小世界效应:从凯文·贝肯到六度分隔理论(1)
斯坦福的老师很喜欢用一些生活的小案例来引入课题,小的Project也不例外。
凯文·贝肯是好莱坞的大牌明星,这次Project也得从他说起。虽然贝肯在娱乐圈可谓呼风唤雨,人气也是相当的高,但他与奥斯卡的缘分却令人唏嘘。他的演艺生涯,不乏经典大片:Flatliners,The Air Up There,Footloose等等,但遗憾的是,一直未能捧获奥斯卡小金人。
时间回到1993年,当时还在读大学的Mike Ginelli、Craig Fass和Brain Turtle发明了一款有关凯文·贝肯的游戏,游戏的很简单,它能将任意的一位演艺界的明星用不超过6部电影与凯文·贝肯搭上关系,这也算是“六度分隔理论”的一个雏形。这款小游戏迅速在大众之中流行开来还得归功于Jon Stewart,他在电视秀中让大家第一次接触到了这样一款“神奇”的游戏。这样的游戏也引发了人们对于关系的进一步思考,世界在这套理论体系之下是如此的小。
你可以在开始项目前先感受一下在线版本: http://oracleofbacon.org/
具体玩法:
你说出两个明星的名字,你的朋友需要用少于6部电影将两位明星联系起来。
例如:你说A和B
你朋友得出以下的回答:
A和C同时出演了XXX那部电影
C和D同时出演了XXXX那部电影
D和B同时出演了X那部电影
于是A和B仅仅用了三部电影就联系起来了。
如果看到这儿还没有明白,请还是先去体验下在线版本。
概览:
目前,我能告诉大家的是,我们整个项目可以具体分为两块:
你需要实现imdb这样一个类,这个类的主要作用是能让你快速查找到某一部电影里面参演的所有演员信息以及某一位演员参演的所有影片信息。目前看来,我们好像可以直接使用stl模板中的map来实现,具体可以实例化两个map:一个用于某演员映射到所有电影,另一个用于某电影映射到所有演员。但细想下来,光从几兆的文本文件中读取这些信息就得花费很多时间,更要命的是,类型的识别也需要花费几分钟的时间,反正没人会愿意坐在电脑面前干等着,难道不是吗?所以这时候就需要大家开动脑袋瓜子,用我们的扎实的内存管理与数据结构的知识去处理这样子的数据,让我们的程序能够尽可能快的读取演员以及电影的信息。大家可以稍加思考,这个是本次项目的一个重点问题,不过大家放心,我会在后面实现 (*^__^*)
Imdb:全称Internet Movie Database
在完成第一步后,我们同时需要实现一个广度优先的搜索算法,通过算法可以找到两位演员的最短关系路径,当然这也得依靠上一步你设计的优秀数据结构啦。当然,我们事先也可以估摸一下,如果算法跑了一会儿,然后发现关系路径的长度已经大于6了,那么可以认定这两位是不可能联系在一块的啦。这部门的内容可能需要你对CS106B这套课程掌握的比较好,当然也没关系,这部分也能让不熟悉前面知识的同学重新温习下STL,这里面也会集中体现出C++作为“高层次”语言在模板以及面向对象上的优势,同时C作为“低级”语言,在内存管理以及面向过程上的优点也将发挥的淋漓尽致。敬请期待吧。
任务1:实现imdb类
首先,整个项目的落脚点是imdb类细致处理、实现。下面是已经实现了接口:
struct film{
string title;
int year;
};
class imdb{
public:
imdb(const string& directory);
bool getCredits(const string& player,vector
bool getCast(const film& movie,vector
~imdb();
private:
const void *actorFile;
const void *movieFile;
};
