本节的内容是衔接上节数据挖掘宽表处理的部分,上节分析了电信业客户流失问题分析预测的准备工作,这节继续进行探索性分析和建模分析及模型评估,客户流失预测分为流失规则的预测以及流失评分预测。本节的流失规则预测基于决策树算法,流失评分预测基于神经网络算法实现。
四、探索性数据分析
1、离散型变量
1)名义型离散变量
使用描述图形进行探索性分析:
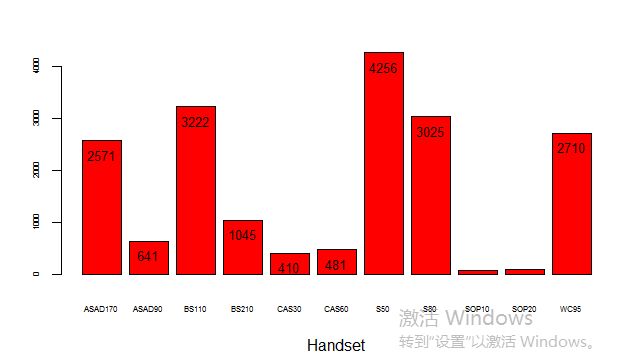
eg: 手机品牌的分布:
s<-summary(churn_analysis$Handset)
pie(s) #手机品牌分布


2)有序性离散变量
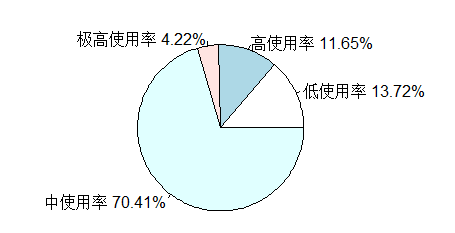
话务量级别:

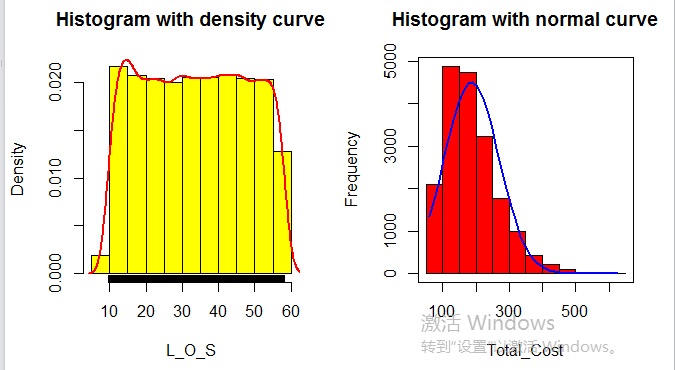
2、连续型变量
绘图:直方图、箱线图
在网时长和总通话费用的图形展现:

3、变量之间关系的探索性分析
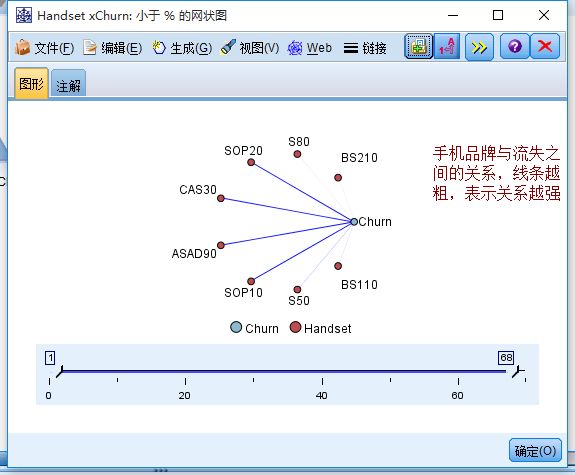
1)离散变量与离散变量
使用网络图分析:
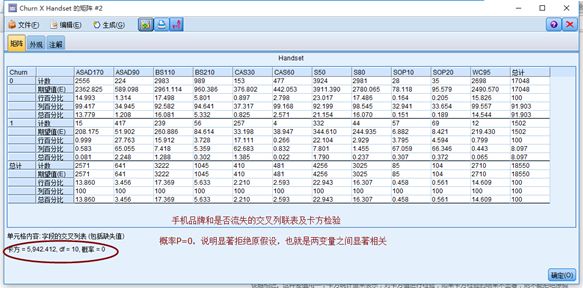
交叉列联表和卡方检验:SPSS Moderler输出节点“矩阵”,进行列联表分析:
2)离散变量与连续变量
高峰期通话时长与流失之间的关系:
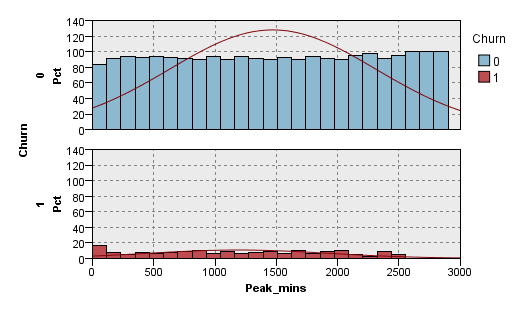

