(转)原子时代来临-Intel革命性Atom透析
前言
前言
随着当前制造工艺的瓶颈越收越窄,高性能产品的竞赛正变得越来越艰难:面对高端用户永无止尽的性能追求,高端产品的升级换代反而变得越来越迟缓,短 期内技术革新与用户需求间的矛盾还将继续恶化。面对这种局面,开发商们把更多的精力投向对性能需求不高的市场领域,因为在这个领域,可供开发的空间还很巨 大。在过去,由于基层硬件系统的性能不足,五年前我们不可能看到像AUSU EeePC这样的产品,虽然今天发送EMAIL,浏览网页、查看文档等日常任务对硬件性能的需求同样与时俱进,但CPU性能的增长速度仍远远超过这些任务 处理的需求增长。这种硬件性能大幅超过日常应用软件需求的现状让人们萌发了制造性能“够用”,同时便携性与节能性等方面表现优秀的硬件。目前我们可以看到 部分公司如华硕已经意识到这种潮流趋势,开始涉足这方面产品的研发。而毫无疑问像Intel这样的大鳄自然不会放任这块“肥肉”落入他人碗里~~在今年的 CES大会上,有厂商展示了被称之为“移动互联网设备”( Mobile Internet Devices,简称MID)的产品。这些都是小尺寸产品,可以用来浏览网页,查收电子邮件,使用IM软件,播放音乐、浏览图片等。这些MIDs产品甚至 还可以运行Vista 或者 Linux操作系统,出于成本控制方面的原因,大部分厂家选择的是Linux系统。这类产品在体积上明显要大于iPhone手机,同时在理论上使得得也更 全面一些。不过我们今天要关注的不是MID本身,而是为它注入动力的“心”——Intel全新的超低功耗处理器品牌“Atom(原子)”。


小时候我最喜欢的电影之一就是《回到未来》系列,我喜欢《回到未来》的前两集,特别是那个时候爱上了游戏、汽车跟其他各种科技产品,所以对于第二部 更是情有独钟。在《回到未来2》中,影片主角Marty McFly超越时空前往未来去阻止他儿子被捕入狱以及家庭被毁等一系列厄运。影片中Marty McFly在未来买了一本sports almanac(运动赛事年鉴),企图回到过去后能够“未卜先知”,从中牟利。虽然最后事情的结果跟Marty McFly所期盼的截然不同,但今天Intel推出“原子处理器”的意图可谓跟Marty McFly“不谋而合”。设想下假如Intel能够回到过去,然后运用他们工程师在过去15年里所掌握的技术,用45nm制程重新将奔腾一代做成一颗超小 超酷的CPU!
在过去20年里我们一直把精力放在如何制造出最快最强的CPU上面,而如今,我们已经有能力去制造不仅速度够快,而且其他方面(功耗、体积等)同样出色的CPU。 ——Intel语
1993年,Intel费尽九牛二虎之力将三千一百万个晶体管封装进当时刚刚面世的奔腾处理器300mm^2大小的管芯里面。而今天,Intel已 经出厂数百万个酷睿2处理器,其晶体管数量达到惊人的4.1亿个(超过奔腾1的130倍),而管芯的面积却只有当年奔腾1的1/3。Intel并没有因此 而止步,预计下半年面市的Nehalem将集成更多的晶体管,性能也更上一层楼。在2010年之前,我们就可以看到晶体管数量超过10亿的台式机CPU。 不过令人感兴趣的并不只是Intel在高端CPU上所作的的努力,其在设计相对简单的低端CPU所取得的成果甚至更让人好奇。
Intel无法在294mm^2大小的die上制造出用于低成本设备的奔腾1,但如今情况已经截然不同了。当年“臃肿”的0.80μm制造工艺早已 入土,如今我们正全面过渡到0.45nm制程。假如不改动架构,使用45nm制程intel可以在不到3mm^2大的die上“还原”奔腾1处理器。不过 实事比这样简单的还原还要有趣得多,Intel的工程师们在奔腾1面市后的15年里已经掌握了许多新技术跟新经验,设想下这些新技术能够对相对简单的 X86架构动用什么样的改造手术~~~

用X86抢占新市场
目标:主流市场
在台式跟笔记本系统里我们需要尽可能快的CPU,但是我们今天所关注的领域要比纯粹的计算机领域更加普遍广泛得多。随着台式机跟笔记本系统速度的不 断攀升,我们渐渐被这种高速运行的速度所宠坏,渐渐地也渴望家中的各种日常电器设备的反应速度能够跟上计算机产品的脚步。智能手机就是最典型的例子,目前 智能手机的功能越来越多,能够处理的任务亦日趋多样化,但是其界面的运行速度却让人丝毫没有PC上的“速度快感”;苹果公司想用iPhone来改变这一状 况,但iPhone需要改进的地方还有许多。在传统家电上这一问题也普遍存在,即便是价格接近普通PC的蓝光播放器,其系统启动速度跟界面菜单的响应时间 同样让人难以忍受!难道我们能够让半条命2的帧速轻松达到200,却无法提高电视菜单对遥控操作的响应速度?

