数据结构:图结构的实现
数据结构:图结构的实现
图(Graph)是由顶点和连接顶点的边构成的离散结构。在计算机科学中,图是最灵活的数据结构之一,很多问题都可以使用图模型进行建模求解。例如:生态环境中不同物种的相互竞争、人与人之间的社交与关系网络、化学上用图区分结构不同但分子式相同的同分异构体、分析计算机网络的拓扑结构确定两台计算机是否可以通信、找到两个城市之间的最短路径等等。
额,我都不研究这些问题。之所以重新回顾数据结构,仅仅是为了好玩。图(Graph)通常会放在树(Tree)后面介绍,树可以说只是图的特例,但是我觉得就基础算法而言,树比图复杂很多,而且听起来也没什么好玩的(左左旋、左右旋、右右旋、右左旋,好无聊~)。因此,我写的第一篇数据结构的笔记就从图开始。
1 图的概念
1.1 图的基础概念串讲
图的结构很简单,就是由顶点 V V V 集和边 E E E 集构成,因此图可以表示成 G = ( V , E ) G=(V, E) G=(V,E) 。

图1-1:无向图1
图1-1就是无向图,我们可以说这张图中,有点集 V = { 1 , 2 , 3 , 4 , 5 , 6 } V=\{1, 2, 3, 4, 5, 6\} V={1,2,3,4,5,6},边集 E = { ( 1 , 2 ) , ( 1 , 5 ) , ( 2 , 3 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 4 , 5 ) , ( 4 , 6 ) } E=\{(1, 2), (1, 5), (2, 3), (2, 5), (3, 4), (4, 5), (4, 6)\} E={(1,2),(1,5),(2,3),(2,5),(3,4),(4,5),(4,6)} 。在无向图中,边 ( u , v ) (u, v) (u,v)和边 ( v , u ) (v, u) (v,u)是一样的,因此只要记录一个就行了。简而言之,对称。

图1-2:有向图 2
有向图也很好理解,就是加上了方向性,顶点 ( u , v ) (u, v) (u,v)之间的关系和顶点 ( v , u ) (v,u) (v,u)之间的关系不同,后者或许不存在。例如,地图应用中必须存储单行道的信息,避免给出错误的方向。
加权图:与加权图对应的就是无权图,如果觉得不好听,那就叫等权图。如果一张图不含权重信息,我们就认为边与边之间没有差别。不过,具体建模的时候,很多时候都需要有权重,比如对中国重要城市间道路联系的建模,总不能认为从北京去上海和从北京去广州一样远(等权)。
还有很多细化的概念,有兴趣的自己了解咯。我觉得就没必要单独拎出来写,比如:无向图中,任意两个顶点间都有边,称为无向完全图;加权图起一个新名字,叫网(network)……然而,如无必要,毋增实体。
两个重要关系:
- 邻接(adjacency):邻接是两个顶点之间的一种关系。如果图包含 ( u , v ) (u,v) (u,v),则称顶点 v v v与顶点 u u u邻接。当然,在无向图中,这也意味着顶点 u u u与顶点 v v v邻接。
- 关联(incidence):关联是边和顶点之间的关系。在有向图中,边 ( u , v ) (u,v) (u,v)从顶点 u u u开始关联到 v v v,或者相反,从 v v v关联到 u u u。注意,有向图中,边不一定是对称的,有去无回是完全有可能的。
细化关联这个概念,就有了顶点的入度(in-degree)和出度(out-degree)。无向图中,顶点的度就是与顶点相关联的边的数目,没有入度和出度。在有向图中,我们以图1-2为例,顶点10有2个入度, 3 → 10 3\rightarrow10 3→10, 11 → 10 11\rightarrow10 11→10,但是没有从10指向其它顶点的边,因此顶点10的出度为0。
