新晋 ACM Fellow 陶大程,8 篇 NeurIPS 论文详解
2019-12-26 06:17:03

作者 | AI科技评论
编辑 | 刘萍
近日2019年 ACM Fellows 增选结果出炉之后,备受人们关注,其中除谢源、周礼栋、陈熙霖等业界和学术界著名学者外,目前在悉尼大学任教、且担任优必选科技人工智能首席科学家的陶大程教授也是人们瞩目的焦点。

陶大程于2002年毕业于中国科学技术大学,2004年获得香港中文大学硕士学位,2007年获得英国伦敦大学博士学位。
如今年仅40岁左右,陶大程已然成为ACM Fellow(2019)、IEEE Fellow(2014)、IAPR Fellow(2012)等,且2016年当选欧洲科学院外籍院士,诸多荣誉加身,可谓是青年学者中的翘楚。
这些荣誉是和他巨量的、且重要的研究成果分不开的。截止2019年12月,Google Scholar显示他的引用已经达到45000+,h-index为110。
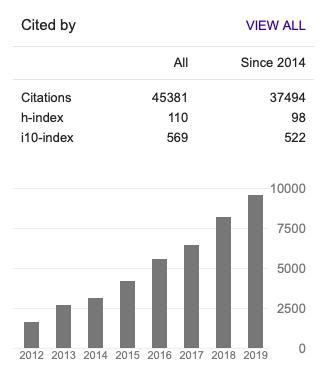
最近(12月8日-14日)在加拿大温哥华举办的NeurIPS 2019中,陶大程教授(带领下的优必选悉尼大学AI中心)共有 8 篇论文入选,也成为本届会议入选论文数量最多的华人学者。
这些论文也代表了陶大程教授近期的研究主题和进展,近日陶大程团队人员将这些论文整理并做详细解读,分享给读者如下:
编者注:如对论文内容感兴趣,可关注 微信公众号「AI 科技评论」,回复「陶大程@NeurIPS2019」,打包下载全部 8 篇论文。
论文一
学习、想象与创造:从先验知识生成文本到图像(Learn, Imagine and Create: Text-to-Image Generation from Prior Knowledge)

文本到图像的生成,即在给定文本描述的情况下生成图像,是一项非常具有挑战性的任务,原因是文本和图像之间存在着巨大的语义鸿沟。但是,人类可以聪明地解决这个问题。
我们从各种对象中学习,对语义、纹理、颜色、形状和布局形成可靠的先验认识。给定文本描述后,我们会立即利用这种先验想象整体视觉效果,并在此基础上,通过逐渐添加越来越多的细节来绘制图片。
受此过程的启发,我们在本文中提出了一种名为 LeicaGAN 的新的文本到图像的方法。该方法可以将上述三个阶段合并到一个统一的框架中。
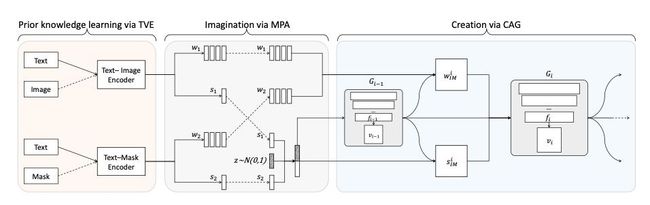
首先,我们将多个先验学习阶段定义为一个文本-视觉共嵌入(TVE)阶段,其中包括用于学习语义、纹理和颜色先验的文本图像编码器以及用于学习形状和布局先验的文本掩码编码器。
然后,我们将这些互补的先验相结合,并加入噪声以实现多样性,将想象阶段表述为多重先验聚合(MPA)。
最后,我们用一个级联精细生成器(CAG)来描述创造阶段,逐步从粗糙到精细地绘制图片。

我们利用对抗性学习,让 LeicaGAN 增强语义一致性和视觉逼真度。在两个公开基准数据集上进行的全面实验证明了 LeicaGAN 优于基线法。
论文地址:https://papers.nips.cc/paper/8375-learn-imagine-and-create-text-to-image-generation-from-prior-knowledge.pdf
论文二
类别锚引导的无监督域自适应语义分割(Category Anchor-Guided Unsupervised Domain Adaptation for Semantic Segmentation)