由于我在初始化actorFile与movieFile时需要预先处理大量的原始数据,期间使用了一些比较不常见的UNIX方法,所以整个类的构造函数与析构函数已经为你实现了,你不需要操心这部分的工作。值得高兴的是,构造函数和析构函数的复杂度都为O(1),这也正是我们想要的,: )
我们现在需要关注的工作是实现getCredits与getCast这两个方法,它们的只要功能是从数据中分类出演员与电影的信息用于填充films和players这两个vector数据。如果能够按照预期的那样实现,那么这两个方法将会带来飞速的查询速度。
整个项目的前提是数据不需要大家操心,但为了能更好的实现上面的两个方法,接下来的部分会给大家详细介绍这些数据是如何存储的,以便于大家能自如的操作它们。
数据存储方式:
现在我们知道actorFile与movieFile这两个字段都将占用大量的内存空间,它们均提取至相互关联的数据集合,它们的数据形式将在下面作详细说明。首先声明的是imdb的构造函数内部已经为我们初始化了这两个指针,所以我们只需要关注具体的实现。
为了简明起见,我们假设好莱坞发行了三部电影,并且这三部电影还是由三个固定的演员随机组合主演的。下面是假设情况:
Clerks 在 1993 年主演了 Cher 和Liberace
Monnstruck 在 1988 年主演了 Cher、Liberace 和 Madonna
Zoolander 在 1999 年主演了 Liberace 和 Madonna
当然,大家不要太过纠结于这里的一些逻辑错误,我们仅仅是为了展示做了些很没节操的假设而已。
如上所示,你可以发挥一下想象力,我已经实现好的构造函数会将actorFile于movieFile初始化成如下的样子:

但是问题也是显而易见,这样的格式会造成很低的利用率。无论是演员信息还是电影信息,它们的数据大小都是不可预估的。有些电影的名字远远长于其他电影,有些电影光参演的演员就有75人,而有些电影则只有少量演员。演员之间也是千差万别,有些是名副其实的多产户,有些仅仅有几部作品。看来仅仅通过定义一个结构体或类是解决不了数据内存分配的问题的,这样做很明显会造成大量的内存空间浪费。
但,如果我们采用了可变大小的内存分配方式,二分搜索法可能就不能在这里施展魔力了。试想一下,演员总数超过了300000,电影总数超过了124000,在这种情况下使用线性搜索是非常低效的。但假如所有的演员和电影都按照名字排好序,并且同名的电影可以按照年份排序,那么二分搜索仍然能够被采用。所以在这样一种意念的驱动下,我将数据的格式变成了下面这样:

可以看到,在记录数目与记录数据中间是一个记录偏移量的数组。图中它们被画成了指针,实际上并非如此。设计之初的愿景是能为记录的数据灵活的分配内存大小---这也直接衍生出了现在这样的解决方案:我们希望actorFile和movieFile所指向的数据能够更易于操作,它们具体存在什么地方,我们是不关心的。通过存储偏移量,我们可以分别手动的计算出Cher、Madonna和Clerk的记录位置,方法就是在actorFile和movieFile的实际存储位置上加上它们各自的偏移量。为了更形象的展示出来,请看下方的图:

按照如图所示的表示方法,我们可以很容易的得出:
Cher有16字节的数据并且偏移量为16
Liberace有24字节的数据并且偏移量为32
Moonstruck有28字节的数据并且偏移量为36
这里的数据大小可以根据之后数组单项的的偏移量与当前数组单项的偏移量之差得出。
由于偏移量是由四字节的整型数据构成的,加之数据本身的索引也被排好序,因此二分搜索法在这儿依然适用。
总结:
actorFile指向了一大块装载着所有演员信息的内存块,最开始的四个字节存储的是演员的总数,接下来的四字节存储的是第0号演员的数据偏移量,紧接着是第1个,第2个,第3个,以此类推。最后一个存储偏移量值的四字节之后跟着的是第0号演员的信息记录实际数据,紧接着是第1个、第2个等等。目前看来,尽管演员的名字长度不同,存储的大小也不同,但它们被按照名字做了排序。
movieFile也指向了一大块内存,它存储的是所有电影的信息。最开始的四个字节存储的是电影的总数,接下来的格式与actorFile类似。这些电影会按照名字进行排序,当然相同名字的电影会按照年份排序。
上面描述了拥有300000演员信息以及100000电影信息的文件存储方式,这样的做法同样适用于其他不同大小的数据。
演员信息记录:
演员信息记录存储的是他的基本信息以及他所参演电影的信息,在这里我们也没有适用任何形式的结构体或类,因为这样做同样会将所有演员的信息记录大小限定为一个值。所以我们将与该演员相关的信息全部存储在一块连续的内存空间里,这块内存的大小取决于演员的名字长度以及他所参演电影的个数。下面是关于此种方式的详细描述:
演员的名字如常规的C字符串那样,是按照一个个字符的形式被存储进去的。如果演员名字长度为偶数,那么在它之后会被强行插入额外的一个字符:’\0’。原因在于演员名字后面跟着信息很容易被系统看作一个短整型的数据,事实上所有硬件都将被操作的地址看作指向短整型数据的指针。
演员参演电影个数被存储在两字节大小的内存中(原因在于有些演员参演的电影数目远远多于255,所以一个字节很有可能不够用)。如果此时用于存储演员名字的字节数(总是偶数)与存储电影数目的字节数(总是2)之和不能被4整出,那么在这之后需要被额外的加上两个’\0’,这样整体就可以看做多个地址了。
紧接着的就是movieFile数据的偏移量数组,每个偏移量都代表了一个演员参演的电影信息。
下面是Cher记录的示例:
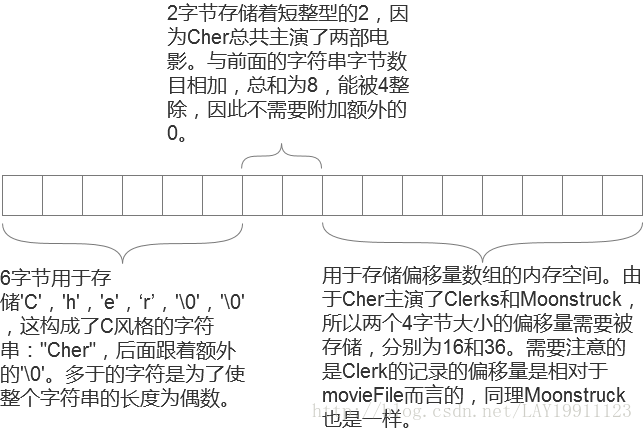
电影信息记录:
电影信息记录较之前者可能更复杂些,它的信息将会按如下规则被压缩:
电影的名字后面会加跟一个’\0’字符,以使它转换成一个常规的C语言风格的字符串。
电影发行的年份被存储在单字节中,由于好莱坞的历史还不超过2的8次方,所以,该字节实际存储的是它离1900年的偏移量。如果名字信息与年份信息的字节总数是奇数,那么它们与实际数据之间会增加一个’\0’字符。
接下来会有一个两字节大小的短整型用于存储该部电影中演员的个数,如果有必要的话,之后需要附加两个存储着0的字节。
最后就是偏移量数组,每个偏移量都对应着一个演员的actorFile数据。显而易见的是,这个数组的大小和步骤三那个短整型所存储的数值大小肯定是一样的。
需要注意的是:有些电影名字相同但它们实际上是不一样的电影(例如:Manchurian Candidate这部电影,首次发行是在1962年,但在2004时又被翻拍了,因此它们理应是不同的电影)。如果你已经看过文件夹中imdb-utils.h那个文件的话,你应该会看到film结构体内部实现了<和==的运算符重载。这样的话两部电影就可以通过运算符进行对比,从而进行分类。当然在本次课题中,你也只能通过film提供的运算符重载方法进行同名电影的分类。同样,你需要知道的是movieData数据集也遵守<运算符规则。
你不需要过多的关注如何实现搜索算法,最好事先独立完成imdb类的代码工作。我在这儿也提供了一个已经写好的测试程序:imdb-test.cc。运行该程序,它会自行测试你实现的imdb类是否足够稳定。我同时还提供了基于solaris和linux的两个不同版本的可执行测试案例,你可以将它们与你自己编写的测试案例进行对比。
实现任务1:
下面我列出了在实现imdb时需要的所有文件信息:
imdb-utils.h 该文件包含了film结构体的定义以及一个用于查找数据文件的内联方法。你最好不要对该文件进行大的改动。