路径(path):依次遍历顶点序列之间的边所形成的轨迹。注意,依次就意味着有序,先1后2和先2后1不一样。
简单路径:没有重复顶点的路径称为简单路径。说白了,这一趟路里没有出现绕了一圈回到同一点的情况,也就是没有环。

图1-3:四顶点的有向带环图3
环:包含相同的顶点两次或者两次以上。图1-3中的顶点序列 < 1 , 2 , 4 , 3 , 1 > <1,2,4,3,1> <1,2,4,3,1>,1出现了两次,当然还有其它的环,比如 < 1 , 4 , 3 , 1 > <1,4,3,1> <1,4,3,1>。
无环图:没有环的图,其中,有向无环图有特殊的名称,叫做DAG(Directed Acyline Graph)(最好记住,DAG具有一些很好性质,比如很多动态规划的问题都可以转化成DAG中的最长路径、最短路径或者路径计数的问题)。
下面这个概念很重要:

图1-4:两个连通分支
连通的:无向图中每一对不同的顶点之间都有路径。如果这个条件在有向图里也成立,那么就是强连通的。图1-4中的图不是连通的,我丝毫没有侮辱你智商的意思,我只是想和你说,这图是我画的,顶点标签有点小,应该看到a和d之间没有通路。
-
连通分支:不连通的图是由2个或者2个以上的连通分支的并。这些不相交的连通子图称为图的连通分支。
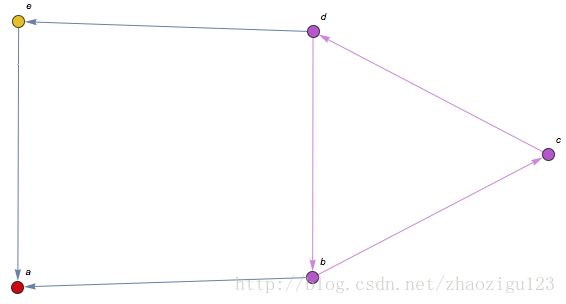
图1-5:有向图的连通分支 -
有向图的连通分支:将有向图的方向忽略后,任何两个顶点之间总是存在路径,则该有向图是弱连通的。有向图的子图是强连通的,且不包含在更大的连通子图中,则可以称为图的强连通分支。
图1-5中, a a a、 e e e没有到 { b , c , d } \{b,c,d\} {b,c,d}中的顶点的路径,所以各自是独立的连通分支。因此,图1-5中的图有三个强连通分支,用集合写出来就是: { { a } , { e } , { b , c , d } } \{\{a\}, \{e\}, \{b, c, d\}\} {{a},{e},{b,c,d}}(已经用不同颜色标出)。

图1-6:关节点
关节点(割点):某些特定的顶点对于保持图或连通分支的连通性有特殊的重要意义。如果移除某个顶点将使图或者分支失去连通性,则称该顶点为关节点。如图1-6中的c。
双连通图:不含任何关节点的图。
关节点的重要性不言而喻。如果你想要破坏互联网,你就应该找到它的关节点。同样,要防范敌人的攻击,首要保护的也应该是关节点。在资源总量有限的前提下,找出关节点并给予特别保障,是提高系统整体稳定性和鲁棒性的基本策略。
桥(割边):和关节点类似,删除一条边,就产生比原图更多的连通分支的子图,这条边就称为割边或者桥。
1.2 一些有趣的图概念
这一部分属于图论的内容,基础图算法不会用到,但是我觉得挺有意思的,小记如下。
同构4:图看起来结构不一样,但它是一样的。假定有 G 1 G_1 G1和 G 2 G_2 G2,那么你只要确认对于 G 1 G_1 G1中的所有的两个相邻点 a a a和 b b b,可以通过某种方式 f f f映射到 G 2 G_2 G2,映射后的两个点 f ( a ) f(a) f(a)、 f ( b ) f(b) f(b)也是相邻的。换句话说,当两个简单图同构时,两个图的顶点之间保持相邻关系的一一对应。
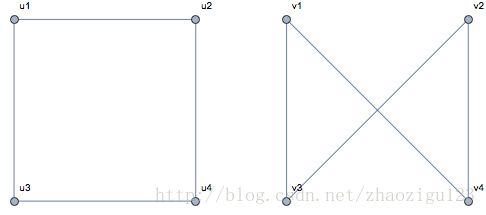
图1-7:图的同构
图1-7就展示了图的同构,这里顶点个数很少判断图的同构很简单。我们可以把v1看成u1,自然我们会把u3看出v3。用数学的语言就是 f ( u 1 ) = v 1 f(u_1)=v_1 f(u1)=v1, f ( u 3 ) = v 3 f(u_3)=v_3 f(u3)=v3。u1的另外一个连接是到u2,v1的另外一个连接是到v4,不难从相邻顶点的关系验证 f ( u 2 ) = v 4 f(u_2)=v_4 f(u2)=v4, f ( u 4 ) = v 2 f(u_4)=v_2 f(u4)=v2。