在0.05的显著性水平下,由F值可以看出流失客户与不流失客户的高峰期通话时长有着显著差异。
3)连续变量与连续变量
可以通过散点图直观展示,也可通过计算相关系数来展示:
五、、建立模型
1、细分类模型——聚类
适用于:客户价值较低的客户群
思路:使用客户的属性变量和行为变量(不包括是否流失)对客户进行聚类分析,分析各个群组的流失率情况,找出流失率较高的群组,并分析刻画他们的特征,以便业务人员有针对性的制订营销策略。
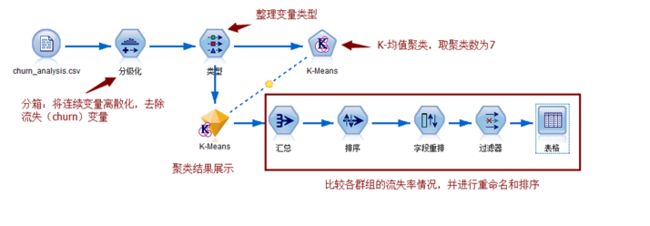
1)连续变量离散化处理

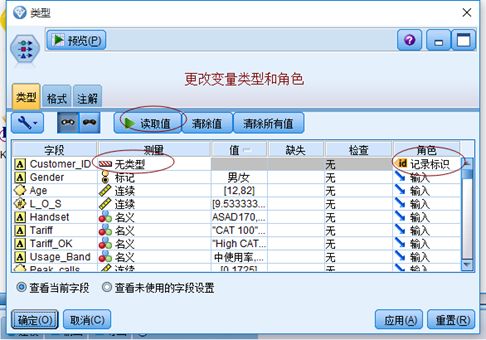
2)类型节点处理
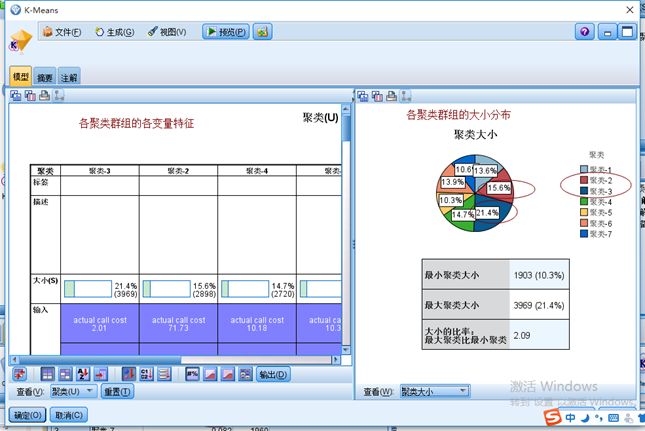
3)K-均值聚类
当k=7时,得到的聚类成果如下:
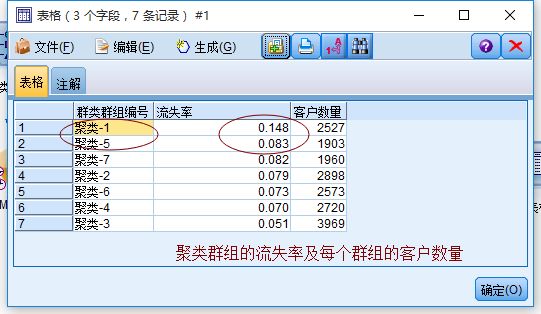
4)流失率计算
将这7个群组按照是否流失进行汇总,求出各群组的流失率

