Hive
Hive
Hive的架构:
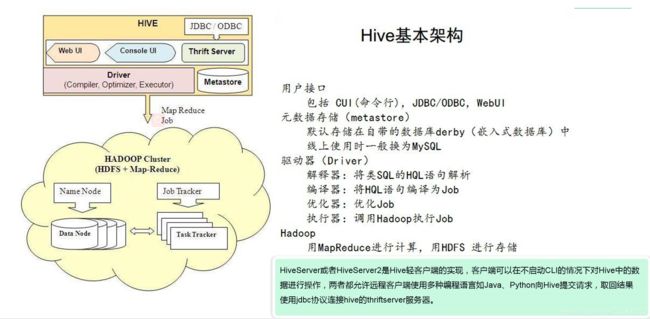
1、Hive的架构:
2、Hive的运行过程:
1、用户提交查询任务给Driver。
2、Antlr解析器将SQL转换为抽象语法树AST Tree。
3、遍历AST Tree,抽出基本的查询单元QueryBlock。
4、遍历QueryBlock,翻译为执行操作树OperatorTree。
5、逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator减少Shuffle。
6、遍历OperatorTree,翻译为MapReduce任务。
7、物理层优化器进行MapReduce人物变换,生成最终计划任务。
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
Hive的函数:
1、JOIN:
1、reduce join:将数据打上标签,reduce拿到key相同的数据,在根据标签进行相同key不同value的操作。
2、map段join:将小表复制多份放在map task内存中,大表中key在小表中存在,进行join操作。
3、semi join:将右表的key复制到一个新表,发到各个maptask进行过滤,在进行reduce。
2、排序:

3、炸裂函数:
1、只取炸裂字段:
select
explode(字段名)
from
表名
2、原表中的字段和炸裂字段:
selelct
表中字段,
列的别名
from
表名
lateral view explore(字段名) 炸裂开表的别名 as 列的别名
;
4、窗口函数:
RANK() 排名函数,有并列名次,名次不连续,总数不会变。如:1,1,3
DENSE_RANK() 排名函数,排序相同时会重复,总数会减少。如:1,1,2
ROW_NUMBER() 排名函数,会根据顺序计算,不会重复,适合于生成主键或者不并列排名。如:1,2,3
1) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
2) CURRENT ROW:当前行
3) n PRECEDING:往前n行数据
4) n FOLLOWING:往后n行数据
selec
roe over()
5、UDF、UDTF
在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题,及自定义步骤?
1)自定义过。
2)用UDF函数解析公共字段;用UDTF函数解析事件字段。
自定义UDF:继承UDF,重写evaluate方法
自定义UDTF:继承自org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,重写3个方法:
//该方法中, 将指定输入输出参数:输入参数的ObjectInspector与输出参数的StructObjectInspector abstract StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException;
//我们将处理一条输入记录,输出若干条结果记录 abstract void process(Object[] record) throws HiveException;
//当没有记录处理的时候该方法会被调用,用来清理代码或者产生额外的输出 abstract void close() throws HiveException;
为什么要自定义UDF/UDTF → 因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试.
用户定义表函数(UDTF),该函数的实现是通过继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF这个抽象通用类,UDTF相对UDF更为 复杂,但是通过它,读入一个数据域,输出多行多列,
而UDF只能输出单行单列。(举个例子,hive内置函数explode的作用)
Hive的优化:
1、行过滤:
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。正确的写法是写在 ON后面,或者直接写成子查询。
2、采用分区技术 :
分区意义:
避免全表扫描,从而提高查询效率。默认使用全表扫描。
使用什么分区?
日期、地域、能将数据分散开来?
分区技术:
[PARTITIONED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...)]
1、hive的分区名区分大小写
2、hive的分区字段是一个伪字段,但是可以用来进行操作
3、一张表可以有一个或者多个分区,并且分区下面也可以有一个或者多个分区。
4、分区字段使用表外字段
本质:
在表的目录或者是分区的目录下再创建目录,分区的目录名为指定字段=值(比如:dt=2019-09-09)
3、采用分桶技术
为了更加细粒度划分数据。
语法:
[CLUSTERED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...)
[SORTED BY (COLUMNNAME [ASC|DESC])...] INTO NUM_BUCKETS BUCKETS]
意义:
抽样查询
join提高查询效率
模式:
分区下创建分桶表
表下创建分桶表
默认,分桶技术实现是按照分桶字段进行hash值模于总桶数得到的值即是分桶数。
案例:create table if not exists buc1(
id int,
name string,
age int
)
clustered by (id) into 4 buckets
row format delimited fields terminated by ','
;
4、合理设置Map数:
(1)通常情况下,作业会通过input的目录产生一个或者多个map任务。 主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
(2)是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个 map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
5、小文件的合并:
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。
6、Hive如何优化常用参数
数仓与数据库的区别:
1、数据库:主要是用户事务处理
1、相对复杂的表结构,存储结构相对紧致,冗余数据少。
2、读和写都优化。
3、相对简单的query。
4、尽量避免冗余,一般采用符合范式的规则来设计。
2、数据仓库:主要用于数据分析。面向主题
1、相对简单的表结构,多冗余数据。
2、先对复杂的query。
Hive中数据倾斜的处理方法:
1、任务发现
主要表现:任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce子任务未完成,因为其处理的数据量和其他的 reduce 差异过大。单一 reduce 处理的记录数和平均记录数相差太大,通常达到好几倍之多,最长时间远大于平均时长。
2、场景案例一:聚合类的shuffle操作
案例场景:某一特殊key值大量出现,语句中仅出现groupby,没有相应的聚合函数一起(聚合函数可以在map阶段提前进行聚合,可以降低数据倾斜风险),会造成对应key的reduce出现数据倾斜解决策略是对key值进行加盐
处理:核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行sum,count等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜
方案缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。
场景案例二:join数据倾斜
方案一:抽样求出引起数据倾斜的key值,进行过滤处理
情景:某张表中数据分布不均,个别key值出现次数占比很大,引起join数据倾斜,例如数据空值或者爬虫IP
处理思路:首先对数据进行抽样,选出key占比较大列表,采取过滤处理,去掉无效值或者加盐等处理,然后先进行局部处理,在整体处理。
优点:可以快速解决数据倾斜问题
缺点:应用场景受限,适用于几个key值偏多的情况
方案二:采样倾斜key并分拆join操作
方案适用场景:两个Hive表进行join的时候,如果数据量都比较大,那么此时可以看一下两个Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个Hive表中的少数几个key的数据量过大,而另一个Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
1、对包含少数几个数据量过大的key的那个表,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
2、然后将这几个key对应的数据从原来的表中拆分出来,形成一个单独的表,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个表。
3、接着将需要join的另一个表,也过滤出来那几个倾斜key对应的数据并形成一个单独的表,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个表。
4、再将附加了随机前缀的独立表与另一个膨胀n倍的独立表进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
5、而另外两个普通的表就照常join即可。
6、最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
方案优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
场景三:增加并行度
场景:两个大表,数据分布均匀,为了提高效率。
即可,就是最终的join结果。
方案优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
### 场景三:增加并行度
场景:两个大表,数据分布均匀,为了提高效率。