欧拉回路(Euler Circuit):小学数学课本上的哥尼斯堡七桥问题,能不能从镇里的某个位置出发不重复的经过所有桥(边)并且返回出发点。这也就小学的一笔画问题,欧拉大神解决里这个问题,开创了图论。
结论很简单:至少2个顶点的连通多重图存在欧拉回路的充要条件是每个顶点的度都是偶数。证明也很容易,大家有兴趣可以阅读相关资料。结论也很好理解,从某个起点出发,最后要回起点,中间无论路过多少次起点,都会再次离开,进、出的数目必然相等,故一定是偶数。
哈密顿回路(Hamilton Circuit):哈密顿回路条件就比欧拉回路严格一点,不能重复经过点。你可能会感到意外,对于欧拉回路,我们可以轻而易举地回答,但是我们却很难解决哈密顿回路问题,实际上它是一个NP完全问题。
这个术语源自1857年爱尔兰数学家威廉·罗万·哈密顿爵士发明的智力题。哈密顿的智力题用到了木质十二面体(如图1-8(a)所示,十二面体有12个正五边形表面)、十二面体每个顶点上的钉子、以及细线。十二面体的20个顶点用世界上的不同城市标记。智力题要求从一个城市开始,沿十二面体的边旅行,访问其他19个城市,每个恰好一次,最终回到第一个城市。

图1-8:哈密顿回路问题
因为作者不可能向每位读者提供带钉子和细线的木质十二面体,所以考虑了一个等价的问题:对图1-8(b)的图是否具有恰好经过每个顶点一次的回路?它就是对原题的解,因为这个平面图同构于十二面体顶点和边。
著名的**旅行商问题(TSP)**要求旅行商访问一组城市所应当选取的最短路线。这个问题可以归结为求完全图的哈密顿回路,使这个回路的边的权重和尽可能的小。同样,因为这是个NP完全问题,最直截了当的方法就检查所有可能的哈密顿回路,然后选择权重和最小的。当然这样效率几乎难以忍受,时间复杂度高达 O ( n ! ) O(n!) O(n!)。
在实际应用中,我们使用的启发式搜索等近似算法,可以完全求解城市数量上万的实例,并且甚至能在误差1%范围内估计上百万个城市的问题。
关于旅行商问题目前的研究进展,可以到http://www.math.uwaterloo.ca/tsp/进一步了解。
1.3 小结
以为可以一带而过,结果写了那么多。也没什么好总结的了,当然这些也至是图论概念的一小部分,还有一些图可能我们以后也会见到,比如顺着图到网络流,就会涉及二分图,不过都很好理解,毕竟有图。
2 图的表示
2.1 邻接链表与邻接矩阵
图最常见的表示形式为邻接链表和邻接矩阵。邻接链接在表示稀疏图时非常紧凑而成为了通常的选择,相比之下,如果在稀疏图表示时使用邻接矩阵,会浪费很多内存空间,遍历的时候也会增加开销。但是,这不是绝对的。如果图是稠密图,邻接链表的优势就不明显了,那么就可以选择更加方便的邻接矩阵。
还有,顶点之间有多种关系的时候,也不适合使用矩阵。因为表示的时候,矩阵中的每一个元素都会被当作一个表。
2.1.1 存储问题
如果使用邻接矩阵还要注意存储问题。矩阵需要 n 2 n^2 n2个元素的存储空间,声明的又是连续的空间地址。由于计算机内存的限制,存储的顶点数目也是有限的,例如:Java的虚拟机的堆的默认大小是物理内存的1/4,或者1G。以1G计算,那么创建一个二维的int[16384][16384]的邻接矩阵就已经超出内存限制了。含有上百万个顶点的图是很常见的, V 2 V^2 V2的空间是不能满足的。
因此,偷个懒,如果对邻接矩阵感兴趣,可以自己找点资料。很容易理解的。
2.1.2 邻接链表的实现
邻接链表的实现会比邻接矩阵麻烦一点,但是邻接链表的综合能力,包括鲁棒性、拓展性都比邻接矩阵强很多。没办法,只能忍了。
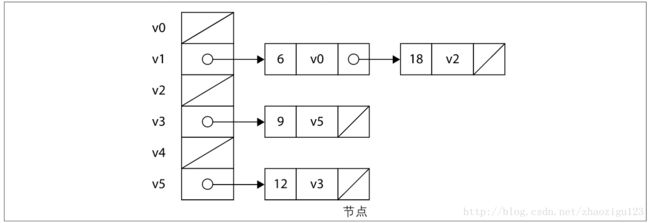
图1-9:邻接链表示意图