imdb.h 这里面包含了imdb的一些基本接口信息,同样最好不要进行更改。当然你对私有字段有自己独到的看法,你也可以自行更改。
imdb.cc 这里面有构造函数、析构函数以及其它一些方法的实现细节。你的主要工作就是在这里实现getCredits与getCast方法。
imdb-test.cc 这是额外提供的单元测试代码,你可以用它测试你写的imdb类是否符合要求。
makefile 这个我就不解释,不懂的自行google。
今天这篇属于长文了,快接近5000字了,接下来就先简短的讲下做法:
bool imdb::getCredits(const string& player, vector
bool imdb::getCast(const film& movie, vector
在imdb.cc中实现两个方法,getCredits是传入一名演员的名字,然后将所有该演员主演的电影信息存到films中,getCast就是传入电影名,得到所有参演演员信息。
分析getCredits的实现(getCast与之类似):
利用已有的条件,构造函数会将actorFile初始化好,因此由*(int *)actorFile可以得到演员信息的记录总数目,然后对这么多的数据进行遍历,例如遍历到第n项时(假设for循环从1开始):
1、*(int *)(actorFile + n*4)这个可以得到偏移量的值
2、*(int *)(actorFile + (n+1)*4) - *(int *)(actorFile + n*4)这个得到的是第n项所代表的演员存储的记录数据大小
3、一个个字符读取直到读到’\0’,然后将读到的字符串与演员名字进行核对,不对就继续遍历,跳回1
4、如果结果是这名演员的信息,这里面得看演员的名字是不是奇数了,是奇数,直接往后读两字节,是偶数,就跳过一字节,然后读取两字节,这两字节就是前面介绍的偏移量数组,这些偏移量是相对于movieFile而言的(一定要记住),接下来就好办了,直接拿着偏移量就去取数据,这个复杂度为O(1),前面所说的快速取到数据也就是指的这个。
5、取数据,偏移量+movieFile地址就是数据的地址,根据上文所介绍的movie记录的数据格式,顺序依次为:
电影名字年份偏移值参演演员数目参演演员记录偏移量(相对于actorFile),我们在这需要的就是前两个值,取出来包装如film,然后再存入films即可,大功告成。
getCast基本也是一样的流程,具体的实现可能会遇到各种各样的bug,但相信自己,慢慢改。
关于六度分隔理论项目的第一部分难题就完成了,代码就不像之前那样事先贴出来,计划在发布完第二篇关于搜索的长文后再放源码。
特别的:请尽量在linux系列的操作系统中完成本次项目,不然就只能看着呵呵了。装个虚拟机啥的也不难吧。
本次课程需要文件已上传至百度网盘,自行下载:
http://pan.baidu.com/share/link?shareid=989138234&uk=3844400595
说明:
1、刚刚又校对了下整个稿子,前面有一段关于添加’\0’这个细节,不知道大家懂不懂,这是关于内存对齐那方面的知识,不知道有没有必要在后续的短文中提一下,有需求的话就留言。
2、大家尽量在中秋节前完成任务,不然搜索我觉得你会跟不上的,多google或直接留言给我(任何关于这个项目的问题)
3、每次都要进行的版权声明:本文取材至CS107,大家多去听听那位教授的课,很不错的。然后教材《计算机程序的构造与解释》和课外读物《七周七语言》,极力推荐看看。
THX ☺
//我的联系方式
===只做最真实的自己===
微信公共号IT百问
关注方式:
1、打开微信搜索微信号ID:itbaiwen
2、或者扫描下方的二维码