无监督域自适应(UDA)旨在增强特定模型从源域到目标域的泛化能力。UDA 具有特别的意义,因为无需对目标域样本进行额外的注释。但是,两个域中的不同数据分布或\ emph {域移位/差异}会不可避免地会影响 UDA 的性能。尽管在匹配两个域之间的边缘分布方面已经取得一些进展,但是由于与类别无关的特征对齐,分类器倾向于源域特征,并对目标域做出错误的预测。
在本文中,我们提出了一种新的类别锚导向(CAG)语义分割 UDA 模型,该模型显式实施类别感知特征对齐,以同时学习共享的鉴别功能和分类器。
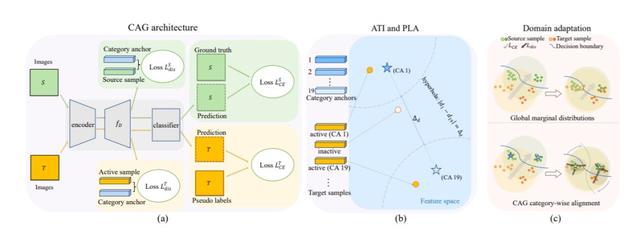
首先,使用源域特征的分类中心作为引导锚来识别目标域中的活动特征,并为其分配伪标签。
然后,我们利用基于锚点的像素级距离损失和鉴别损失来分别驱动类别内特征和类别间特征的进一步分离。
最后,我们设计了一种分阶段的训练机制,以减少误差累积,并逐步适应所提出的模型。
在 GTA5Cityscapes 和 SYNTHIACityscapes 场景的实验都证明了我们的CAG-UDA 模型优于最先进的方法。
论文链接:https://papers.nips.cc/paper/8335-category-anchor-guided-unsupervised-domain-adaptation-for-semantic-segmentation.pdf
论文三
控制批次大小和学习率以实现良好的泛化:理论和经验证据(Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence)

基于随机梯度下降(SGD)的优化方法,深度神经网络已获得巨大的成功。但是,如何调整超参数(尤其是批次大小和学习率)以确保良好的泛化我们还不清楚。
本文描述了一种训练策略的理论和经验证据,即我们应该控制批次与学习率不要太大,以获得良好的泛化能力。
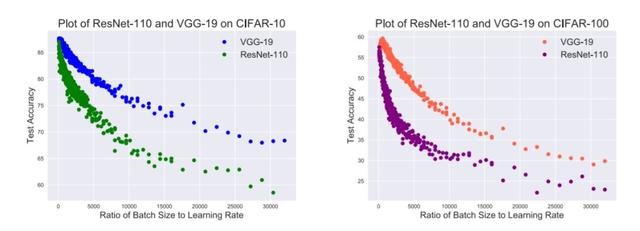
具体来说,我们证明了由 SGD 训练的神经网络的 PAC-Bayes 泛化约束,它与批次大小与学习率之比呈正相关。这种相关性为训练策略的制定奠定了理论基础。
此外,我们进行了一项旨在验证相关性和训练策略的大规模实验。我们在严格控制不相关变量的同时,使用数据集 CIFAR-10 和 CIFAR-100 对基于架构 ResNet-110 和 VGG-19 的 1600 个模型进行了训练。我们采集了测试集的准确性以进行评估。我们采集的 164 组数据中,Spearman 的排名相关系数和对应的 p 值表明,相关性具有显著的统计学意义,完全支持训练策略。
论文地址:https://openreview.net/pdf?id=BJfTE4BxUB
论文四
云端未标记正压缩(Positive-Unlabeled Compression on the Cloud)