导致这种局面的问题之一就是大部分家电产业过于商品化,随着LCD价格的一路下滑,我们家中到处都是LCD显示屏。但是价值几百美元的高性能CPU就很难在电视机、蓝光播放器或是GPS装置之类更加简单的设备上找到“容身之处”。
无论是电视选择菜单、GPS上的软件堆栈还是蓝光播放器所需要处理的非解码运算,即使是当前台式机上最低端的CPU也足以应付这些任务,所以目前我们面临的问题不是“能否”让这些设备跑得更快,而是“想让这些设备跑得足够快至少需要什么样的CPU?”。
这样一颗CPU需要具备的条件包括低功耗、低售价同时又不能以牺牲性能为代价。你或许会争辩对于上述程序应用来说,一颗奔腾3等级的CPU就足以满足,甚至最初的奔腾M也没问题,这正是摩尔定律的体现。
在若刚年前,奔腾3、奔腾4跟奔腾M处理器的制造成本跟今天的酷睿2系列差不多,但是跟酷睿2相比他们的晶体管数量根本不值一提!更有甚者,两年内 晶体管数量超过10亿的台式CPU的造价甚至要比当年的奔腾一代还要低!换个角度看——今天我们能否造出性能达到奔腾M级别,而造价又低廉到日用家电产品 所能够接受,同时低功耗跟无需散热器辅助散热的CPU产品呢?

“x86一统江湖”
当年AMD宣布有意思将x86总线扩展到64bit的时候,我曾问过AMD的前CTO Fred Weber:将x86扩展到64bit是否有意义?Intel转移到Itanium和全新的ISA的举措是否正确?他那时候的回答听起来有些道理,但我当 时并不能很好地理解他的整个意思。

Fred认为维持x86架构兼容性的代价小到可以忽略不计,当时x86编译器只占去整个die 10%左右,而这个比例以后还可以进一步缩减。目前AMD的高端CPU晶体管数量已经达到当时K8的八倍左右,向后兼容部分所消耗的晶体管数量也进一步缩 减至很小的数目,而向后兼容带来了莫大的好处。
当前PC领域所有的程序代码都是面向x86架构编写的,其结果就是在家用电器平台上无法直接运行,而越来越多的应用程序需要在家电上运行,比如网页 浏览器、email客户端跟网络媒体播放器。由于家电产品不是采用x86平台,因此制造商要想在家电上运行这些程序就必须将开源软件移植到家电平台上或自 己开发类似的家电版程序。
但问题是基本上目前这些应用程序最成熟最优秀的版本都已经扎根于PC平台,而我们最不想看到的就是像SONY这样的公司去搅浏览器市场这趟浑水,我 宁愿家里带网络功能的电视机跟厨房里的触摸屏采用的是Firefox或IE,也不愿意被逼着去使用SONY的浏览器(如果有的话)。当然这些软件都可以被 移植到任何架构的平台上,只是软件开发商不喜欢多平台技术支持,因为这需要花费大量的金钱去为各个平台的版本除bug跟维护。
当年Fred的回答就是想让我了解他心中“x86一统江湖”的美好愿望,在他看来指令集并不重要,重要的是让几乎所有设备都能够运行同一种代码。我 常常说Apple肯定打心里憎恨开发iPhone,因为iPhone是她们所有类电脑产品中唯一无法运行x86代码的产品,也就是说Apple不得不专门 为iPhone单独设立一个软件开发维护部门。
Fred的想法不错,随着计算机以非常规方式渐渐渗入我们的家居生活,让所有设备能够统一运行同一种代码正变得越来越重要。然而讽刺的是,虽然Fred是首先像我提出这一观点的人,但真正去付诸行动的却是其对手Intel!
“原子”的孕育与诞生
成功的序章
事情开始于2004年,美国德克萨斯州的奥斯丁,我说的是Intel而不是AMD。那一年,Intel奥斯丁设计中心正在全力打造奔腾4家族的另一名成员——Tejas。
Tejas当时是计划在Prescott之后发布,以延续NetBurst架构血脉。但历史证明高耗低能的NetBurst最终必将走下历史舞台, 而Tejas也因此而夭折。整个开发计划被终止之后Intel的目光全面转向奔腾M架构,在对其进行一番手术之后推向台式机领域,并最终获得成功。

Tejas夭折之后,其开发小组肯定是一肚子不满,不过这个由Intel天才工程师们组成的团队迅速化悲愤为力量,开始全力打造他们的下一个项目。
说到这里我要特别指出的是在Intel公司里,类似的奋斗史比比皆是,比如迅驰一代也是在类似情况下诞生的。Banias是迅驰的第一代产品,后来 被命名为奔腾M。Banias的开发小组在打造Banias之前是负责Timna的开发工作,跟Tejas一样Timna也在开发后期胎死腹中,开发项目 被取消这个打击另这个以色列设计团队消沉了大概一个月,好在他们很快就接到了Banias的研发任务。为了向那些让Timna胎死腹中的人证明自己的设 计,他们决心将Banias打造成最强的架构,而实事证明他们成功了,Banias成为了奔腾M,并成就了今天备受青睐的酷睿系列CPU。
回到我们前面所说的奥斯丁团队,在Tejas被扼杀之后,他们跟以色列团队一样需要证明自己的实力,而就在当时他们接到了新项目的开发任务。
新项目是开发一款低能耗,可用于多核心CPU设计的IA架构核心。由于新核心必须能够被用于多核产品,因此低能耗是首要条件(你不能在多核产品中集成十来颗好能达到100瓦的核心)。
我曾戏问奥斯丁小组的设计成员,上头把这样一个项目交到他们手上是不是有点戏弄的味道——从原本设计功耗上百瓦的Tejas突然转到仅仅几个W的产 品。很明显在设计Tejas期间,奥斯丁团队中的一个小分组就已经在设计低功耗、架构简洁的CPU方面做过一些摸索研究。也就有了这一年左右的摸索铺路, 才使得整个从高耗高能的项目转至低耗简约项目的过度比外人想象中要顺畅许多。
这次参与开发这一项目的许多工程师实际上都是Intel从其他微处理器设计公司招安而来的。新核心的主设计师Belli Kuttanna,之前曾在SUN负责开发过SPARC处理器,后来又在摩托罗拉负责PowerPC的核心设计。其他成员甚至还包括以前AMD的员工。
2004年早期的摸索工作主要是为了找出开发低功耗CPU的必要条件,当时他们给这颗“小”核心取了个代号叫Bonnell。Bonnell是奥斯丁境内最高的山峰,海拔750尺,这座娇小而挺拔的山峰正符合这颗“小芯“的形象。