从图1-9不能看出邻接链表可以用线性表构成。顶点可以保持在数组或者向量(vector)中,邻接关系则用链表实现,利用链表高效的插入和删除,实现内存的充分利用。有利必有弊,邻接矩阵可以高效的判定两个顶点之间是否有邻接关系,邻接链表无疑要遍历一次链表。
邻接链表的瓶颈在于链表的查找上,如果换成高效的查找结构,就可以进一步地提高性能。例如,把保存顶点邻接关系的链表换成通常以红黑树为基础set。如果一定要名副其实,就要叫成邻接集。类似的,顶点的保存也有“改进”方案。比如,使用vector通常用int表示顶点,也无法高效地进行顶点的插入删除。如果把顶点的保存换成链表,无疑可以高效地进行顶点的插入和删除,但是访问能力又会大打折扣。没错,我们可以使用set或者map来保存顶点信息。
C++11中引入了以散列表为基础unordered_set和unordered_map,就查找和插入而言,统计性能可能会高于红黑树,然而,散列表会带来额外的内存开销,这是值得注意的。
具体问题,具体分析,图的结构不同,实现图的结构也应该随之不同。大概也是这个原因,像C++、Java、Python等语言,都不提供具体的Graph。举个例子,直接使用vector保存顶点信息,list保存邻接关系,使用的顶点id连续5。那么在添加边 O ( 1 ) O(1) O(1),遍历顶点的邻接关系 O ( V ) O(V) O(V)还有空间消耗 O ( V + E ) O(V+E) O(V+E)上都是最优的。当然,类似频繁删除边,添加边(不允许平行边),删除顶点,添加顶点,那么这种比较简易的结构就不太适合了。
2.3 量化选择
我们稍微量化一下稀疏图和稠密图的标准。当我们声称图的是稀疏的,我们近似地认为边的数量 ∣ E ∣ |E| ∣E∣大致等于顶点的个数 ∣ V ∣ |V| ∣V∣,在稠密图中,我们可以不难得到 ∣ E ∣ |E| ∣E∣近似为 ∣ V 2 ∣ |V^2| ∣V2∣。在此,我们不妨定义均衡图是边的数量为 ∣ V 2 ∣ / log ∣ V ∣ |V^2|/\log |V| ∣V2∣/log∣V∣的图。
图算法中,根据图的结构,经常会有两个算法变种,时间复杂度也不尽相同。可能有一个是 O ( ( V + E ) log V ) O((V+E)\log V) O((V+E)logV),另一个是 O ( V 2 + E ) O(V^2+E) O(V2+E)。选择哪个算法更为高效取决于图是否是稀疏的。
| 图类型 | O ( ( V + E ) log V ) O((V+E)\log V) O((V+E)logV) | 比较关系 | O ( V 2 + E ) O(V^2+E) O(V2+E) |
|---|---|---|---|
| 稀疏图: E E E是 O ( V ) O(V) O(V) | O ( V log V ) O(V\log V) O(VlogV) | < | O ( V 2 ) O(V^2) O(V2) |
| 均衡图: E E E是 O ( V 2 / log V ) O(V^2/\log V) O(V2/logV) | O ( V 2 + V log V ) = O ( V 2 ) O(V^2+V\log V)=O(V^2) O(V2+VlogV)=O(V2) | = | O ( V 2 + V 2 / log V ) = O ( V 2 ) O(V^2+V^2/\log V)=O(V^2) O(V2+V2/logV)=O(V2) |
| 稠密图: E E E是 O ( V 2 ) O(V^2) O(V2) | O ( V 2 log V ) O(V^2\log V) O(V2logV) | > | O ( V 2 ) O(V^2) O(V2) |
3 图的实现
3.1 代码约定
因为用Markdown,所以我怕有时候排版的时候空格出现问题,4空格调整太麻烦,加上可能4空格有时候不是特别紧凑,所以代码全部是2空格缩进。另外,我就不打算像教科书一样写那种一本正经的代码,拆成头文件加源文件。还有很多偷懒和不负责的地方,不过,换来了性能。还有,auto还是挺好用的,因此代码会用到少量C++11。
