Flink的安装和使用(sql,datastream,cep)
一、安装
1、环境准备:
- 环境变量配置:
export JAVA_HOME=/usr/share/java/jdk1.8.0_131
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export HADOOP_HOME=/usr/hdp/3.1.0.0-78/hadoop/
export HADOOP_CONF=/usr/hdp/3.1.0.0-78/hadoop/conf
export PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
- ssh配置
- flink的安装包:flink-1.10.0-bin-scala_2.12.tgz
2、安装
1、standalone模式
- 集群规划:daas4(master),daas5(slave),daas6(slave)
- 解压:`tar -zxvf flink-1.10.0-bin-scala_2.12.tgz
- 修改配置文件:
vi $FLINK_HOME/conf/flink-conf.yaml
#设置jm的地址
jobmanager.rpc.address: daas4
#修改目录的输出位置
env.log.dir: /var/log/flink
vi $FLINK_HOME/conf/master
daas4
vi $FLINK_HOME/conf/slaves
daas5
daas6
- 启动及关闭
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
-
测试
(1)离线测试
准备测试数据:
因为是集群模式,所以任务可能在daas5或者daas6上执行,两台机器都要有/data/word.txt.或者上传到hdfs上。
运行命令:
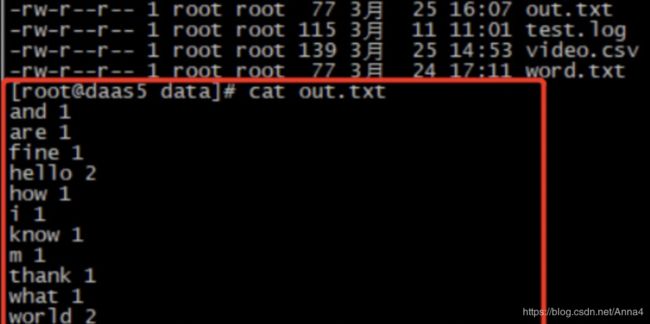
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/batch/WordCount.jar --input /data/word.txt --output /data/out.txt
(2)实时测试:
准备测试数据:daas6上 nc -l 9999产生数据
运行命令:
$FLINK_HOME/bin/flink run $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar --host daas6 --port 9999
结果查看:webUI访问:daas4:8081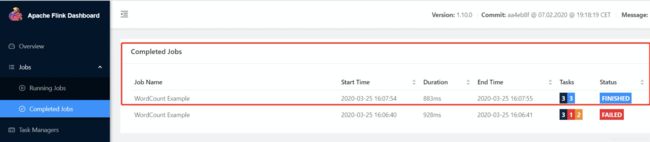
-
内部提交流程:
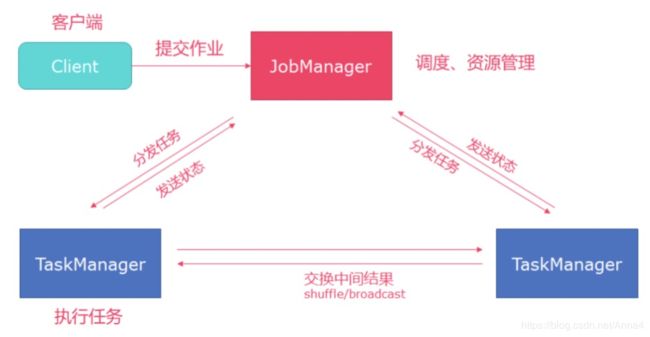
- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
-
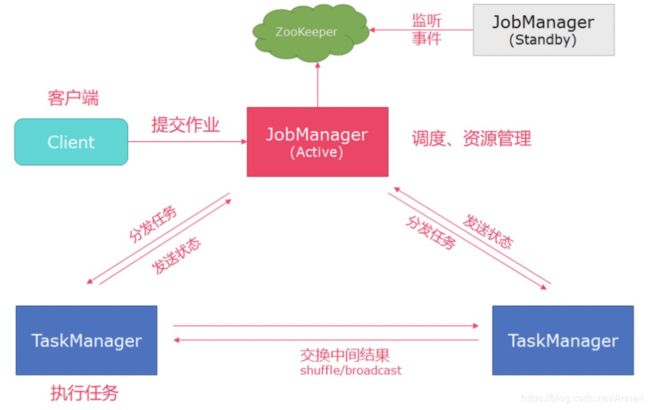
如果需要配置HA
修改配置文件:vi $FLINK_HOME/conf/flink-conf.yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: daas3:2181,daas4:2181,daas5:2181
high-availability.storageDir: hdfs://daas/flink/recovery
执行流程:
- 容错配置 checkpoint & savepoint
修改配置文件:vi $FLINK_HOME/conf/flink-conf.yaml
state.backend: rocksdb
#存储检查点的数据文件和元数据的默认目录
state.backend.fs.checkpointdir: hdfs://daas/flink/pointsdata/
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# relative path is better for change your cluster
