1. TPOT介绍
一般来讲,创建一个机器学习模型需要经历以下几步:
- 数据预处理
- 特征工程
- 模型选择
- 超参数调整
- 模型保存
本文介绍一个基于遗传算法的快速模型选择及调参的方法,TPOT:一种基于Python的自动机器学习开发工具。项目源代码位于:https://github.com/EpistasisLab/tpot
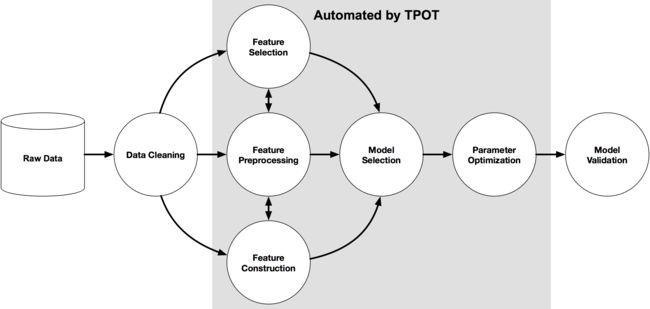
下图是一个机器学习模型开发图,其中灰色部分代表TPOT将要做的事情:即通过利用遗传算法,分析数千种可能的组合,为模型、参数找到最佳的组合,从而自动化机器学习中的模型选择及调参部分。
使用TPOT(版本0.9.5)开发模型需要把握以下几点:
- 在使用TPOT进行建模前需要对数据进行必要的清洗和特征工程操作。
- TPOT目前只能做有监督学习。
- TPOT目前支持的分类器主要有贝叶斯、决策树、集成树、SVM、KNN、线性模型、xgboost。
- TPOT目前支持的回归器主要有决策树、集成树、线性模型、xgboost。
- TPOT会对输入的数据做进一步处理操作,例如二值化、聚类、降维、标准化、正则化、独热编码操作等。
- 根据模型效果,TPOT会对输入特征做特征选择操作,包括基于树模型、基于方差、基于F-值的百分比。
- 可以通过export()方法把训练过程导出为形式为sklearn pipeline的.py文件
2. TPOT实现模型训练
下面是一个使用TPOT对MNIST数据集进行模型训练的例子:
# -*- coding: utf-8 -*- """ @author: wangkang @file: start_tpot.py @time: 2018/11/9 11:21 @desc: TPOT 实践 """ import time from tpot import TPOTClassifier from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split # 载入数据集 digits = load_digits() X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75, test_size=0.25) start = time.time() """ generations:运行管道优化过程的迭代次数 population_size:在遗传进化中每一代要保留的个体数量 verbosity: TPOT运行时能传递多少信息 """ # 使用TPOT初始化分类器模型 tpot = TPOTClassifier(generations=5, population_size=20, verbosity=0) # 模型训练 tpot.fit(X_train, y_train) print(tpot.score(X_test, y_test)) print('找到最优模型与超参数耗时:', time.time() - start) # 分类器其模型保存为 .py tpot.export('tpot_mnist_pipeline.py')
运行结果如下所示:

可以观察到,经过5次遗传进化,找到了此范围内得分最高的模型及参数组合!但观察代码耗时发现,在i5-7500 CPU @ 3.40GHz条件下,这5次迭代,共耗时1297 S。
我们可以打开生成的 tpot_mnist_pipeline.py 文件,如下所示:
import numpy as np import pandas as pd from sklearn.ensemble import ExtraTreesClassifier, GradientBoostingClassifier from sklearn.feature_selection import VarianceThreshold from sklearn.model_selection import train_test_split from sklearn.pipeline import make_pipeline, make_union from tpot.builtins import StackingEstimator """ # NOTE: Make sure that the class is labeled 'target' in the data file tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64) features = tpot_data.drop('target', axis=1).values training_features, testing_features, training_target, testing_target = \ train_test_split(features, tpot_data['target'].values, random_state=None) """ # 以上代码需修改为下面形式以供正确运行 from sklearn.datasets import load_digits digits = load_digits() X = digits.data y = digits.target training_features, testing_features, training_target, testing_target = \ train_test_split(X, y, random_state=None) # 此为由TPOT遗传算法得到的最优模型及参数组合 # Average CV score on the training set was:0.9792963424938936
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
ZeroCount(),
LinearSVC(C=0.5, dual=True, loss="squared_hinge", penalty="l2", tol=0.001)
)
exported_pipeline.fit(training_features, training_target) results = exported_pipeline.predict(testing_features)
print(results)
可以发现,训练好的模型以pipeline的形式保存(未进行持久化保存)。这样,整个关于MNIST数据集的分类器就训练完成了。
3. 总结
1、通过简单浏览源码发现,TPOT是在sklearn的基础之上做的封装库。其主要封装了sklearn的模型相关模块、processesing模块和feature_selection模块,所以TPOT的主要功能是集中在使用pipeline的方式完成模型的数据预处理、特征选择和模型选择方面。此外,我们还发现了TPOT已经对xgboost进行了支持。
2、虽然TPOT使用遗传算法代替了传统的网格搜索进行超参数选择,但由于默认初始值的随机性,在少量的进化(迭代)次数下,TPOT最终选择的模型往往并不相同。
3、计算效率问题。作者在代码中写道:进化(迭代)次数和每一代保留的个体数量值越多,最终得模型得分会越高。但这同样也会导致耗时很长。