研究的第一步是看下Bonnell能否用Intel手上的现成架构改造而成,研究小组先后尝试用奔腾M跟当时尚未发布的酷睿2架构,但很快就发现这 两种架构性能过剩以及能耗过大,并不适用于Bonnell。加上Intel发布了迅驰系列,因此急需一颗全新架构的CPU来占领新的市场。
奥斯丁开发小组最终决定从最简单的微处理器架构下手,即单指令发射、顺序执行的核心架构重新开始他们的设计,设计师们不断尝试直至能耗跟性能都达到要求。需要指出的是,在那个时候Intel自己也不清楚这颗新产品将被用于什么地方。
在2004年底,Paul Otellini才向奥斯丁团队说明Bonnell必须能被用于独立CPU,即不是之前所说的多核心CPU中的一颗核心而已。这颗新芯将被装配在 UMPCs(超级便携式PC)跟一种鲜有耳闻的产品——MID(移动上网设备,我们开篇介绍过)上。至于其用于多核心设计的部分则仍在开发中,个人估计我 们最快可以在Larrabee上看到改产品。
Bonnell只是一颗内核,但当它装上二级缓存跟外部总线介面之后就成为一颗内部命名为Silverthorne(银座)的CPU。就在最近Intel给了Silverthorne一个更为贴切的名字——Atom processor(原子处理器)。
惊鸿一瞥

采用Intel最先进的45nm制程,管芯面积只有不足25平方毫米,封装后的芯片大小也只有13mm×14mm,Atom是Intel至今为止发布的最 为小巧玲珑的x86处理器。跟以往Intel同类产品不同的是,Atom是100%完全兼容x86的CPU。(确切地说只继承了Merom ISA,因为体积跟功耗的问题而拿掉了对Penryn SSE4指令集的支持)。

核心架构透视
Intel原子核:令Intel脱胎换骨的设计
长期以来,Intel对于功耗/性能比遵循这样一个定律:一项提升CPU性能1%的设计,其带来的功耗增长不能超过2%,否则就必须放弃。但不幸的是,这样一个定律最终将Intel带进了NetBurst架构的死胡同,高耗低能的奔腾4和其衍生家族就因此而诞生。
到了现在的“原子核”,Intel重新修改了定律,新的定律规定每提升CPU性能1%,其功耗提升不能超过1%。这个规定对比“笨死”时代的定律称 得上是一次革命性的改革,这个新定律也将被用于Intel新架构(比如Nehalem)的设计指导,而Atom则是首个使用的产品。
虽然Atom一开始是按照单指令发射跟顺序执行的简单架构设计,但很快奥斯丁团队就将其升级为双指令并发,可惜仍然保持顺序执行部分。