state.checkpoints.dir: hdfs://daas/flink/checkpoints/
# Default target directory for savepoints, optional.
#
#state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.savepoints.dir: hdfs://daas/flink/savepoints/
#
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#开启增量checkpoint 全局有效
state.backend.incremental: true
#保存最近检查点的数量
state.checkpoints.num-retained: 3
2、yarn模式
准备工作:
需要将依赖hadoop的jar包及其他jar包放到flink/lib目录下
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
以下三个jar包可以重新编译上面的hadoop包加入依赖,也可以直接加到flink的lib下
jersey-client-1.9.jar
jersey-common-2.9.jar
jersey-core-1.9.jar
运行在yarn上有两种方式:session与per-job方式
2.1 session 方式
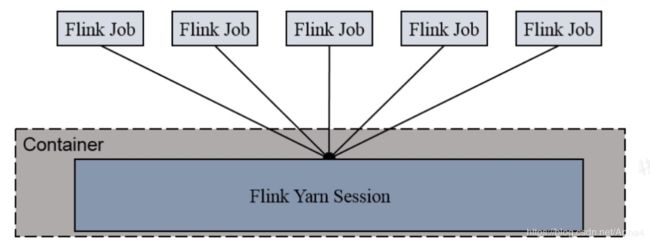
共享dispatcher和resourceManager,共享资源即taskManager,适合规模小,执行时间较短的job.
使用步骤:
1、开启yarn-session ./bin/yarn-session.sh -n 2 -tm 800 -s 1
参数说明:
yarn-session.sh脚本可以携带的参数:
Required
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
Optional
-D <arg> 动态属性
-d,--detached 会自己关闭cient客户端
-jm,--jobManagerMemory <arg> JobManager的内存 [in MB]
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-at,--applicationType Set a custom application type on YARN
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue <arg> 指定YARN队列
-s,--slots <arg> 每个TaskManager使用的slots数量
-tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace
开启后下面会显示jobmanager启动的位置,用于下面的任务提交:
2、准备数据:daas6: nc -l 9999
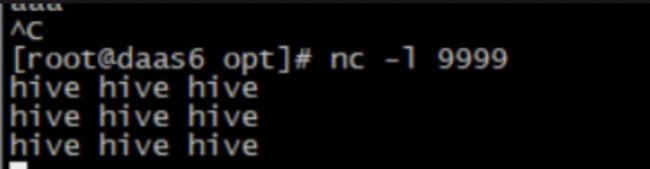
3、提交任务:
$FLINK_HOME/bin/flink run -m daas6:38037 $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar --host daas6 --port 9999
![]()
4、查看结果:
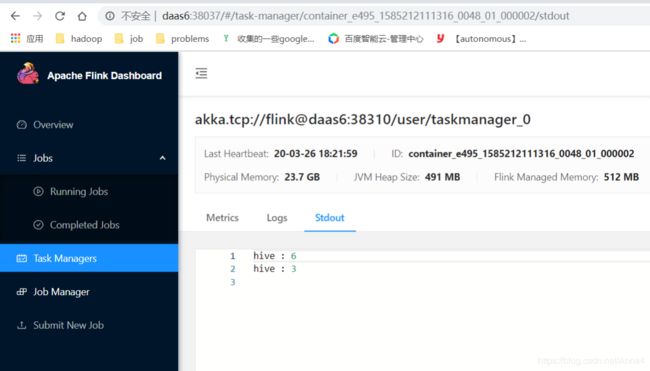
2.2 Per-job方式:
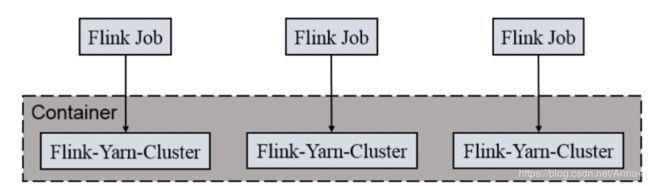
独享dispatcher和resourceManager,独享资源即taskManager,适合执行时间长的大job.