为了将卷积神经网络(CNNs)在高端 GPU 服务器上取得的巨大成功扩展到智能手机等便携设备上,人们做了很多尝试。因此,在云端提供深度学习模型的压缩和加速服务具有重要意义,对最终用户很有吸引力。但是,现有的网络压缩和加速方法通常会通过请求完整的原始训练数据(例如 ImageNet)来微调 svelte 模型,这可能比网络本身更为繁琐,而且无法轻松上传到云端。
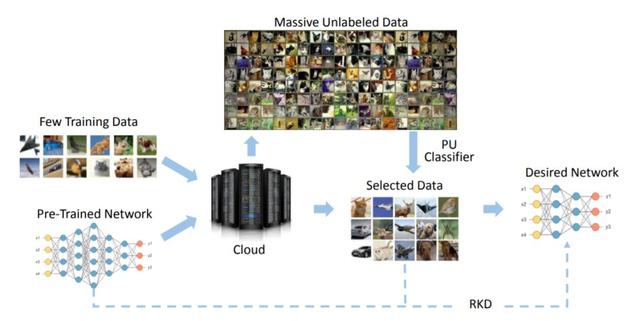
在本文中,我们提出了一种新的未标记正(PU)设置来解决这个问题。实际上,只需将原始训练集的一小部分作为正面示例,通过具有基于注意力的多尺度特征提取器的 PU 分类器,就可以从云端未标记的海量数据中获得更多有用的训练实例。
我们进一步介绍了一个稳健的知识提炼(RKD)方案来处理这些新增加的训练实例的类别不平衡问题。
通过对基准模型和数据集进行的实验,我们验证了该方法的优越性。我们只能使用 ImageNet 中均匀选择数据的 8% 来获得性能与基准 ResNet-34 相当的高效模型。
论文地址:https://papers.nips.cc/paper/8525-positive-unlabeled-compression-on-the-cloud.pdf
论文五
LIIR:多智能体强化学习中的学习个体内在奖励(LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning)

协同分散式多智能体强化学习(MARL)面临的一个重大挑战是,在只获得团队奖励时,如何使每个智能体都产生多样化的行为。在先前的研究中,在奖励塑造或设计可区别对待智能体的集中批评机制方面已付出了很多努力。
在本文中,我们建议合并两个方向,并向每个智能体学习内在的奖励功能,该功能在每个时间步都对智能体产生不同的刺激。
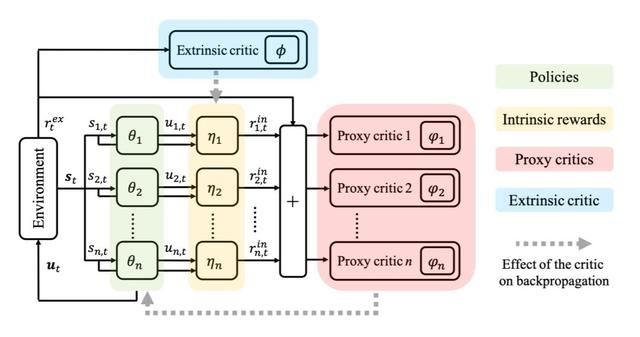
具体来说,特定智能体的内在报酬将涉及为其计算一个不同的智能体批评机制,以指导其个别策略的更新。同时,将对参数化的内在奖励功能进行更新,使其最大程度地满足环境对团队累积奖励的期望,从而使目标与原 MARL 问题保持一致。
该方法称为 MARL 中的学习个体内在奖励(LIIR)。我们将 LIIR 与《星际争霸 2》中的战斗游戏中许多最先进的 MARL 方法进行了比较。结果证明了 LIIR 的有效性,我们还证明,LIIR 可以在每个时间步为每个智能体分配一个有洞察力的内在奖励。
论文地址:https://papers.nips.cc/paper/8691-liir-learning-individual-intrinsic-reward-in-multi-agent-reinforcement-learning.pdf
论文六
通过生成从不良数据中学习(Learning from Bad Data via Generation)