3.2 想想需要什么功能
3.2.1 图的数据结构
就学习算法的目的而言,频繁添加和删除顶点是不需要的,因此代码实现时,为方便起见顶点仍然使用vector保存,边的话进阶点,使用set,这样就防止出现平行边了。还有,我比较放心自己,很多方法不加检查。还是那句话,具体问题,具体分析,具体实现。
3.2.2 图的操作
既然选择用vector+set,我们来考虑一下基本操作,至于那些后来算法用到的,后面再补充实现。
数据成员:
- 边的数量
- 顶点的数量
- 由
vector和set构成的图结构
功能:
- 添加边
- 删除边
- 添加顶点
- 删除顶点
- 判断是否有邻接关系
- 返回顶点的邻接集:不推荐直接使用这个,建议用迭代器
- 迭代器
begin、cbegin - 迭代器
end、cend
其它
- 构造:初始化
n个顶点 - 构造:从字符串读取文件中的图信息,便于加载图信息
- 析构函数:都是使用STL和动态变量,不用我们操心
- 数据成员的取值方法
- 辅助方法:打印图
3.3.3 声明与内联实现
#include
#include 3.3 开工
因为图结构实现还是比较简单的,代码都很短。
3.3.1 从文件中构造图
文件格式,先顶点数量、边数量,然后顶点对表示边。缺省bool值默认无向
例如
6
8
0 1
0 2
0 5
2 3
2 4
2 1
3 5
3 4
代码实现:
Graph::Graph(const char *filename, bool directed = false) {
directed_ = directed;
int a, b;
// 默认能打开,如果想安全,使用if (!infile.is_open())作进一步处理
std::ifstream infile(filename, std::ios_base::in);
// 节点和边数量
infile >> a >> b;
vcount_ = a;
ecount_ = b;
vertices_.resize(vcount_);
// 读取边
for (int i = 0; i < ecount_; ++i) {
infile >> a >> b;
int v = a;
int w = b;
vertices_[v].insert(w);
if (!directed_) {
vertices_[w].insert(v);
}
}
infile.close();
}
3.3.2 添加和删除顶点
// 添加顶点
int Graph::AddVertex() {
std::set<int> temp;
vertices_.push_back(temp);
++vcount_;
return 0;
}
// 删除顶点
int Graph::RemoveVertex(const int &u) {
if (u > vertices_.size()) {
return -1;
}
// 遍历图,寻找与顶点的相关的边
// 无向图,有关的边一定在该顶点的邻接关系中
if (!directed_) {
int e = vertices_[u].size();
vertices_.erase(vertices_.begin() + u);
ecount_ -= e;
--vcount_;
return 0;
} else {
// 遍历图
for (int i = 0; i < vertices_.size(); ++i) {
RemoveEdge(i, u);
}
vertices_.erase(vertices_.begin() + u);
--vcount_;
return 0;
}
return -1;
}
3.3.3 添加和删除边
// 添加边
int Graph::AddEdge(const int &u, const int &v) {