对以上的汇总结果进行变量排序和变量重命名后输出到表格中展示,如下:
5)特征分析
取流失率较高的两个群组(高流失客户群体),分析他们的特征,找出可能的流失原因。取聚类-1和聚类5两个群组,进行特征分析
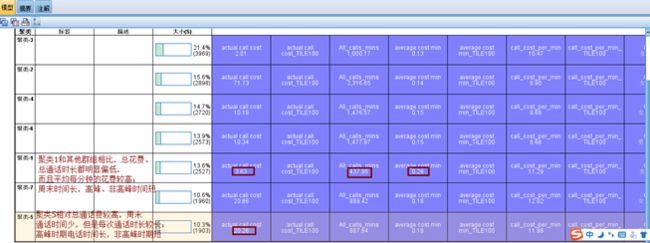

流失率较高的群组特征概括:
| 群组编号 |
群组占比 |
流失率 |
客户主要特征 |
特征概括 |
| 聚类-1 |
13.6% |
0.148 |
总花费较低 |
低价值客户 |
| 聚类-5 |
10.3% |
0.083 |
总花费较高 |
较高价值客户 |
以上为流失率较高的两类客户的特征概括,可以将这种模型提供给运营和营销人员,方便他们根据客户特征制定相关的营销策略,有效率地提高流失召回效率。
2、流失规则预测模型
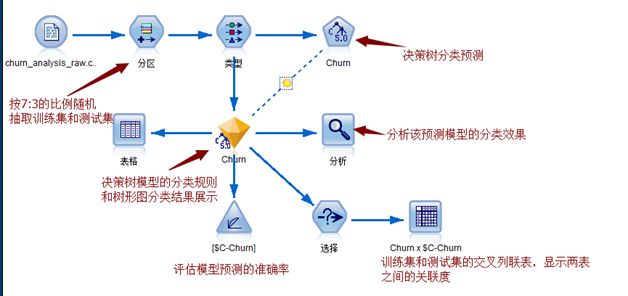
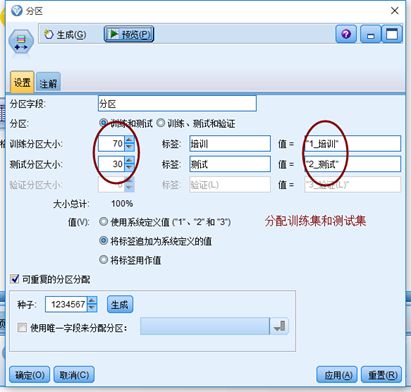
1)分区
按照7:3分配训练集和测试集,也可改变该分配比例来比较分类预测的效果
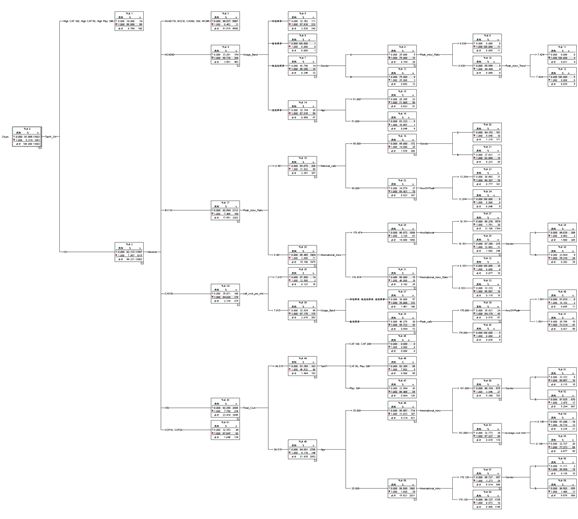
2)建立决策树模型