现在的x86处理器都支持指令的乱序执行,这个机制就好比你需要系鞋带跟关掉电视,这时你可以选择先系好鞋带再去关掉电视,因为这么做会比较顺手。 CPU的乱序执行也是同个道理,CPU可以先处理掉手头可用的指令而无需按顺序等待尚未送往缓存里的数据,从而节省时间提高效率。但乱序执行的一大弊端就 是指令的重新排序电路需要占用额外的管芯面积以及增加能耗。当然乱序执行可以有效提升性能但我们要知道这次Intel的目的可不是性能第一,只需要“够用 ”就好,因此Atom只需顺序执行即可,Atom是Intel自奔腾1之后的又一款顺序执行架构CPU。
顺序执行架构虽然造成性能下降但却节省了大量的能耗跟复杂的电路设计,而如果用乱序执行的话,性能是上去了,但是相应的能耗跟晶体管负担是45nm 制程下的Atom所无法承受的。要知道Intel也是在奔腾pro之后才让乱序执行成为了可能,或许以后更小的制造工艺能让Atom集成乱序执行引擎,但 我认为未来5年内是不大可能的。
双指令并发与顺序执行
奥斯丁小组先是采纳了单指令发送+顺序执行的核心设计,后来又将其升级为超标量双指令并发,也就是说同时可以发送两条指令至流水线。相比之下,目前大部分台式x86 CPU可以同时发送3~4条指令。
为了保证Atom的双发指令发送器充盈,Intel为其配备了两个解码器。这些解码器从一级缓存中拾取运算指令,通过解读指令包含的1跟0排序来翻译指令给CPU的命令。虽然每个解码器的能力都是一样的,但是每条指令均有两条编译路径可选:一快一慢。
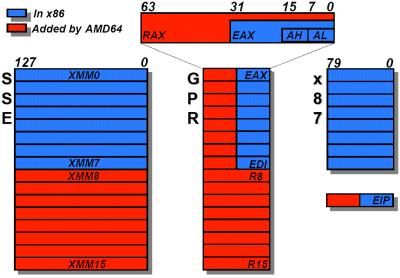
早期的x86 ISA(指令集架构)在对不同长度的指令支持方面陷入困境。小熊在线www.beareyes.com.cn
比方说我事先告诉你每十秒会给你一个橘子要比每十秒给你1~3个橘子要简单,前种情况就好比固定长度指令集,而后者就像是不定长度指令集,很不幸x86 ISA经常需要面对后者。
Atom的慢速解码通道并不具备任何猜测解码能力,每条指令都需要被手动排序,也就是说指令的每个bit都需要耗时去仔细查看,不过这样做能够保证解码过程的正确性。每一条被检测过的指令还会被打上标签,这样下次需要编译的时候就可以直接被送往较快的快速通道里。
快速解码通道明显带有猜测解码功能,再加上前面缓慢通道的“标签”功能协助,快速通道每个时钟可以发送两条指令,而慢速通道每三个时钟才能发送一条。
Intel从Banias(奔腾M)身上看到猜测运算机制所带来的额外能耗不是电池供电的设备所能够承受的,因此权衡利弊,Atom将对猜测运算方面做诸多妥协。
半乱序执行、微操作融合与超线程
指令也疯狂:安全指令识别
顺序执行架构最怕遇到的情况就是执行一条高延迟的指令时所需要的数据迟迟未被送到缓存中来。由于顺序执行CPU必须按顺序执行指令,所以一旦当前需 要被执行的指令所需要的数据无法在内存中获取到的时候,执行单元就必须一直处于空闲等待的状态中,有时需要耗费上百个时钟才能从内存中获取到数据,这不仅 大大降低性能,更糟的是整个空闲等待的过程都需要消耗电力,这种结果完全违背了我们设计低能耗CPU的初衷。
乱序执行处理器就可以通过简单的指令执行排序机制来解决这个问题。排序器只需挑出下一个已经准备好被执行的指令,然后对于那些可单独执行的指令则先 放一边等待从主内存中获取到数据之后再进行。我们前面已经证实完全的乱序执行架构的能耗超过Atom的极限,而完全依赖于顺序执行的结果同样不可取。最后 奥斯丁团队找到了一个明智的折中方案。
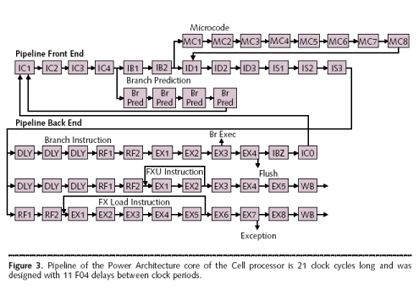
Austin小组采用的折中方案是一种叫做“安全指令识别(Safe Instruction Recognition,简称SIR)”的算法,该算法的工作机制如下:当Atom需要执行一条高延迟的浮点运算,而后面有跟着一条短延迟整数操作时,顺 序执行机制需要等浮点操作完成之后才能去执行后面的整数操作;但是采用SIR就可以先查看两条指令所需的数据是否有关联(比如前面是C=A+B,后面是 D=C+F),如果没有关联SIR就允许将后面的整数操作提前执行,从而节省时间提高效率。
SIR只在这种特殊情况下有效,它给Atom的顺序执行架构带来几分乱序执行的能力,所以严格来看Atom可以被称为“半乱序执行”架构。预计未来Atom在指令执行方面也将愈来愈灵活。
CISC归来:宏操作执行
奔腾Pro是Intel首款RISC核心,它的诞生结束了上世纪九十年代那场RISC vs CISC之争。对于程序员来说,奔腾Pro仍然是一颗x86 CISC CPU,但它在接收到x86指令之后就可以将其编译成多个小的微操作(micro-ops),以供更快更高效的RISC核心运行。
奔腾Pro保持了向后兼容过去Intel x86 CPU的能力,这样不单能够靠高性能的RISC核心提升性能,而且一些CISC架构的优势也能得以保存。事实证明部分x86指令不宜被打散成多个小的微操 作,因为个别操作间会有冲突。因此从奔腾M开始,Intel加某些特定的微操作融合在一起,以便让流水线更好地处理,从而起到节能高效的目的。Intel 称这种特性为“微操作融合(micro-op fusion)”。这种将两个微操作合二为一送往流水线的做法可以有效提高CPU的“带宽”,提高指令的吞吐量。不过其内核仍然是一颗高效的RISC核 心,只是拥有更多特定情况下的加速特性。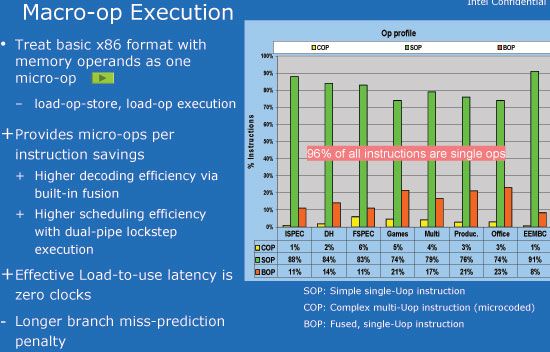
Atom则更进一步,内核在处理x86指令时无需将其打散为多个微操作,这是由于Atom不能乱序执行,缺乏优化排序的大量微操作反而会降低性能。 再者保持指令的完整性可以减少吞吐量,这样就好比增加了Atom的“带宽”。对于load-op-store 和 load-op-execution这类格式的指令,Atom的解码器都将其视为一个单一的微操作。换句话说,现在一条读取、运算以及储存计算结果的指令 将被视为一个单一的微操作,而不用被分割成3部分。这样做的好处就是被送往流水线处理的微操作只有一个而不是三个,从另一个角度看就是节省了带宽。所以 Atom虽然只是一个双指令并发架构,但是在某些情况下的指令吞吐量却不比某些台式CPU差。
过于Intel在将x86指令分割为更小、RISC类操作上大费周章,以求能够设计出性能更高的核心来应付大量被分割出来的微操作。讽刺的是在如今越来越注重性能/功耗比的今天,Intel必须回到原地反过来去保护x86指令的完整性。
超线程回归
虽然Atom支持双指令并发,但是由于同一线程内的两条指令所占用的数据相互独立,因此要同时执行两条指令绝非易事。为了解决这个难题,Intel 为Atom核心引入SMT(Simultaneous Multi-Threading,并发多线程技术),让核心同时具备双线程的执行度。当年P4上的超线程技术(Hyper-Threading)实际上就 是SMT中的一种,所以此举可以看成是超线程的回归。还记得我们前面提到的那条性能/功耗比黄金定律吗?Intel让Atom支持SMT就是遵循该定律的 最好例证。SMT为Atom带来30~50%的性能提升,但功耗只增加了20%!
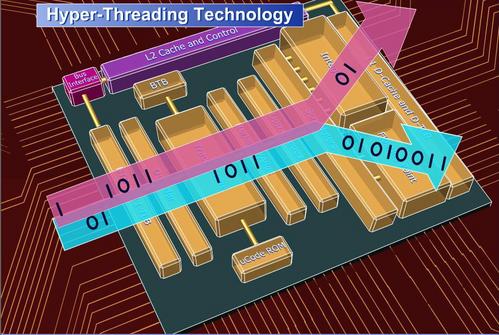
Atom具备32路的指令调度排列,在开启SMT之后,每线程又具备16路排列。排序器无需每个时钟都在各线程间做跳转,而是根据需要智能完成,唯 一的限制就是每时钟只能分配两个操作。所以如果当前线程的指令需要等待数据被送到才能继续执行,下一个时钟排序器就可以从另一个线程里挑选一个操作工核心 处理,这样就不会形成空等状态,顺序执行架构的缺陷让SMT成为保证Atom流水线随时保持充盈状态的保障。
执行单元与低功耗下的长流水线
执行单元
Atom并不是一款超宽处理器,顺序执行的前端跟缺乏内置内存控制器决定了其有限的指令吞吐能力,再加上数据间的相互关联性致使大量的执行单元只能是闲着空等,因此Atom的设计师们在执行单元的设计上只求达标就好。
Atom没有专用的整数乘法器或除法器,这些运算都由SIMD浮点单元来完成。Atom核心装配有两个SSE单元,其排序器的两个口可以在一个时钟内各发送一个浮点或整数SIMD操作。除了支持全精度整数SIMD和单精度FP ADD外,所有单元均为64bit宽。
用长流水线捍卫能耗?
Atom具备16级流水线,其分支预测失误的惩罚为13级。注重低功耗的Atom,流水线居然比酷睿2的14级还要长,这的确让人吃惊。
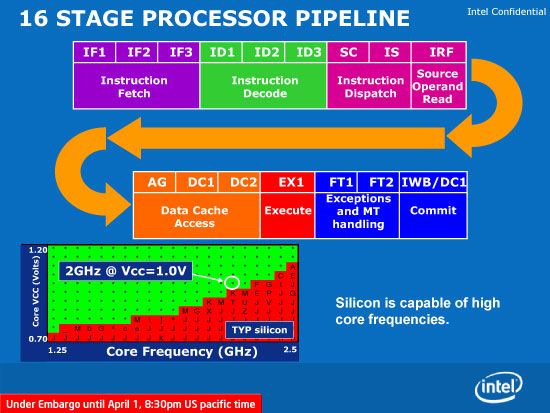
更长的流水线通常意味著更高的功耗,特别是有臭名昭著的功耗王“笨死”做为前车之鉴。但这次Intel给了我们下面三个采用长流水线的理由:
- 缓存
- 解码器
- SMT
对于奥斯丁小组来说,只要能够降低功耗,即使是用高延迟去换取功耗他们也同样乐意。为了尽量降低能耗,Atom只在缓存控制器对cache命中率有 把握的时候才去访问缓存,但这样一来每次访问就会产生长时间的延迟;为了让时钟频率足够高,就必须加深缓存访问的流水线,另外Atom采用物理地址标记代 替虚拟地址标记,因为后者的能耗太高。
再者,Atom在解码流水线同样用延迟换取低功耗,还记得我们前面介绍的解码器一慢一快两个通道吗?较慢的通道延迟高但能保证指令被正确编译,增加 的延迟迫使Atom的在解码时需要三级流水线而不是两级。最后,SMT所采用的一些算法也使流水线长度增加了一两级,所有这些加起来就使得原本设计简单的 核心却具备如此深的流水线,当然这样的长流水线设计完全是为了降低功耗以及保证核心能够跑在足够高的频率上(Atom只是一个双指令并发的简单核心,它需 要高频率来保证足够的性能),根本不是NetBurst的失败设计所能够相提并论的。
不协调的缓存与Sea-of-FUBs设计
不协调的一级缓存
由于顺序执行架构的性能对内存的高延迟非常敏感,因此Atom配备有大容量的一级缓存。有趣的是,Atom的一级缓存采用非对称的搭配方式,其指令 缓存为32KB,而数据缓存只有24KB。之所以采用这种独特的非对称搭配是从性能优化、管芯面积和成本等方面来考虑的。Atom的二级缓存则跟Core 架构相似,采用8路512KB设计。
Atom(或者说Silverthorne)采用Intel的45nm high-K金属棚极工艺制造,但有一点不同的是:Silverthrone的SRAM cell大小为0.382 um^2(平方微米),晶体管数量为8个;而Core 2为0.346 um^2,晶体管数量只有6个。较大面积的SRAM cell耗电量跟所需运行电压都较低。
Atom还配备有两个硬件级的预取器,一个用于将L2中预取数据到L1,另一个则是从内存预取数据到L2。我们前面已经反复强调过,如果当前操作所 需的数据不在缓存中,就会导致整个流水线停工,所以硬件预取单元对于顺序执行的架构极为重要。当然要想“治本”的话还需要将内存控制器集成到核心 内,Intel有望在第二代的Atom(代号Moorestown)内核集成内存控制器。
Sea-of-FUBs设计

