorel = []
-
for i in
range(
0,
200,
10):
-
rfc = RandomForestClassifier(n_estimators=i+
1,
-
n_jobs=
-1,
-
random_state=
90)
-
score = cross_val_score(rfc,Xtrain,ytrian,cv=
10).mean()
-
scorel.
append(score)
-
print(max(scorel),(scorel.index(max(scorel))*
10)+
1)
-
plt.figure(figsize=[
20,
5])
-
plt.plot(
range(
1,
201,
10),scorel)
-
plt.show()
0.8969014833647764 181

通过10重交叉验证,绘制学习曲线,确定模型森林数目为181,最高得分为0.8969
但是我们并不知道最高得分确实在181还是在其附近,所以需在181范围再进行一次验证
-
scorel = []
-
for i in
range(
175,
186):
-
rfc = RandomForestClassifier(n_estimators=i,
-
n_jobs=
-1,
-
random_state=
90)
-
score = cross_val_score(rfc,Xtrain,ytrian,cv=
10).mean()
-
scorel.
append(score)
-
print(max(scorel),([*
range(
175,
186)][scorel.index(max(scorel))]))
-
plt.figure(figsize=[
20,
5])
-
plt.plot(
range(
175,
186),scorel)
-
plt.show()
0.8969014833647764 181

很巧的是,181就是我们要找的最合适的森林数目。我们确定下来:n_estimators=181
- 网格搜索法确定其他参数
-
param_grid = {
'max_depth'
:np.arange(
1,
20,
1)}
-
-
rfc = RandomForestClassifier(n_estimators=
181
-
,random_state=
90
-
)
-
GS = GridSearchCV(rfc,param_grid,cv=
10)
-
GS.fit(Xtrain,ytrian)
-
GS.best_params
_
-
GS.best_score
_
{'max_depth': 14} 0.8996106314542068
经过漫长的计算,终于得到了结果。可以看到在树的最大层数为14层时,得到了最高分:0.8996,较之前上升了0.0027。我们确定下来max_depth=14。
-
param_grid = {
'min_samples_leaf'
:np.arange(
1,
20,
1)}
-
-
rfc = RandomForestClassifier(n_estimators=
181
-
,random_state=
90
-
)
-
GS = GridSearchCV(rfc,param_grid,cv=
10)
-
GS.fit(Xtrain,ytrian)
-
GS.best_params
_
-
GS.best_score
_
{'min_samples_leaf': 7} 0.899046329213927
又经过了漫长的等待,我们计算出了最佳min_samples_leaf参数为7, 最佳得分为0.8990。但是得分却下降了0.0006。我们知道决策树和随机森林是天生过拟合的模型。调节参数(预剪枝)几乎都是为了防止模型过拟合,调节min_samples_leaf后,模型就会进入欠拟合状态。所以max_depth=14时,可能是我们的模型已经到达的极限了。想要提升模型准确度,可能需要再从特征工程上着手了,调节其他参数将不再有效。
- 建立模型
0.9063981042654028
可以看出模型在测试集上的得分为0.906,结果还算不错。
- 输出比赛结果
-
data2 = pd.read_csv(
'test_set.csv')
-
ID = data2.ID
-
data2.drop([
'ID',
'day',
'month'], axis=
1, inplace=
True)
-
dummy = pd.get_dummies(data2[[
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'poutcome']])
-
data2= pd.concat([dummy, data2], axis=
1)
-
data2.drop([
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'poutcome'], axis=
1, inplace=
True)
-
pred = rfc.predict_proba(data2)
-
data3 = pd.DataFrame(pred, index=ID, columns=[
'pred0',
'pred'])
-
data3.drop(
'pred0', axis=
1, inplace=
True)
-
data3.to_csv(
'result.csv')
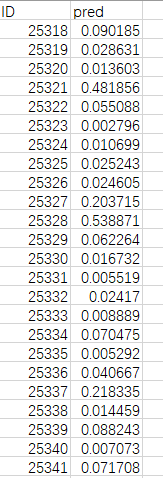
比赛结果要求字段为pred,表示预测客户订购定期存款业务的概率,部分结果如下图