使用步骤:
1、 测试数据:socket发送消息:nc -l 9999
2、提交任务:/var/opt/flink/bin/flink run -m yarn-cluster -d /var/opt/flink/examples/streaming/SocketWindowWordCount.jar --host daas6 --port 9999
4、查看结果:
5、关闭任务:
echo “stop” | ./bin/yarn-session.sh -id
2.3 内部运行流程:
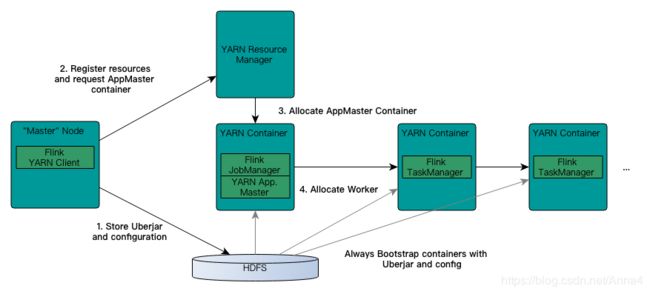
- 检查资源是否存在,上传jar包和配置文件到HDFS集群上
- 申请资源和请求AppMaster容器
- Yarn分配资源AppMaster容器,并启动JobManager
• JobManager和ApplicationMaster运行在同一个container上。
• 一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
• 它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
• 这个配置文件也被上传到HDFS上。
• 此外,AppMaster容器也提供了Flink的web服务接口。YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink - 申请worker资源,启动TaskManager
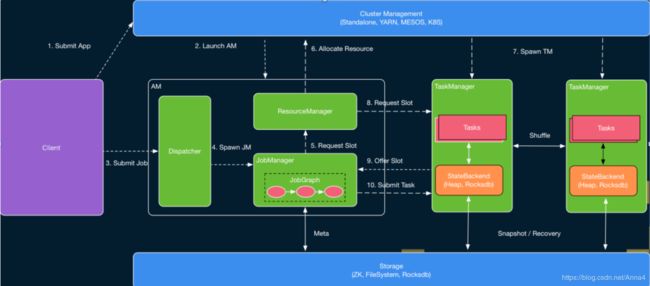
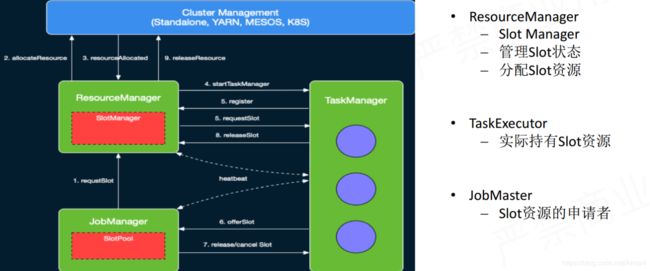
- 拓展:flink内部流程
二、Flink的应用(主要为flink sql)
1、sql-client方式:
- 准备数据:/data/video.csv
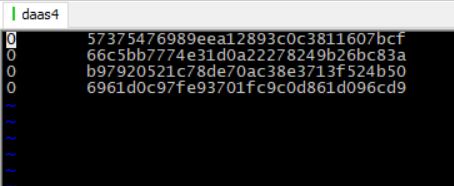
- 准备启动的环境配置文件:也可以不配置,将sql直接写在sql-client中
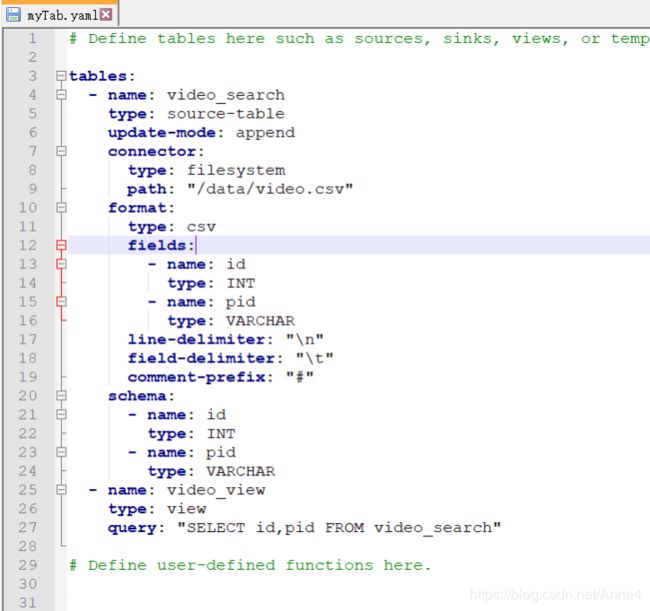
- 启动sql-client: ./bin/sql-client.sh embedded -e ./envConf/myTab.yaml
- 执行语句:select * from video_search;
- 查看结果:
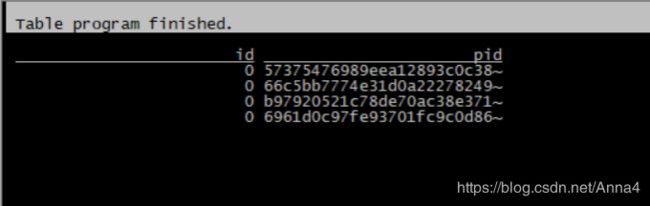
2、JAVA API方式
2.1 准备测试数据:生成数据,发送到kafka的topic
pom.xml依赖如下:
>
>
>org.apache.kafka >
>kafka-clients >
>0.11.0.1 >
>
>
code:
import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class OrderProducer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "daas3:6667,daas5:6667,daas6:6667");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// //设置自定义分区器
// props.put("partitioner.class", "com.hj.kafka.producer.CustomerParatitioner");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for(int i=0;i<1000;i++ ){
Person person = new Person(i+"","zhan"+i,18);
producer.send(new ProducerRecord<String, String>("blog",JSON.toJSONString(person)));
Thread.sleep(1000);
}
}
}
2.2 Flink使用的三种方式
项目的pom.xml
<?xml version="1.0" encoding="UTF-8"?>
://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
>4.0.0 >
>flink-test >
>
>1.10.0 >
>2.12 >
>
>
<!-- 1、根据目标编程语言,您需要将Java或Scala API添加到项目中,以便使用Table API和SQL定义管道 -->
org.apache.flink
flink-table-api-java-bridge_${scala.binary.version}
${flink.version}
<!--用于使用Java编程语言的纯表程序的Table&SQL API(处于开发初期,不建议使用!)-->
<!--2、在IDE中本地运行Table API和SQL程序,必须添加要使用的计划程序 在生产为了稳定性建议选择旧版本的-->
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
>
>org.apache.kafka >
>kafka_2.12 >
>2.0.0 >
>
<!--在内部,表生态系统的一部分在Scala中实现,所以需要添加scala的依赖-->
org.apache.flink
flink-streaming-scala_${scala.binary.version}
${flink.version}
<!--如果要实现与Kafka或一组用户定义函数进行交互的自定义格式,则需要添加以下依赖:用于通过自定义功能,格式等扩展表生态系统的通用模块-->
org.apache.flink
flink-table-common
${flink.version}
>
>org.apache.flink >
>flink-connector-kafka_${scala.binary.version} >
>${flink.version} >
<!--provided -->
>
>org.apache.flink >
>flink-json >
>${flink.version} >
<!--provided -->
<!--用于控制台输出日志进行调试,需要引入log4j.properties包-->
>
>
>
>
>org.apache.maven.plugins >
>maven-compiler-plugin >
>3.8.0 >
>
>1.8 >
>1.8 >