将一个核心分割成9个块区然后分别由不同的设计小组负责是Intel设计CPU的惯用手法,比如一个小组负责L2设计、一个小组负责IO介面等等。不过这次负责设计Atom
的奥斯丁团队实际上是一个规模很小的设计小组,因此设计流程有所不同。他们采用一种叫做Sea-of-FUBs的核心构造法,这种方法比上面提到的“分块 ”更加细分,所谓FUB就是功能单元块(Functional Unit Block),像加法器、解码器、缓存都属于FUB,各FUB的设计可以同时进行,提高了研发效率。再者,Sea-of-FUBs随时提醒设计师们低能耗 是首要任务,其他特性只需“够用就好”,核心面积的死预算迫使设计师不能随心所欲,如果想要加大某个FUB的规模,就必须有另外一个FUB做牺牲缩小体 积;能耗上也需要遵循这一原则。
Atom比Intel之前所有的移动处理器更加模块化,实话说我感觉其组成更像是GPU而不是CPU。因为整个芯片一成使用了custom logic,其余90%都是使用Intel标准电路,像是二级缓存、PLLs、数据I/O、寻址I/O等等。这样做的好处是一来可以降低Atom的营销成 本,二来是以后想为核心增删特性比较方便。
双模式FSB、核心频率与性能预览
双模式FXB
Atom是通过 quad-pumped FSB进行数据交换,这个与 Intel在其他处理器产品使用的方式是一样的,这显示会有功耗限制。根据不同的功耗状态以及性能需求,FSB频率运行于533MHz 或 400MHz。