3)使用模型查看器查看决策树分类规则
Tariff_OK in [ "High CAT 100" "High CAT 50" "High Play 100" ] [ 模式:1 ] => 1
Tariff_OK in [ "OK" ] [ 模式:0 ]
Handset in [ "ASAD170" "BS210" "CAS60" "S80" "WC95" ] [ 模式:0 ] => 0
Handset in [ "ASAD90" ] [ 模式:1 ]
Usage_Band = 中使用率 [ 模式:1 ] => 1
Usage_Band = 低使用率 [ 模式:0 ] => 0
Usage_Band = 极高使用率 [ 模式:1 ]
Gender = 女 [ 模式:1 ]
Peak_mins_Ratio <= 0.830 [ 模式:1 ] => 1
Peak_mins_Ratio > 0.830 [ 模式:0 ]
Peak_mins_Trend <= 7.424 [ 模式:1 ] => 1
Peak_mins_Trend > 7.424 [ 模式:0 ] => 0
Gender = 男 [ 模式:0 ] => 0
Usage_Band = 高使用率 [ 模式:1 ]
Age <= 51 [ 模式:1 ] => 1
Age > 51 [ 模式:0 ] => 0
Handset in [ "BS110" ] [ 模式:0 ]
Peak_mins_Ratio <= 0.491 [ 模式:0 ]
National_calls <= 88 [ 模式:0 ]
Gender = 女 [ 模式:0 ] => 0
Gender = 男 [ 模式:1 ] => 1
National_calls > 88 [ 模式:1 ]
AveOffPeak <= 13.254 [ 模式:1 ] => 1
AveOffPeak > 13.254 [ 模式:0 ] => 0
Peak_mins_Ratio > 0.491 [ 模式:0 ]
International_mins <= 178.474 [ 模式:0 ]
AveNational <= 10.161 [ 模式:0 ] => 0
AveNational > 10.161 [ 模式:0 ]
Gender = 女 [ 模式:0 ] => 0
Gender = 男 [ 模式:1 ] => 1
International_mins > 178.474 [ 模式:0 ]
International_mins_Ratio <= 0.183 [ 模式:0 ] => 0
International_mins_Ratio > 0.183 [ 模式:1 ] => 1
Handset in [ "CAS30" ] [ 模式:1 ]
call_cost_per_min <= 7.915 [ 模式:0 ] => 0
call_cost_per_min > 7.915 [ 模式:1 ]
Usage_Band in [ "中使用率" "极高使用率" "高使用率" ] [ 模式:1 ] => 1
Usage_Band in [ "低使用率" ] [ 模式:1 ]
Peak_calls <= 176 [ 模式:1 ]
AveOffPeak <= 1.591 [ 模式:0 ] => 0
AveOffPeak > 1.591 [ 模式:1 ] => 1
Peak_calls > 176 [ 模式:0 ] => 0
Handset in [ "S50" ] [ 模式:0 ]
Total_Cost <= 99.515 [ 模式:0 ]
Tariff in [ "CAT 100" "CAT 200" ] [ 模式:0 ] => 0
Tariff in [ "CAT 50" "Play 300" ] [ 模式:0 ] => 0
Tariff in [ "Play 100" ] [ 模式:1 ] => 1
Total_Cost > 99.515 [ 模式:0 ]
Age <= 25 [ 模式:0 ]
International_mins <= 181.009 [ 模式:0 ]
Gender = 女 [ 模式:1 ] => 1
Gender = 男 [ 模式:0 ] => 0
International_mins > 181.009 [ 模式:1 ]
average cost min <= 0.145 [ 模式:0 ] => 0
average cost min > 0.145 [ 模式:1 ] => 1
Age > 25 [ 模式:0 ]
International_mins <= 178.126 [ 模式:0 ]
Gender = 女 [ 模式:1 ] => 1
Gender = 男 [ 模式:0 ] => 0
International_mins > 178.126 [ 模式:0 ] => 0
Handset in [ "SOP10" "SOP20" ] [ 模式:1 ] => 1
4)决策树
5)查看分类训练和预测结果