<!-- The semantics of this option are reversed, see MCOMPILER-209. -->
false
-Xpkginfo:always
>
>
>
>
>
2.2.1 DataStream
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class FlinKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "daas3:6667,daas5:6667,daas6:6667");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("blog", new SimpleStringSchema(), properties);
//从最早开始消费
consumer.setStartFromEarliest();
DataStream<String> stream = env.addSource(consumer);
stream.print();
//stream.map();
env.execute();
}
}
2.2.2 表的生成通过code
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Json;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.types.Row;
public class TestDemoWithCode {
public static void main(String[] args) {
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
Kafka kafka = new Kafka()
.version("universal")
.topic("blog")
.property("bootstrap.servers", "daas3:6667,daas5:6667,daas6:6667")
.property("zookeeper.connect", "daas3:2181,daas4:2181,daas5:2181")
.property("group.id", "testGroup")
.startFromEarliest();
tableEnv.connect(kafka)
.withFormat(
new Json().failOnMissingField(true).jsonSchema(
"{" +
" type: 'object'," +
" properties: {" +
" id: {" +
" type: 'string'" +
" }," +
" name: {" +
" type: 'string'" +
" }," +
" age: {" +
" type: 'string'" +
" }" +
" }" +
"}"
)
)
.withSchema(
new Schema()
.field("id", DataTypes.STRING())
.field("name", DataTypes.STRING())
.field("age", DataTypes.STRING())
)
.inAppendMode()
.registerTableSource("MyOrderTable");
String querySql = "select * from MyOrderTable";
Table table = tableEnv.sqlQuery(querySql);
DataStream<Row> dataStream = tableEnv.toAppendStream(table, Row.class);
table.printSchema();
dataStream.print();
try {
tableEnv.execute("myJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.2.2 表的生成通过DDL
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class TestDemoWithSql {
public static void main(String[] args) {
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
String sql = "CREATE TABLE MyOrderTable (\n" +
" id STRING,\n" +
" name STRING,\n" +
" `age` BIGINT\n" +
") WITH (\n" +
" -- declare the external system to connect to\n" +
" 'connector.type' = 'kafka',\n" +
" 'connector.version' = 'universal',\n" +
" 'connector.topic' = 'blog',\n" +
" 'connector.startup-mode' = 'earliest-offset',\n" +
" 'connector.properties.zookeeper.connect' = 'daas3:2181,daas4:2181,daas5:2181',\n" +
" 'connector.properties.bootstrap.servers' = 'daas3:6667,daas5:6667,daas6:6667',\n" +
"\n" +
" -- specify the update-mode for streaming tables\n" +
" 'update-mode' = 'append',\n" +
"\n" +
" -- declare a format for this system\n" +
" 'format.type' = 'json', -- required: specify the format type\n" +
" 'format.fail-on-missing-field' = 'true' -- optional: flag whether to fail if a field is missing or not, false by default\n" +
"\n" +
" \n" +
")\n";
tableEnv.sqlUpdate(sql);
String ssql = "select * from MyOrderTable";
Table table = tableEnv.sqlQuery(ssql);