Intel的FSB(前端总线Front Side Buses的Gunning Transistor-Logic (GTL),它能够提供高达1600MHz的高速,是高性能CPU的“最佳伴侣”,不过对于Atom来说则有点大材小用。尽管如此,Intel仍让 Atom同时支持GTL 或 CMOS两种FSB,在CMOS模式下,处理器的功耗将会显著降低,其所需的电压只有GTL模式下的一半。但速度方面都是一样的,Intel之所以保留两 种FSB只是为芯片组的兼容性跟功耗着想。
Poulsbo(与Atom配合推出的芯片组)支持CMOS模式,所以两者搭配的平台可以运行在节能的CMOS FSB模式上。但并不是说Atom只能搭配Poulsbo,Diamondville(面向廉价台式系统跟笔记本系统的Atom)支持GTL,普通芯片组 可以支持。
虽然第一代的Atom是单核产品,但其架构同样适合多核CPU产品。预计下半年推出的Diamondville就是一款双核Atom,它的个核心将共享一个FSB,具有内置内存控制器,预计性能将非常不错。
性能预览
下图是早期Atom与ARM11核心在Webpage Render中的性能对比:
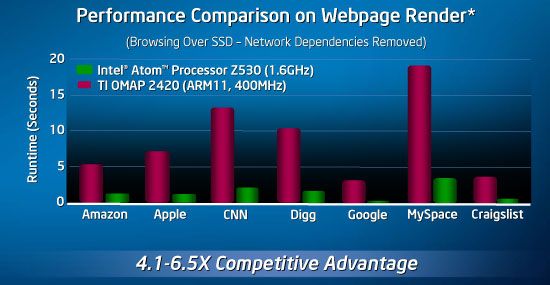
就Intel提供的数据来看,Atom的性能大概是iPhone ARM 11 CPU性能的2倍左右,优势相当突出。不过Intel仅仅只是突出了自己的性能优势,对于目前ARM CPU的功耗跟体积优势则避而不提。
Intel曾不止一次声称Atom的性能无论是在频率方面还是在执行性能方面将可以与第一代Pentium M处理器相比拼。以前我们没法验证这种说法的真实性,不过今天终于有机会一睹其真实表现。根据Intel公布的数据,1.6G的Atom在SYSMark 2004中的成绩大概比800MHz的奔腾M(90nm Dothan)快20%,而900MHz的Atom将不敌800MHz的奔腾M,显然只具备一个顺序执行的简单核心,Atom的性能需要高频率来弥补。
不过真正让人震撼的是Intel接下来UT2004即时DEMO演示!在这个演示中,Intel用一个安装了Vista的平台实际演示了Atom跑 UT2004的表现,结果不仅帧数顺畅,而且Atom在没有散热器的情况下表面温度只有35度左右!实在令人称赞!可以说这个UT2K4 DEMO真正让我折服,老实说在此之前之我个人对Atom平台还兴趣少少~~在这个散热器越来越夸张的年代,不需辅助散热的CPU几乎已经绝迹,如今随之 Atom的诞生,Intel有望让这种好风气再次复苏~~~

Poulsbo:不同寻常的革新芯片组
Poulsbo:不同寻常的革新芯片组
从2005年Intel就开始着手Poulsbo的设计工作,它跟Atom就好象一阴一阳,相辅相成。跟Atom一样,Poulsbo的设计也遵循低耗优于性能的原则。
Poulsbo的主设计师曾开发过i840芯片组,i840是RDRAM时代的优秀芯片组。Poulsbo完成设计那时候只有130nm制程,因此只能用130nm制程制造。从下面的图片可以清楚了解Poulsbo的体积跟Atom相比是多么的巨大!