6)生成SQL脚本
a) 生成模型后选择生成SQL脚本
*注:boosting默认不能生成SQL脚本
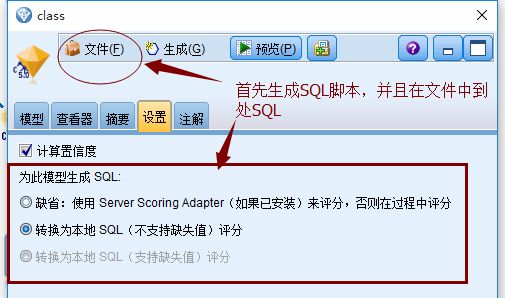
b) 接下来,将SQL脚本导入PL/SQL中:
文件—>打开—>SQL脚本
c) 将数据EXCEL表导入PL/SQL中:
对于数据集较小的表:
可以先在数据库中建立一个表(CLASS)
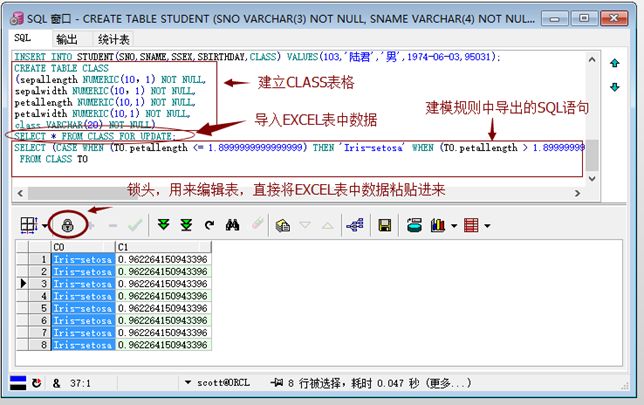
最终显示的结果为C0和C1两列值,C0表示的是预测值,C1表示预测的准确率。
7)模型评估
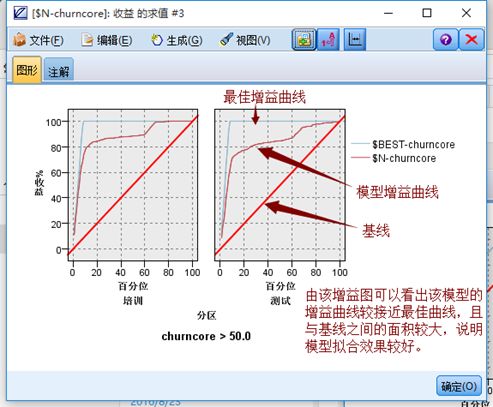
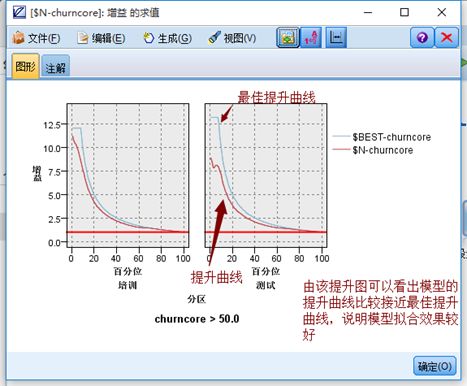
提升图:
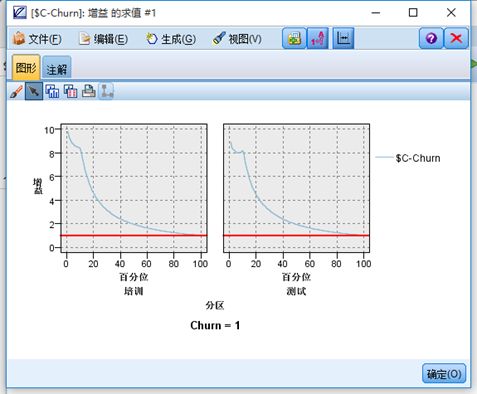
图形结果显示,提升度随RPP(正类预测比例)的提高呈降序分布,且提升度较高,说明模型的预测准确率较高,比随机预测提升了较高的水平。
ROC曲线:

ROC曲线显示预测模型对1的敏感度很高,说明模型的预测效果很好。
8)模型分析

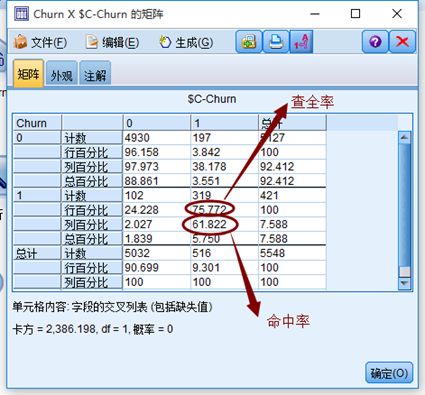
结果显示模型的整体预测准去率达到了94.61%,而且模型的命中率为61.82%,模型的查全率为75.78%。
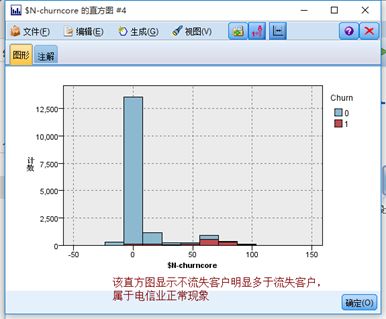
3、流失评分预测模型(神经网络算法实现)
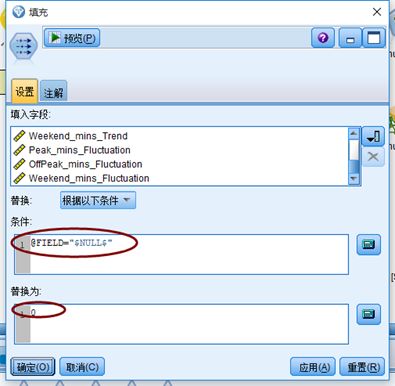
1)缺失值处理
将空值取值为0
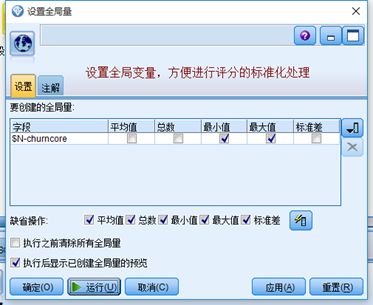
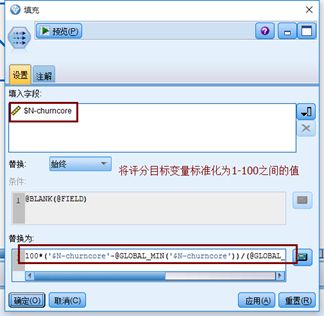
2)离散目标变量(churn)更改为连续目标变量(churncore)
将1取值为100
0取值为0

3)随机抽取训练集和测试集

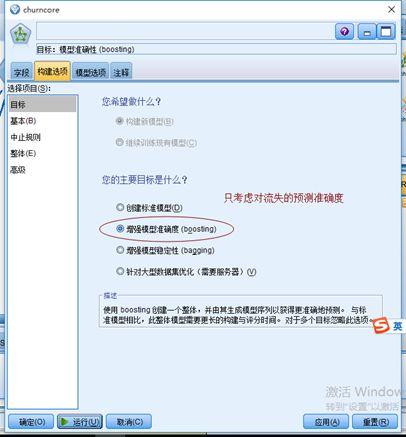
4)建立神经网络模型
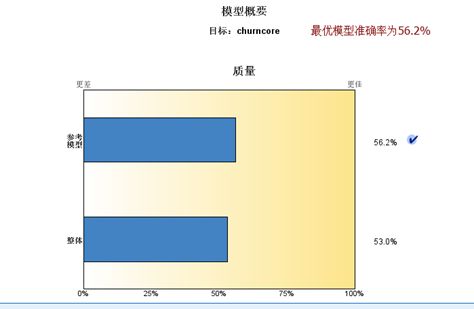
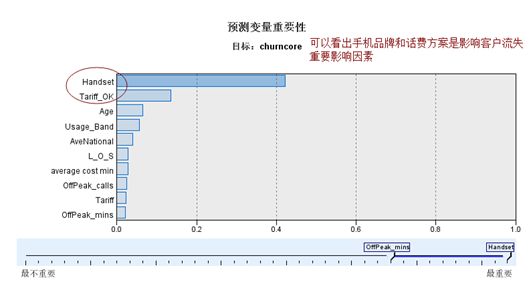
5)模型分析和评估