DataStream<Row> dataStream = tableEnv.toAppendStream(table, Row.class);
table.printSchema();
dataStream.print();
try {
tableEnv.execute("myJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}
三、CEP(复杂事件处理)
引入依赖:
>
>org.apache.flink >
>flink-cep_${scala.binary.version} >
>${flink.version} >
<!-- >provided >-->
1、JAVA API实现:
/**
* 如果同一用户(userid相同,可以是不同IP)在2秒之内连续两次登录失败,就认为存在恶意登录的风险,输出相关的信息进行报警提示
*/
public class FlinkCEP {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<LoginEvent> loginEventStream = env.fromCollection(Arrays.asList(
new LoginEvent("1","192.168.0.1","fail", 1558430842L),
new LoginEvent("1","192.168.0.3","fail", 1558430845L),
new LoginEvent("1","192.168.0.2","fail", 1558430844L),
new LoginEvent("1","192.168.10,10","success", 1558430847L)
)).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<LoginEvent>() {
private final long maxOutOfOrderness = 5000;
private long currentMaxTimestamp;
@Override
public long extractTimestamp(LoginEvent loginEvent, long previousElementTimestamp) {
System.out.println("loginEvent is " + loginEvent);
long timestamp = loginEvent.getTimestamp()*1000;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
System.out.println("watermark:" + (currentMaxTimestamp - maxOutOfOrderness));
return timestamp;
}
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
});
Pattern<LoginEvent, LoginEvent> loginFailPattern = Pattern.<LoginEvent>begin("begin")
.where(new IterativeCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent, Context context) throws Exception {
return loginEvent.getType().equals("fail");
}
})
.next("next")
.where(new IterativeCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent, Context context) throws Exception {
return loginEvent.getType().equals("fail");
}
})
.within(Time.seconds(3));
PatternStream<LoginEvent> patternStream = CEP.pattern(
loginEventStream.keyBy(LoginEvent::getUserId),
loginFailPattern);
SingleOutputStreamOperator<LoginWarning> loginFailDataStream = patternStream.select((Map<String, List<LoginEvent>> pattern) -> {
List<LoginEvent> first = pattern.get("begin");
List<LoginEvent> second = pattern.get("next");
return new LoginWarning(second.get(0).getUserId(),second.get(0).getIp(), second.get(0).getType());
});
loginFailDataStream.print();
env.execute();
}
}
2、sql如何使用CEP
SELECT
store_id,
count(order_id)
FROM
(
SELECT
MR.store_id,
MR.order_id,
MR.store_out_time,
MR.distribute_take_time
FROM dwd_order
MATCH_RECOGNIZE(
PARTITION BY order_id
ORDER BY eventstamp
MEASURES
e1.store_out_time AS store_out_time,
e2.distribute_take_time AS distribute_take_time
ONE ROW PER MATCH WITH TIMEOUT ROWS --超时记录输出
AFTER MATCH SKIP TO NEXT ROW
PATTERN (e1+e2) WITHIN INTERVAL '6' HOUR --超时时长定义
DEFINE --定义模式中的事件
e1 as e1.store_out_time is not null and e1.distribute_take_time is null,
e2 as e2.store_out_time is not null and e2.distribute_take_time is not null
)MR
)t1
where distribute_take_time is null --后节点时间为空
group by store_id;