Poulsbo是Intel从零开始的新设计,比较特别的是具备一个Intel叫做系统控制中心(System Controller Hub,SCH)的部件,为了节能,SATA之类的功能全被拿掉,USB口的数量也被削减。设计师用PATA代替SATA,虽然不工作的时候两者的功耗没 什么不同,但是一旦运转起来,SATA就要耗电得多。另外,FSB跟内存频率被锁定同步以节省能耗跟PLL,Poulsbo具备一个单通道 DDR2-400/533的内存控制器;支持HD audio内置音频规范的删减版,只能支持双声道。

Intel为Poulsbo准备了一个完善的内部数据传输机构,就好像是一个链接整个SCH的内部局域网,能够高效地在芯片组内部传送诸如中断、电源管理 等信号。相比传统芯片组,Poulsbo的FSB-mem通道显得非常简洁,内存控制器仅留下8KB的内存供FSB和内存做通信,这让北桥SCH部分的面 积只有传统芯片组北桥的20%。南桥方面同样逃不过被阉割的命运,所有在低功耗设备市场无用的功能全部都被拿掉,比如没有软驱控制器和并口。对 Poulsbo所做的阉割手术不仅缩小了体积,而且漏电的几率也降低了。
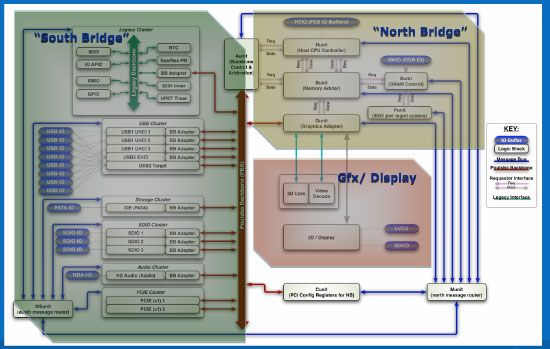
令人意外的是,Poulsbo还支持少有的1.5V DDR2内存,虽然1.5V并不是DDR2内存的官方电压,但很多显存制造商都推出了1.5V的低压版DDR2内存,因此如果OEM需要的话,随时可以在Poulsbo芯片组上实现为内存降压。
Poulsbo的图形芯片:PowerVR SGX
Poulsbo集成了PowerVR SGX图形芯片和VXD高清视频引擎,这个消息还是Imagination Technologies 刚刚放出来的,Intel一直不愿公开这张集成显卡的真实身份,只是声称看中了该芯片的低功耗跟高效性。使用其他公司的集成显卡对于Intel来说还是首 例,这对其“全球最大的整合显卡供应商”头衔实在是一种讽刺。
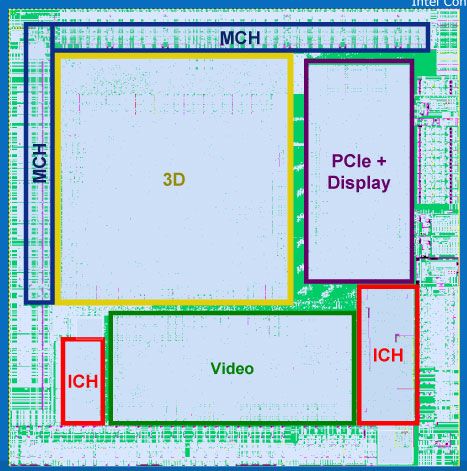
PowerVR SGX内置一个全高清解码引擎,能够对H.264、MPEG-2和VC-1等视频流加速。Intel声称该引擎能够解码全位率的蓝光电影,但实际上 PowerVR SGX无法通过蓝光设备的认证。按照Intel的说法,该图形芯片在做H.264解码时的功耗只有120mW。不过该显卡的输出分辨率存在不足,最高输出 分辨率只有1366×768,因此对于1080p的HD视频只能以较低的1366×768分辨率输出。
3D方面,PowerVR SGX据说支持DX9跟DX10,但目前第一版驱动只支持DX9L,不过像这种情况我们也不指望以后的驱动能有什么大的改进。虽然对于这样一个低功耗的平 台,GPU的性能显得有些无关紧要,不过Intel还是演示了UT 2004的即时DEMO,帧数还算顺畅。另外,Intel声称3D MARK 05能跑150分。
2D方面,Poulsbo使用Intel自己的2D技术。
Atom全家族成员预览
Atom全家族产品预览
Intel已经宣布今年将发布五款Atom产品
原本我们以为第一轮的Atom CPU最高频率只到1.6G,但现在看来Intel还想跑得更快,最高端的Atom频率已经达到1.86G,在这个频率下,其性能应该可以超过频率1G Pentium M,考虑到其功耗只有2.4W TDP,实在是相当不俗了!
Atom现在的主要问题是定价比预期偏高,虽然对于Atom所定位的UMPC跟MID市场而言,这个定价属于合理范围,但如果Intel想要普及x86,就必须进一步提高Atom的性价比才行。
Intel同时还发布了MID平台品牌:“迅驰Atom处理器技术”。Intel定义的“迅驰Atom处理器技术”(我们今后应当会简称为“迅驰 Atom”)即开发代号“Menlow”的超低功耗移动平台。整套平台包括Intel Atom处理器(Silverthorne和Diamondville)、低功耗“伴侣芯片”(内置图形核心、无线网络等)以及超薄超轻的设计,具体要求 看下图:

比迅驰更省电
在移动 Penryn处理器上,Intel引入新的功耗状态C6。在C6状态下,CPU进入休眠状态,其电压几乎为0。核心频率,所有的PLLs以及缓存基本上处于关闭状态。所有的数据都存储于10.5KB的空间内,这个与移动版Penryn相似。
很明显频率控制是属于Atom设计的一部分。Intel所有的处理器都使用了低功耗clock gating技术,但是相比而言Atom使用得更彻底一些,功耗差不多为0,这个与mobile Core 2有些相似。Atom内的每一个逻辑串(总共205个)都可以作为功能单元块 (FUB)使用,前面我们介绍过整个芯片都是Sea-of-FUBs设计。每一个FUB都能根据功耗的优化进和独立的关闭。同时Atom的缓存也拥有自己 的FUB,这个显然与移动版Core 2处理器是不一样的。

Intel表示Atom将会在90%的时间里保持在C6状态。不过这个数据会有些误导,因为当处理器处理完全待机状态时只能够保持在C6状态。90%的时间只有当相关产品放在口袋里不使用的情况下才有可能实现。在使用的时候,Atom将不可能保持在C6状态下。
Intel声称Atom的TDP控制在0.6W - 2.0W,这很明显要取决于核心频率。在 2.0GHz频率下,电压为1.0V,这时Atom处于90C 2W状态下。这时核 心的温度对于一些超小尺寸产品比如iPhone还会偏高,因此会更适合于类似于PSP这类产品上使用。但即使有C6技术助阵,Atom不论在工作还是闲置 状态下的功耗仍然高于ARM处理器。预计随着制造工艺的提升,未来Atom运行状态下的功耗将得到进一步降低,但闲置状态下的功耗控制则必须等到平台高度 整合之后才能做到,Intel的想法是用更加省电的总线规范代替PCI,让I/O端口只有在需要的时候才苏醒,据说这样一块电池可以播放数天音乐。

结语
结语
预计第一款采用Intel Atom处理器的产品会在未来半年内上市,Intel希望在今年内Atom能先登录5英寸大小的MID产品。对于MID这种产品,我个人觉得相比 UMPC(超级移动PC)没什么吸引人的特点,其界面操作反应迟钝、体积臃肿,实在想不出有什么理由整天随身带着这样一部东西~~另一个Intel想入侵 的市场就是便携式GPS设备。

现在Intel带领 x86几乎进入了每一个市场,而获得优势位置则需要遵循两个原则:生产工艺和X86兼容性。首先在生产这一块,Intel公司在这方面的优势已经保持很多 年了。因此在这一块,对于 Intel公司来说将不会有任何问题。目前ARM系列处理器的市场份额甚至要大于Intel桌面处理器,因此如果Atom的需求如预期那样发展的话,对于 Intel的经营来说将会产生重大影响。
对x86的兼容性将会是 Atom的杀手锏,这里我们需要再一次拿iPhone来举例。iPhone应该说是苹果公司旗下唯一一款非X86架构产品,由于基于的是OS X操作系统,从而使用iPhone的应用软件与基他产品完全区别开来。因此当32nm制程的 Atom成功推出之后,苹果公司将有可能在其第四代iPhone上得到应用,到那时苹果公司将可以拥抱X86架构软件。
不过目前ARM系列产品仍然是主流,因为暂时Atom还无法满足这些设备产品的综合需要,不过目前Atom肯定也能找到属于自己的空间。首先 Atom的推出只是为了完整Intel自己用于UMPC产品处理器的产品线,当然真正的革命是未来Atom全面入侵家电、日用电子产品等市场,而那才是我 所期盼看到的。
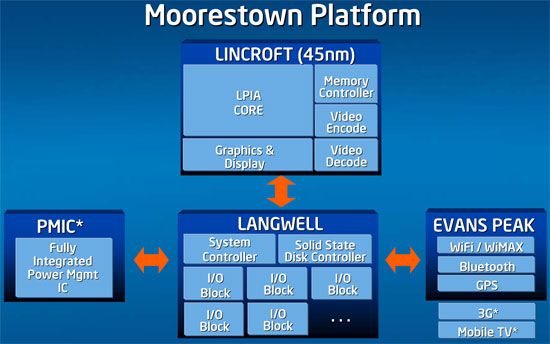
我个人认为,只有到了2011~2012年左右32nm的Moorestown面世后,我们才会看到Intel、ARM之间展开激烈的竞争,那时候我们才 有可能真正进入“x86一统江湖”的“太平盛世”:)如果现在就希望Atom可以在超便携计算领域带来当年Centrino带来nm的那种冲击的话,也许 你会感到失望。因为我们马上看到的还只是一场革命的开始,目前Atom至多就是为我们带来更多类似EeePC这样的产品,但目前对于Intel公司来说, 所有的一切还仍处于起步状态。而如果Intel成功了,那对于整个产业来说将会带来莫大的好处,像AMD这样的公司也将迅速推出相应的产品来抢夺利润,而 有了竞争的调节,最终我们才能用到物美价廉的产品。