python下载某网站收费文档(一)——配合fiddler半自动版
【背景】
一朋友颇感中年危机,今年抓紧时间充电,各种恶补,但是发现很多网站上的资料都是收费的,问我能不能下载下载。本着能帮朋友解决问题,同时练习技术的目的,就答应尝试写下。
【目标】
下载http://ishare.iask.sina.com.cn/f/o4jdhVGuL.html里的文章。
【思路】
打开网页看了下,发现里面其实存在的就是ppt的图片,那就好办了。
【思路一】【失败】
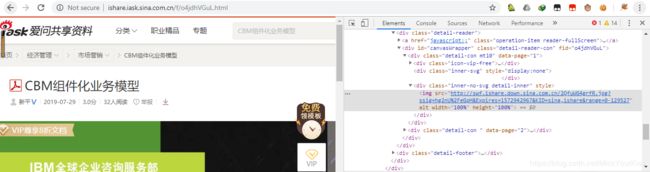
1、跟之前写的网页爬虫类似,打开网页,通过chrome获得html;
2、解析html结果,获得img的地址;
3、然后调用img的地址链接,下载下来即可。
>>通过chrome解析,拿到第一个图片的url:http://swf.ishare.down.sina.com.cn/2QfuWG4grfR.jpg?ssig=hg2nU%2FeGpH&Expires=1572942967&KID=sina,ishare&range=0-129527%20HTTP/1.1
>>直接访问,提示下载失败,文件不存在。
![]()
【思路二】【成功】
1、网页上能查看,但是直接访问报错文件不存在,猜想应该是需要加载一些cookie信息;
2、使用fiddler抓包,手动获取cookie、user-agent等header信息;
3、再次调用img下载,则成功。
【工具】
1、fiddler抓包工具
2、python3.7及对应的包requests、re
【编码】
1、标准头和包
# _*_ coding:utf-8 _*_
import requests
import re2、组装header、下载文章图片
def get_one_page(url):
headers = {}
headers['Host']='swf.ishare.down.sina.com.cn'
headers['Connection']='keep-alive'
headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
headers['Accept']='image/webp,image/apng,image/*,*/*;q=0.8'
headers['Referer']='http://ishare.iask.sina.com.cn/f/o4jdhVGuL.html'
headers['Accept-Encoding']='gzip, deflate'
headers['Accept-Language']='en-US,en;q=0.9'
headers['Cookie']=r'SINAGLOBAL=221.223.117.4_1492264815.415897; U_TRS1=00000012.4bf36eb8.58f4250b.4f9d2b6c; UOR=,blog.sina.com.cn,; SUB=_2AkMrrXGDf8NxqwJRmPAcxW7kaIlyzg7EieKd8YBYJRMyHRl-yD9jqlY7tRB6AC1fbEz_nU7bopPPzULzRNToKY76mLdO; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFzACV9p2oHrBaDRdCNPyyI; ULV=1567475728966:10:1:1::1559786471933; UM_distinctid=16cf4d5c6794d6-07f91cb3dcbdb3-a7f1a3e-100200-16cf4d5c67a3eb; lxlrttp=1560672234; gr_user_id=7517802c-37d8-41ee-aeea-481ff5d07cf0; grwng_uid=db5d7d1e-dd1b-4e4f-a5a7-15d2318b9875; 9f367e704cdcd7bc_gr_session_id=00d5888d-0183-4f70-96d3-2af91d738468; 9f367e704cdcd7bc_gr_session_id_00d5888d-0183-4f70-96d3-2af91d738468=true'
r_url = "http://" + headers['Host'] + url
resp = requests.get(r_url,headers = headers,proxies=None)
resp_code = [200,206]
img_name = re.findall("([0-9]+\-[0-9]+)",url)[0]
if resp.status_code in resp_code:
with open("tmp/"+img_name+".jpg","wb") as f:
f.write(resp.content)3、调用并下载
get_one_page('/2QfuWG4grfR.jpg?ssig=hg2nU%2FeGpH&Expires=1572942967&KID=sina,ishare&range=0-129527 HTTP/1.1')
get_one_page('/2QfuWG4grfR.jpg?ssig=hg2nU%2FeGpH&Expires=1572942967&KID=sina,ishare&range=129529-204810 HTTP/1.1')【完整代码】
感觉这种方法比较蠢,不像一个程序员的风格,就只下了前两张图片。下一篇将会使用全自动版。
# _*_ coding:utf-8 _*_
import requests
import re
def get_one_page(url):
headers = {}
headers['Host']='swf.ishare.down.sina.com.cn'
headers['Connection']='keep-alive'
headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
headers['Accept']='image/webp,image/apng,image/*,*/*;q=0.8'
headers['Referer']='http://ishare.iask.sina.com.cn/f/o4jdhVGuL.html'
headers['Accept-Encoding']='gzip, deflate'
headers['Accept-Language']='en-US,en;q=0.9'
headers['Cookie']=r'SINAGLOBAL=221.223.117.4_1492264815.415897; U_TRS1=00000012.4bf36eb8.58f4250b.4f9d2b6c; UOR=,blog.sina.com.cn,; SUB=_2AkMrrXGDf8NxqwJRmPAcxW7kaIlyzg7EieKd8YBYJRMyHRl-yD9jqlY7tRB6AC1fbEz_nU7bopPPzULzRNToKY76mLdO; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFzACV9p2oHrBaDRdCNPyyI; ULV=1567475728966:10:1:1::1559786471933; UM_distinctid=16cf4d5c6794d6-07f91cb3dcbdb3-a7f1a3e-100200-16cf4d5c67a3eb; lxlrttp=1560672234; gr_user_id=7517802c-37d8-41ee-aeea-481ff5d07cf0; grwng_uid=db5d7d1e-dd1b-4e4f-a5a7-15d2318b9875; 9f367e704cdcd7bc_gr_session_id=00d5888d-0183-4f70-96d3-2af91d738468; 9f367e704cdcd7bc_gr_session_id_00d5888d-0183-4f70-96d3-2af91d738468=true'
r_url = "http://" + headers['Host'] + url
resp = requests.get(r_url,headers = headers,proxies=None)
resp_code = [200,206]
img_name = re.findall("([0-9]+\-[0-9]+)",url)[0]
if resp.status_code in resp_code:
with open("tmp/"+img_name+".jpg","wb") as f:
f.write(resp.content)
get_one_page('/2QfuWG4grfR.jpg?ssig=hg2nU%2FeGpH&Expires=1572942967&KID=sina,ishare&range=0-129527 HTTP/1.1')
get_one_page('/2QfuWG4grfR.jpg?ssig=hg2nU%2FeGpH&Expires=1572942967&KID=sina,ishare&range=129529-204810 HTTP/1.1')