// 不绑安全带,使用需谨慎
vertices_[u].insert(v);
if (!directed_) {
vertices_[v].insert(u);
}
++ecount_;
return 0;
}
// 删除边
int Graph::RemoveEdge(const int &u, const int &v) {
auto it_find = vertices_[u].find(v);
if (it_find != vertices_[u].end()) {
vertices_[u].erase(v);
--ecount_;
} else {
return -1;
}
if (directed_) { return 0; }
// 无向图删除反向边
it_find = vertices_[v].find(u);
if (it_find != vertices_[u].end()) {
vertices_[v].erase(u);
} else {
// 人和人之间的信任呢?
return -1;
}
return 0;
}
3.3.4 是否有邻接关系
// 检查两个顶点之间是否有邻接关系
bool Graph::IsAdjacent(const int &u, const int &v) {
if (vertices_[u].count(v) == 1) {
return true;
}
return false;
}
3.3.5 其它:打印图
这个用到了cout,又考虑到非功能性方法,不建议放在类中。
// 打印图
void PrintGraph(const Graph &graph) {
for (int i = 0; i < graph.vcount(); i++) {
std::cout << i << " -->";
for (auto it = graph.cbegin(i); it != graph.cend(i); ++it) {
std::cout << " " << *it;
}
std::cout << std::endl;
}
}
3.5 小结
图是相当灵活的,我想这也是为什么STL库不提供Graph的原因。我们可以发现,利用STL的基础设施,我们可以很快的搭建Graph。至于选择什么基础设施,没有标准答案。对于不同的问题会有不同的最佳答案。我们只是演示,不对特定问题进行进行建模,可以不管什么性能,也没打算泛化(不造库,谢谢),不过分考虑实现和图操作分离问题。嗯,就这样咯,还是赶紧进入更加激动人心的图算法吧。
后记
我水平有限,错误难免,还望各位加以指正。
参考资料
- Thomas H.Cormen, Charles E.Leiserson, Ronald L.Rivest,等. 算法导论(原书第3版).
- Robert Sedgewick, Kevin Wayne. 算法(原书第4版).
- 邓俊辉. 数据结构(C++语言版)(第3版).
- Kenneth H.Rosen. Discrete Mathematics and Its Applications(Seventh Edition).
- 维基百科相关词条
https://en.wikipedia.org/wiki/Graph_(discrete_mathematics) ↩︎
https://en.wikipedia.org/wiki/Directed_graph ↩︎
https://en.wikipedia.org/wiki/Directed_graph ↩︎
同构(isomorphism)这个词来自希腊语字根:“isos”表示相等;“morphe”表示形式。 ↩︎
注意这通常是可以做到的,这意味着我们只关注图的拓扑结构,不关心顶点id的意义。如果你非要在图中保存额外的信息,那么就应该使用树结构或者随机化的hash方案。 ↩︎