不良的训练数据将通过理解底层的数据生成方案来挑战学习模型,从而增加了在不可见的测试数据上获得满意性能的难度。
我们假设实际数据分布是由不良数据的经验分布支持的分布集。在此分布集上可得出最坏情况的公式,然后将其解释为一种对抗性的生成任务。
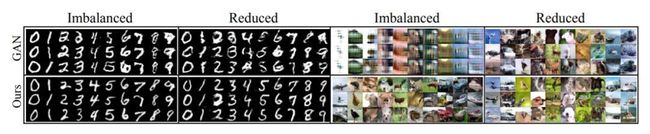
我们还对 GANs 与我们框架之间的联系和差异进行了深入的讨论。我们进一步从理论上说明了这一生成任务对从不良数据中学习的影响,并揭示了其与数据相关正则化的联系。给定不同的距离度量(例如 Wasserstein 距离或 JS 散度),我们可以得出该问题的不同目标函数。
我们对不同类型的不良训练数据的实验结果表明了该方法的必要性和有效性。
论文地址:https://papers.nips.cc/paper/8837-learning-from-bad-data-via-generation.pdf
论文七
无可能性过完备独立成分分析(ICA)及其在因果发现中的应用(Likelihood-Free Overcomplete ICA and Applications In Causal Discovery)

因果关系发现在过去几十年中取得了重大进展。特别是,许多最近的因果发现方法都利用独立的非高斯噪声来实现因果模型的可识别性。隐藏的直接常见原因或混杂因素的存在通常使因果发现更加困难;当这些原因或因素存在时,相应的因果发现算法都可以看作是对过完备独立成分分析(OICA)的扩展。
但是,现有的 OICA 算法往往会对独立成分的分布做出严格的参数假设,而实际数据可能会违反这些假设,从而导致次优甚至错误的解决方案。此外,现有的 OICA 算法依赖于期望最大化(EM)程序,该程序要求对独立成分的后验分布进行计算代价高昂的推断。
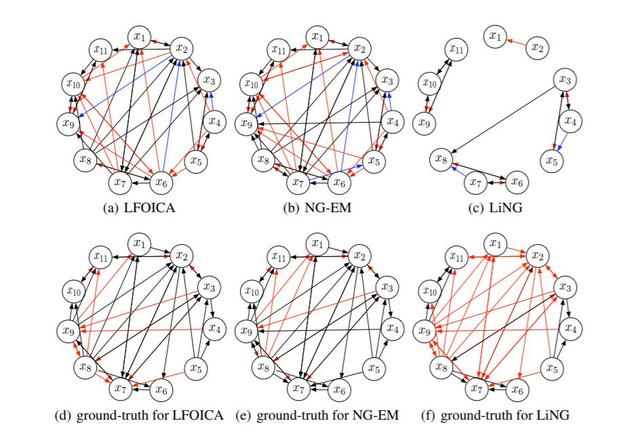
为了解决这些问题,我们提出了一种无可能性过完备独立成分分析算法(LFOICA),该算法通过反向传播直接估计混合矩阵,而无需对独立成分的密度函数做出任何明确的假设。该方法具有较高的计算效率,使得许多因果发现过程在实际应用中更加可行。为了加以说明,我们在两个因果发现任务中证明了我们方法的计算效率和有效性。
论文地址:https://papers.nips.cc/paper/8912-likelihood-free-overcomplete-ica-and-applications-in-causal-discovery.pdf
论文八
对抗性学习的理论分析:一种极小极大法(Theoretical Analysis of Adversarial Learning: A Minimax Approach)

在本文中,我们提出了一个分析对手存在时的风险边界的一般理论方法。具体地,我们尝试将对抗性学习问题纳入极小极大框架中。
我们首先表明,通过引入分布之间的传输图,可以将原来的对抗性学习问题转化为极小极大统计学习问题。
然后,我们证明了在利普希茨连续条件较弱时,关于覆盖数的极小极大问题的新风险界限。
我们的方法可以应用于多类分类和常用损失函数,包括铰链损失和斜坡损失。作为一些说明性示例,我们推导了 SVM 和深度神经网络的对抗风险界限,我们的界限具有两个与数据相关的项,可对其进行优化以实现对抗的稳健性。
论文地址:https://papers.nips.cc/paper/9394-theoretical-analysis-of-adversarial-learning-a-minimax-approach.pdf